标签:ati 方式 ram 更新 一个 分离 rmi 优点 ams
为什么是基于Spring的呢,因为实现方案基于Spring的事务以及AbstractRoutingDataSource(spring中的一个基础类,可以在其中放多个数据源,然后根据一些规则来确定当前需要使用哪个数据,既可以进行读写分离,也可以用来做分库分表)
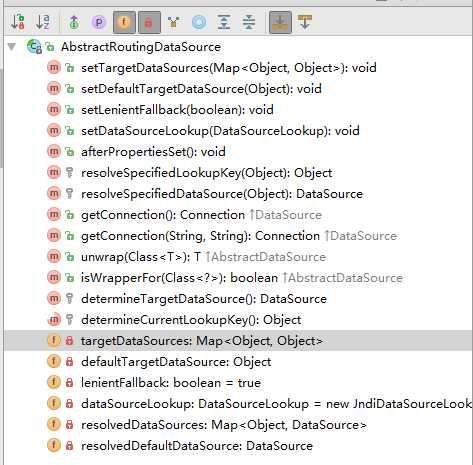
我们只需要实现
determineCurrentLookupKey()每次生成jdbc connection时,都会先调用该方法来甄选出实际需要使用的datasource,由于这个方法并没有参数,因此,最佳的方式是基于ThreadLocal变量
@Component
@Primary
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {
@Resource(name = "masterDs")
private DataSource masterDs;
@Resource(name = "slaveDs")
private DataSource slaveDs;
@Override
public void afterPropertiesSet() {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("slaveDs", slaveDs);
targetDataSources.put("masterDs", masterDs);
this.setTargetDataSources(targetDataSources);
this.setDefaultTargetDataSource(masterDs);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceHolder.contextHolder.get();
}
/**
* 持有当前线程所有数据源的程序
*/
public static class DynamicDataSourceHolder {
public static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
public static void setWrite() {
contextHolder.set("masterDs");
}
public static void setRead() {
contextHolder.set("slaveDs");
}
public static void remove() {
contextHolder.remove();
}
}
}以上代码,使用了ThreadLocal
/**
* Retrieve the current target DataSource. Determines the
* {@link #determineCurrentLookupKey() current lookup key}, performs
* a lookup in the {@link #setTargetDataSources targetDataSources} map,
* falls back to the specified
* {@link #setDefaultTargetDataSource default target DataSource} if necessary.
* @see #determineCurrentLookupKey()
*/
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}下一步,是在sql请求前,先对contextHolder赋值,手动赋值工作量很大,并且容易出错,也没有办法规范
实现方案是基于Aop,根据方法名,或者方法注解来区分
如果有特殊的业务,可以两种情况都使用,如以下场景:
我们将设置contextHolder的地方加在了dao层,出于以下考量:
当然,这不是最佳实践,如果在manager层做这个事,也是可以的,看具体的情况,要求是,名称或注解表意为query的方法,里面不能做任何更新操作,因为manager层已经确定了它会查从库,以下方法是会执行失败的
public class Manager1{
......
public List getSome(params){
dao1.getRecord1(params);
dao2.updateLog(params);
}
}
因为dao2是一个更新请求,使用从库进行更新,肯定是会失败的
(使用Spring Boot,或Spring时,需确保开启AspectJ,Spring Boot开启方式 @EnableAspectJAutoProxy(proxyTargetClass = true)
)
@Aspect
@Order(-10)
@Component
public class DataSourceAspect {
public static final Logger logger = LoggerFactory.getLogger(DataSourceAspect.class);
private static final String[] DefaultSlaveMethodStart
= new String[]{"query", "find", "get", "select", "count", "list"};
/**
* 切入点,所有的mapper pcakge下面的类的方法
*/
@Pointcut(value = "execution(* com.jd.xx.dao.mapper..*.*(..))")
@SuppressWarnings("all")
public void pointCutTransaction() {
}
/**
* 根据方法名称,判断是读还是写
* @param jp
*/
@Before("pointCutTransaction()")
public void doBefore(JoinPoint jp) {
String methodName = jp.getSignature().getName();
if (isReadReq(methodName)) {
DynamicRoutingDataSource.DynamicDataSourceHolder.setRead();
} else {
DynamicRoutingDataSource.DynamicDataSourceHolder.setWrite();
}
}
@After("pointCutTransaction()")
public void after(JoinPoint jp) {
DynamicRoutingDataSource.DynamicDataSourceHolder.remove();
}
/**
* 根据方法名,判断是否为读请求
*
* @param methodName
* @return
*/
private boolean isReadReq(String methodName) {
for (String start : DefaultSlaveMethodStart) {
if (methodName.startsWith(start)) {
return true;
}
}
return false;
}
}上面的代码,根据方法名称前缀,反向判断哪些方法应该使用从库,凡是不匹配的方法,都走主库
如此就完成了读写分离
标签:ati 方式 ram 更新 一个 分离 rmi 优点 ams
原文地址:https://www.cnblogs.com/windliu/p/8920467.html