标签:val 完整 pipe 动画片 rem 页面 conf something microsoft
前面几篇主要内容出自微软官方,经我特意修改的案例的文章:
相信看过后大家对ML.NET有了一定的了解了,由于目前还是0.1的版本,也没有更多官方示例放出来,大家普遍觉得提供的特性还不够强大,所以处在观望状态也是能理解的。
本文结合Azure提供的语音识别服务,向大家展示另一种ML.NET有趣的玩法——猜动画片台词。
这个场景特别容易想像,是一种你说我猜的游戏,我会事先用ML.NET对若干动画片的台词进行分类学习,然后使用麦克风,让使用者随便说一句动画片的台词(当然得是数据集中已存在的,没有的不要搞事情呀!),然后来预测出自哪一部。跟随我动手做做看。
这次需要使用Azure的认知服务中一项API——Speaker Recognition,目前还处于免费试用阶段,打开https://azure.microsoft.com/zh-cn/try/cognitive-services/?api=speaker-recognition,能看到如下页面:
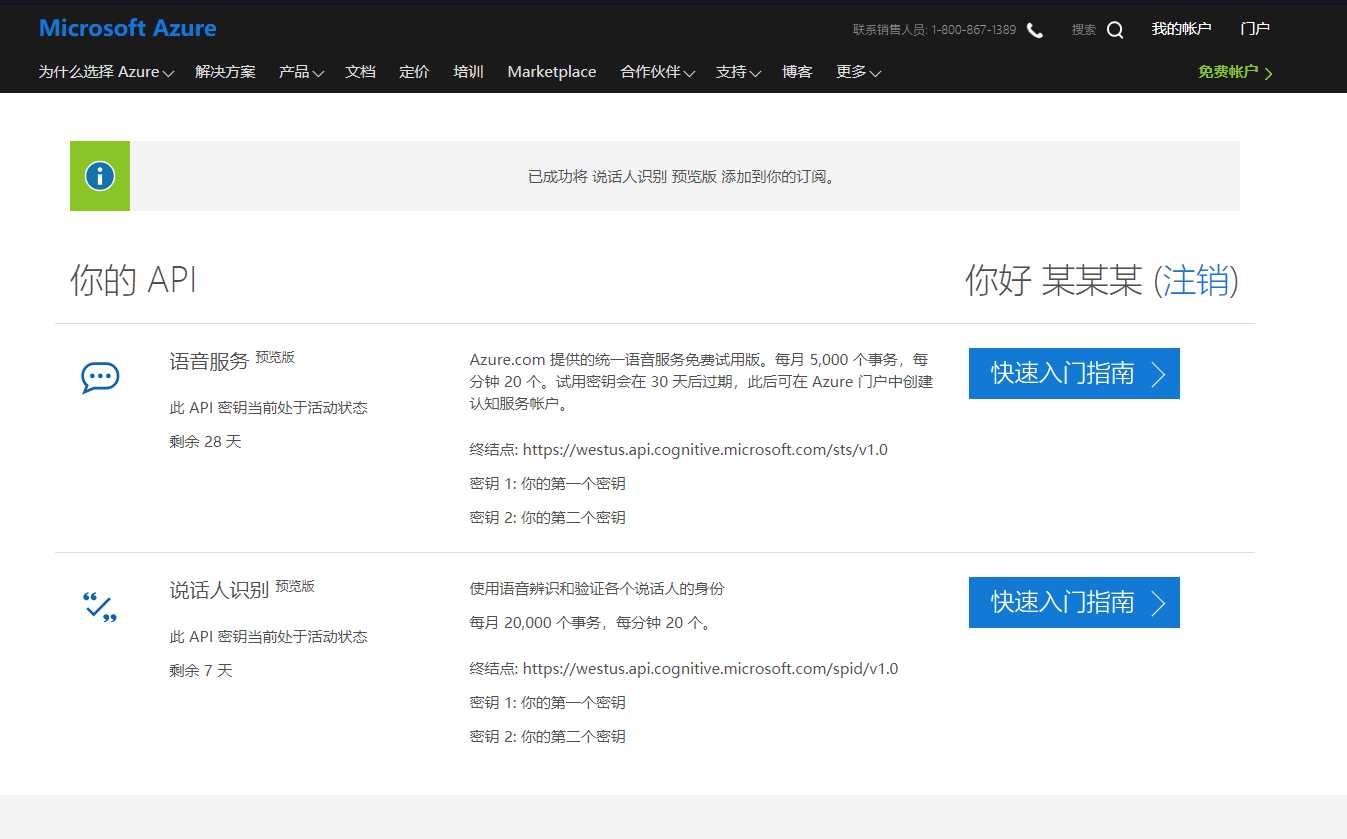
点击获取API密钥,用自己的Azure账号登录,然后就能看到自己的密钥了,类似如下图:
这一次请注意,我们要创建一个.NET Framework 4.6.1或以上版本的控制台应用程序,通过NuGet分别引用三个类库:Microsoft.ML,JiebaNet.Analyser,Microsoft.CognitiveServices.Speech。
然后把编译平台修改成x64,而不是Any CPU。(这一点非常重要)
在Main函数部分,我们只需要关心几个主要步骤,先切词,然后训练模型,最后在一个循环中等待使用者说话,用模型进行预测。
static void Main(string[] args) { Segment(_dataPath, _dataTrainPath); var model = Train(); Evaluate(model); ConsoleKeyInfo x; do { var speech = Recognize(); speech.Wait(); Predict(model, speech.Result); Console.WriteLine("\nRecognition done. Your Choice (0: Stop Any key to continue): "); x = Console.ReadKey(true); } while (x.Key != ConsoleKey.D0); }
初始化的变量主要就是训练数据,Azure语音识别密钥等。注意YourServiceRegion的值是“westus”,而不是网址。
const string SubscriptionKey = "你的密钥"; const string YourServiceRegion = "westus"; const string _dataPath = @".\data\dubs.txt"; const string _dataTrainPath = @".\data\dubs_result.txt";
定义数据结构和预测结构和我之前的文章一样,没有什么特别之处。
public class DubbingData { [Column(ordinal: "0")] public string DubbingText; [Column(ordinal: "1", name: "Label")] public string Label; } public class DubbingPrediction { [ColumnName("PredictedLabel")] public string PredictedLabel; }
切记部分注意对分隔符的过滤。
public static void Segment(string source, string result) { var segmenter = new JiebaSegmenter(); using (var reader = new StreamReader(source)) { using (var writer = new StreamWriter(result)) { while (true) { var line = reader.ReadLine(); if (string.IsNullOrWhiteSpace(line)) break; var parts = line.Split(new[] { ‘\t‘ }, StringSplitOptions.RemoveEmptyEntries); if (parts.Length != 2) continue; var segments = segmenter.Cut(parts[0]); writer.WriteLine("{0}\t{1}", string.Join(" ", segments), parts[1]); } } } }
训练部分依然使用熟悉的多分类训练器StochasticDualCoordinateAscentClassifier。TextFeaturizer用于对文本内容向量化处理。
public static PredictionModel<DubbingData, DubbingPrediction> Train() { var pipeline = new LearningPipeline(); pipeline.Add(new TextLoader<DubbingData>(_dataTrainPath, useHeader: false, separator: "tab")); pipeline.Add(new TextFeaturizer("Features", "DubbingText")); pipeline.Add(new Dictionarizer("Label")); pipeline.Add(new StochasticDualCoordinateAscentClassifier()); pipeline.Add(new PredictedLabelColumnOriginalValueConverter() { PredictedLabelColumn = "PredictedLabel" }); var model = pipeline.Train<DubbingData, DubbingPrediction>(); return model; }
验证部分这次重点是看损失程度分数。
public static void Evaluate(PredictionModel<DubbingData, DubbingPrediction> model) { var testData = new TextLoader<DubbingData>(_dataTrainPath, useHeader: false, separator: "tab"); var evaluator = new ClassificationEvaluator(); var metrics = evaluator.Evaluate(model, testData); Console.WriteLine(); Console.WriteLine("PredictionModel quality metrics evaluation"); Console.WriteLine("------------------------------------------"); //Console.WriteLine($"TopKAccuracy: {metrics.TopKAccuracy:P2}"); Console.WriteLine($"LogLoss: {metrics.LogLoss:P2}"); }
预测部分没有什么大变化,就是对中文交互进行了友好展示。
public static void Predict(PredictionModel<DubbingData, DubbingPrediction> model, string sentence) { IEnumerable<DubbingData> sentences = new[] { new DubbingData { DubbingText = sentence } }; var segmenter = new JiebaSegmenter(); foreach (var item in sentences) { item.DubbingText = string.Join(" ", segmenter.Cut(item.DubbingText)); } IEnumerable<DubbingPrediction> predictions = model.Predict(sentences); Console.WriteLine(); Console.WriteLine("Category Predictions"); Console.WriteLine("---------------------"); var sentencesAndPredictions = sentences.Zip(predictions, (sentiment, prediction) => (sentiment, prediction)); foreach (var item in sentencesAndPredictions) { Console.WriteLine($"台词: {item.sentiment.DubbingText.Replace(" ", string.Empty)} | 来自动画片: {item.prediction.PredictedLabel}"); } Console.WriteLine(); }
Azure语音识别的调用如下。
static async Task<string> Recognize() { var factory = SpeechFactory.FromSubscription(SubscriptionKey, YourServiceRegion); var lang = "zh-cn"; using (var recognizer = factory.CreateSpeechRecognizer(lang)) { Console.WriteLine("Say something..."); var result = await recognizer.RecognizeAsync().ConfigureAwait(false); if (result.RecognitionStatus != RecognitionStatus.Recognized) { Console.WriteLine($"There was an error. Status:{result.RecognitionStatus.ToString()}, Reason:{result.RecognitionFailureReason}"); return null; } else { Console.WriteLine($"We recognized: {result.RecognizedText}"); return result.RecognizedText; } } }
运行过程如下:
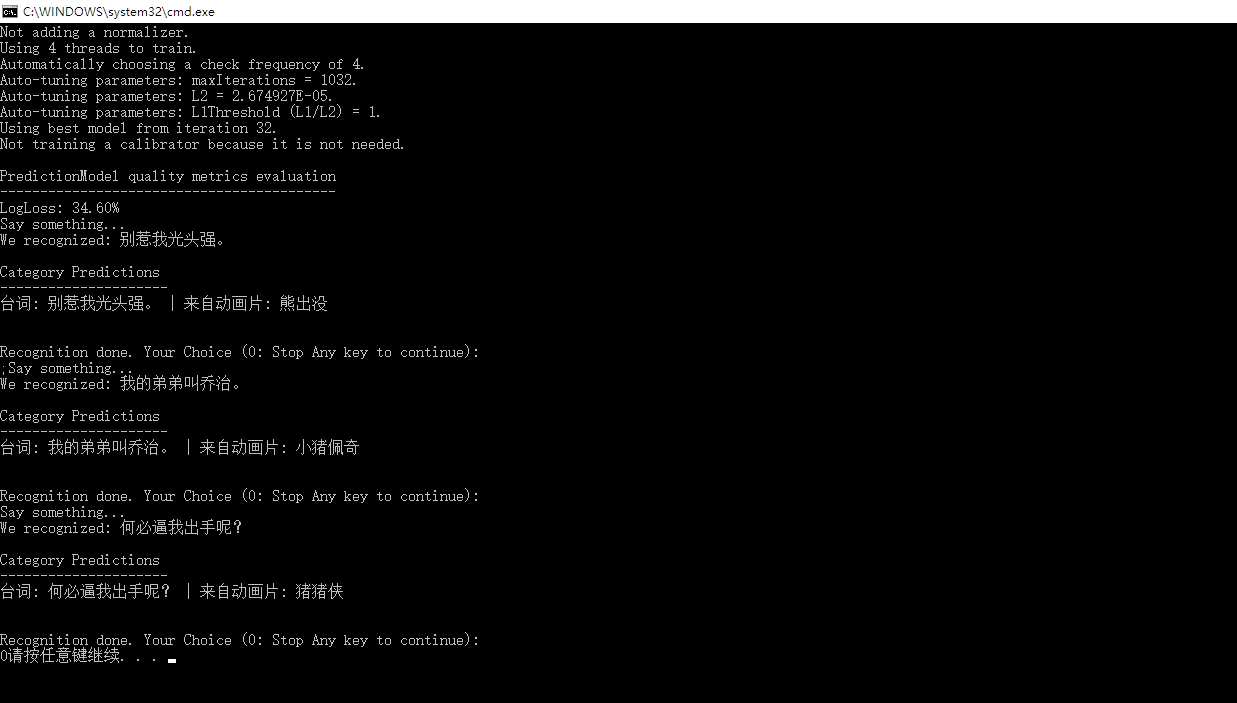
虽然这看上去有点幼稚,不过一样让你开心一笑了,不是么?请期待更多有趣的案例。
本文使用的数据集:下载
完整的代码如下:
using System; using Microsoft.ML.Models; using Microsoft.ML.Runtime; using Microsoft.ML.Runtime.Api; using Microsoft.ML.Trainers; using Microsoft.ML.Transforms; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using JiebaNet.Segmenter; using System.IO; using Microsoft.CognitiveServices.Speech; using System.Threading.Tasks; namespace DubbingRecognition { class Program { public class DubbingData { [Column(ordinal: "0")] public string DubbingText; [Column(ordinal: "1", name: "Label")] public string Label; } public class DubbingPrediction { [ColumnName("PredictedLabel")] public string PredictedLabel; } const string SubscriptionKey = "你的密钥"; const string YourServiceRegion = "westus"; const string _dataPath = @".\data\dubs.txt"; const string _dataTrainPath = @".\data\dubs_result.txt"; static void Main(string[] args) { Segment(_dataPath, _dataTrainPath); var model = Train(); Evaluate(model); ConsoleKeyInfo x; do { var speech = Recognize(); speech.Wait(); Predict(model, speech.Result); Console.WriteLine("\nRecognition done. Your Choice (0: Stop Any key to continue): "); x = Console.ReadKey(true); } while (x.Key != ConsoleKey.D0); } public static void Segment(string source, string result) { var segmenter = new JiebaSegmenter(); using (var reader = new StreamReader(source)) { using (var writer = new StreamWriter(result)) { while (true) { var line = reader.ReadLine(); if (string.IsNullOrWhiteSpace(line)) break; var parts = line.Split(new[] { ‘\t‘ }, StringSplitOptions.RemoveEmptyEntries); if (parts.Length != 2) continue; var segments = segmenter.Cut(parts[0]); writer.WriteLine("{0}\t{1}", string.Join(" ", segments), parts[1]); } } } } public static PredictionModel<DubbingData, DubbingPrediction> Train() { var pipeline = new LearningPipeline(); pipeline.Add(new TextLoader<DubbingData>(_dataTrainPath, useHeader: false, separator: "tab")); //pipeline.Add(new ColumnConcatenator("Features", "DubbingText")); pipeline.Add(new TextFeaturizer("Features", "DubbingText")); //pipeline.Add(new TextFeaturizer("Label", "Category")); pipeline.Add(new Dictionarizer("Label")); pipeline.Add(new StochasticDualCoordinateAscentClassifier()); pipeline.Add(new PredictedLabelColumnOriginalValueConverter() { PredictedLabelColumn = "PredictedLabel" }); var model = pipeline.Train<DubbingData, DubbingPrediction>(); return model; } public static void Evaluate(PredictionModel<DubbingData, DubbingPrediction> model) { var testData = new TextLoader<DubbingData>(_dataTrainPath, useHeader: false, separator: "tab"); var evaluator = new ClassificationEvaluator(); var metrics = evaluator.Evaluate(model, testData); Console.WriteLine(); Console.WriteLine("PredictionModel quality metrics evaluation"); Console.WriteLine("------------------------------------------"); //Console.WriteLine($"TopKAccuracy: {metrics.TopKAccuracy:P2}"); Console.WriteLine($"LogLoss: {metrics.LogLoss:P2}"); } public static void Predict(PredictionModel<DubbingData, DubbingPrediction> model, string sentence) { IEnumerable<DubbingData> sentences = new[] { new DubbingData { DubbingText = sentence } }; var segmenter = new JiebaSegmenter(); foreach (var item in sentences) { item.DubbingText = string.Join(" ", segmenter.Cut(item.DubbingText)); } IEnumerable<DubbingPrediction> predictions = model.Predict(sentences); Console.WriteLine(); Console.WriteLine("Category Predictions"); Console.WriteLine("---------------------"); var sentencesAndPredictions = sentences.Zip(predictions, (sentiment, prediction) => (sentiment, prediction)); foreach (var item in sentencesAndPredictions) { Console.WriteLine($"台词: {item.sentiment.DubbingText.Replace(" ", string.Empty)} | 来自动画片: {item.prediction.PredictedLabel}"); } Console.WriteLine(); } static async Task<string> Recognize() { var factory = SpeechFactory.FromSubscription(SubscriptionKey, YourServiceRegion); var lang = "zh-cn"; using (var recognizer = factory.CreateSpeechRecognizer(lang)) { Console.WriteLine("Say something..."); var result = await recognizer.RecognizeAsync().ConfigureAwait(false); if (result.RecognitionStatus != RecognitionStatus.Recognized) { Console.WriteLine($"There was an error. Status:{result.RecognitionStatus.ToString()}, Reason:{result.RecognitionFailureReason}"); return null; } else { Console.WriteLine($"We recognized: {result.RecognizedText}"); return result.RecognizedText; } } } } }
标签:val 完整 pipe 动画片 rem 页面 conf something microsoft
原文地址:https://www.cnblogs.com/BeanHsiang/p/9052751.html