注意:都是在没有优化的情况下编译的。因为只要开-O1或是-O2,那么汇编代码就少的可怜了,都被优化掉了
编译器版本:x86-64 gcc 5.5
1 POD类型传参
1.1 一个pod参数,pod返回值
int square(int num) {
return num * num;
}
int main()
{
int c=90;
int a=square(c);
++a;
}
对应汇编

1.2 两个pod参数,pod返回值
int mul(int v1,int v2) {
return v1 * v2;
}
int main()
{
int c=90;
int a=mul(c,1);
++a;
}
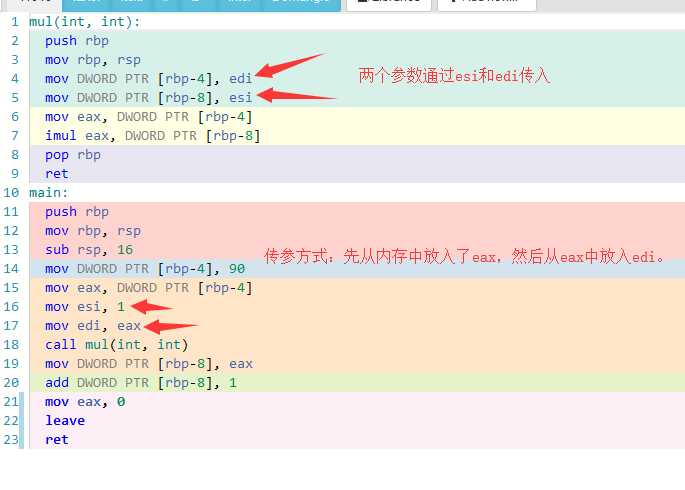
当第二个参数也传入变量的时候,会使用edx,像eax一样传入。然后返回值依然使用eax返回。
1.3 几个参数才会动用到栈传参,
int mul(int v1,int v2,int v3,int v4,int v5,int v6,int v7) {
return v1 * v2*v3*v4*v5*v6*v7;
}
int main()
{
int c1=90;
int c2=10;
int c3=10;
int c4=10;
int c5=10;
int c6=10;
int c7=10;
int a=mul(c1,c2,c3,c4,c5,c6,c7);
++a;
c1++;c2++;c3++;c4++;c5++;c6++;c7++;
a=mul(a,c2,c3,c4,c5,c6,c7);
}
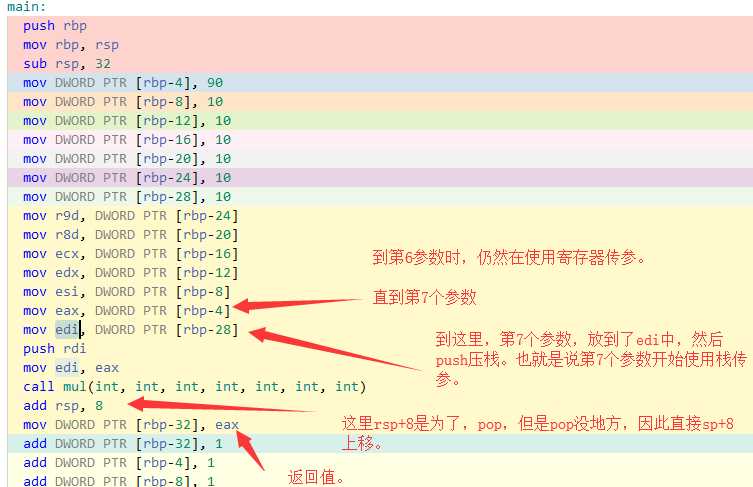
从上图可以看到,是从第7个参数开始,使用栈传递参数。
并且之前都是使用edi作为第一个参数,但是当使用栈的时候就使用edi来倒腾数据了。
注意,栈先回退,然后再去保存返回值
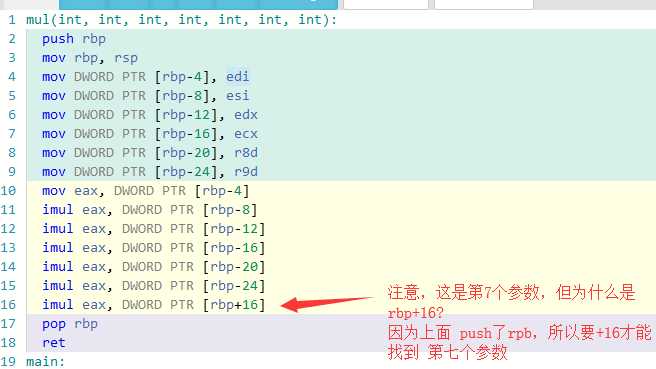
再看函数调用:
2 结构体传参
class A
{
public:
A()
:i1(1)
{}
public:
int i1;
char a;
int i2;
char ca;
char c1;
~A()
{
i2=2;
}
};
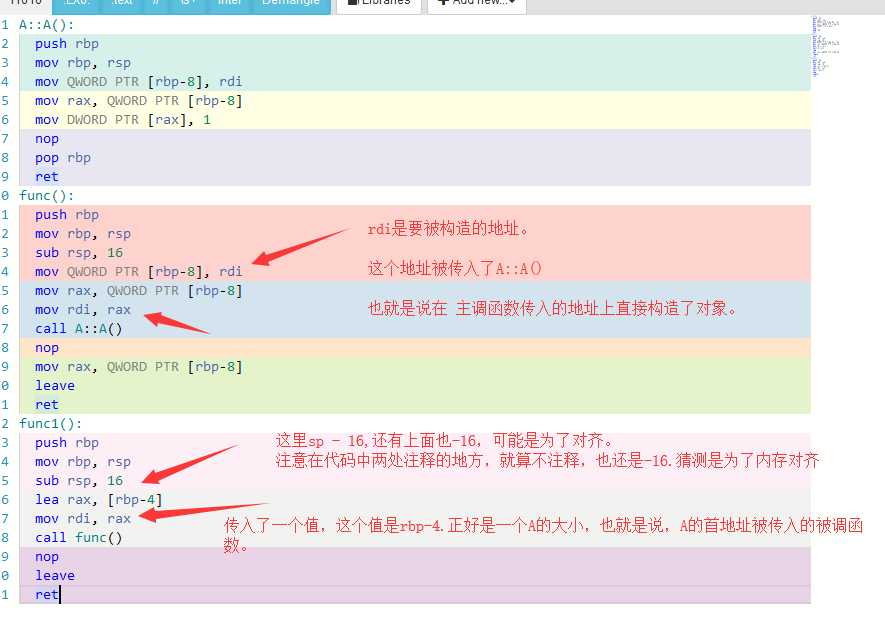
int func(A a1,A a2,A a3,A a4,A a5,A a6,A a7)
{
a1.a++;
return 1;
}
void func1(int i)
{
if(i<10)
{
i++;
A a1;
A a2;
A a3;
A a4;
A a5;
A a6;
A a7;
int a=func(a1,a2,a3,a4,a5,a6,a7);
// a1.a++;
// int bb=func(a1,a2,a3,a4,a5,a6);
// }else{
// return func1(i+1);
// }
}
}
先看func1函数
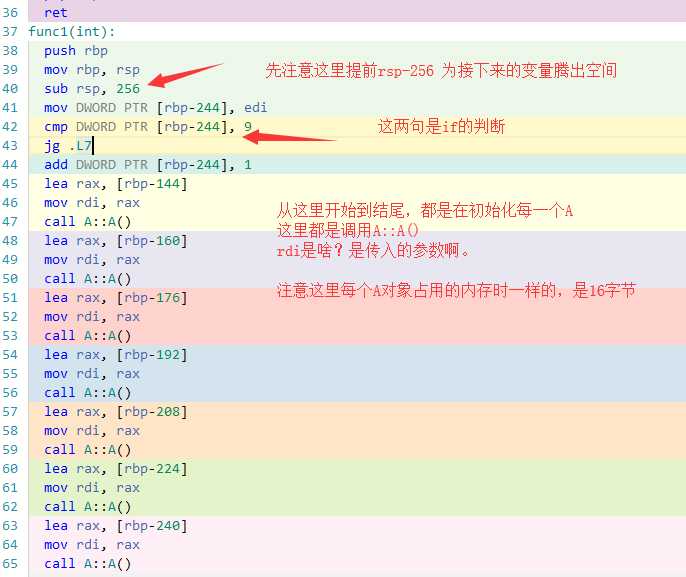
传参
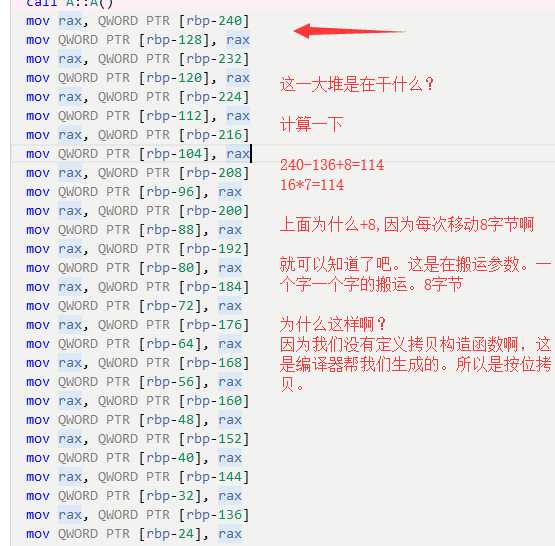
加上一个拷贝构造函数:
A(A& a)
{
ca=++a.ca;
}

然后看看拷贝构造函数的汇编:

对的。你有没有发现,对象a,也就是参数所在位置的内存,就只有ca成员被初始化了,也就是说被修改了。其他的数据成员都没有修改。
然后配合
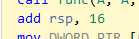
这种,栈指针回退的做法,是不是就能够明白。为什么说函数内部的变量,如果没有初始化,那么值是未定义的。而不是说0
因为,之前使用这块内存空间的函数,并没有将那块内存空间清0,而是直接sp+8这种形式退了回去。
因此后面函数再使用相同的内存,那么就是未定义啊!!!未定义啊!
明白是怎么来的了吗?
为啥说函数外的变量就不会这样。因为函数外变量占用的内存就不会被回收,也就不存在被重用。一定是0.它内部的内存一定是0啊~~(那如果是别的进程使用了内存那?操作系统可能会清0吧。这个就真不清楚了)
然后继续看函数调用
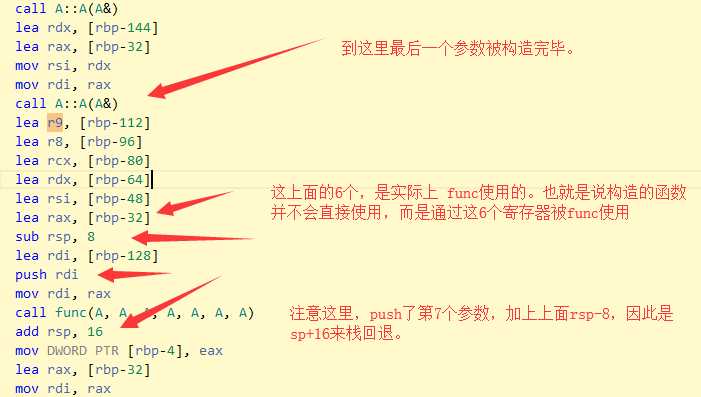
上面 为什么要 先 rsp -8 ,命名push 的时候可以自动的做到rsp-8。
这里为啥,我没想明白。但是当压入8个参数的时候,也就是说2个参数需要栈传参,那么会sp-8*2
再来看一下func函数。改一下,不然有些信息看不出来。
int func(A a1,A a2,A a3,A a4,A a5,A a6,A a7,A b)
{
b.a++;
a1.a++;
return 1;
}
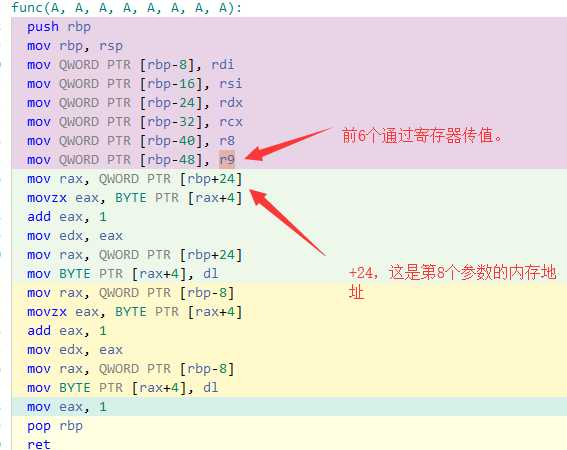
虽然编译器是gcc,但是因为有类,因此最终还是用的 g++ 来编译。
因此,从上面可以看出来了吧,其实参数构造的地方,是在栈上,但是函数实际使用的是 lea 指令取的参数的有效地址,然后保存在寄存器中,被调用函数通过寄存器访问参数。
也就是说,并不存在什么值传递。值传递的本意是参数使用拷贝构造函数复制了一份。然后取其有效地址通过寄存器传入了被调用函数
那拷贝一份的意义在哪?在于不会更改原来的变量的值。应为传入的参数是构造函数复制的那份。更改也无所谓。
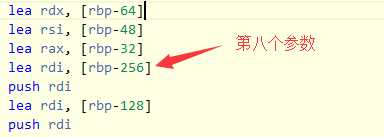
如果第8个参数改为指针传参会发生什么:
首先发生的变化就是,拷贝构造函数的调用少了一次,也就是说第8个参数没有被拷贝,但是第8个参数需要通过压栈传参了,因此可以发现,直接压栈第八个参数实际值的有效地址
2.2 结构体类型返回值
首先
class A
{
public:
A()
: i(1)
{
}
A(A& a)
{
}
int i;
// int i1;
// int i2;
};
A func()
{
A a;
return a;
}
void func1()
{
A b = func();
}
这段代码编译不通过:
为什么,因为sp指针在call结束以后直接回退,返回值的处理是在sp指针回退以后才开始进行的。
那也就是说,如果这段代码可以通过编译,那么就是说明,eax寄存器存储的是返回值的有效地址,而这个有效地址已经在sp指针之下了,也就是说不在栈内了。
换句话说,这个元素已经不可用了。既然已经不可用了,那怎么还能用一个不可用的变量来构造值??
其实问题是在于,这个值是非const传递的,a在栈回退以后是一个匿名变量了,也就是说是一个右值了。她已经不再栈上了(sp之下),因此也就是无法被修改了。
而拷贝构造函数,不可避免的会携带之前变量的一些值,也就是说,是可以修改原来的变量的。但是a已经是一个右值了,(其实是在sp之下了),无法被修改。因此编译器拒绝了这种构造。
但是如果改为
class A
{
public:
A()
: i(1)
{
}
A(const A &a)
{
}
int i;
// int i1;
// int i2;
};
A func()
{
A a;
return a;
}
void func1()
{
A b = func();
}
编译就可以通过,为什么。因为传入的是const A& 意味着使用这个值构造的对象,不会去修改这个值。或是说不能被修改。因此就可以使用这个值去构造其他对象了。
但是问题还是一个,a已经不再栈上了,怎么去构造?
答案是先预留出返回值的内存空间,然后将这个地址传入,在被调用函数中构造。
3 nop是什么
这个,没看完,不太懂。贴个链接吧。