首先看下mysql数据库发送和接受请求的整个流程
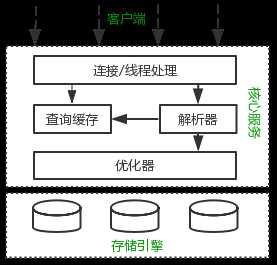
MySQL逻辑架构整体分为三层,最上层为客户端层,并非MySQL所独有,诸如:连接处理、授权认证、安全等功能均在这一层处理。
MySQL大多数核心服务均在中间这一层,包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)。所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
最下层为存储引擎,其负责MySQL中的数据存储和提取。和Linux下的文件系统类似,每种存储引擎都有其优势和劣势。中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异。
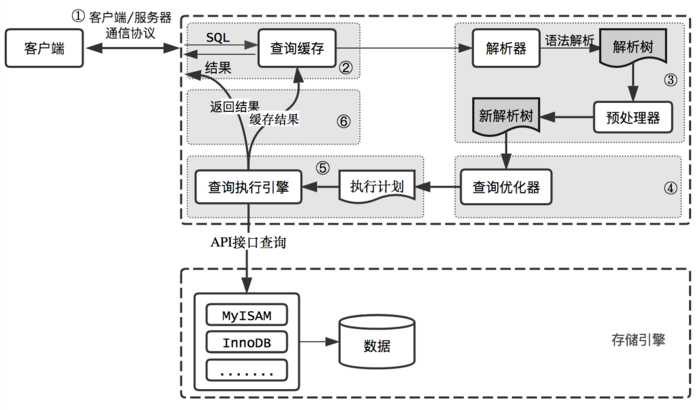
客户端/服务端通信协议
MySQL客户端/服务端通信协议是“半双工”的:在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生。一旦一端开始发送消息,另一端要接收完整个消息才能响应它,所以我们无法也无须将一个消息切成小块独立发送,也没有办法进行流量控制。
客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置max_allowed_packet参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
与之相反的是,服务器响应给用户的数据通常会很多,由多个数据包组成。但是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送。因而在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用SELECT *以及加上LIMIT限制的原因之一。
MySQL使用基于成本的优化器 在MySQL可以通过查询当前会话的last_query_cost的值来得到其计算当前查询的成本。
大表ALTER TABLE非常耗时,MySQL执行大部分修改表结果操作的方法是用新的结构创建一个张空表,从旧表中查出所有的数据插入新表,然后再删除旧表。
schema的列不要太多。原因是存储引擎的API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列,这个转换过程的代价是非常高的。如果列太多而实际使用的列又很少的话,有可能会导致CPU占用过高。
添加索引的时间肯定是远大于初始添加索引所需要的时间
[inner] join on/using
如果两个表的关联字段名是一样的,就可以使用Using来建立关系,简洁明了。如果不一样,只能用On了哦~
分页和where语句
select * from reader where id>5000;
select * from reader limit 5000,10;
分页会先将记录全部排序一遍,选取5000以后的十条数据量,而where条件表达式逐条查询,大于5000就抽出来,不需要先排序。
SELECT film_id,description FROM film ORDER BY title LIMIT 50,5;
当LIMIT的偏移量特别大的时候,就要采用分组来减少扫描的页面
让MySQL扫描尽可能少的页面,获取需要访问的记录后在根据关联列回原表查询所需要的列
SELECT film.film_id,film.description
FROM film INNER JOIN (
SELECT film_id FROM film ORDER BY title LIMIT 50,5
) AS tmp USING(film_id);