ICCV 2017
Fast Image Processing with Fully-Convolutional Networks
作者想建立一个神经网络模型去近似一些图像里的操作,比如图像风格迁移,图像铅笔画,去雾,上色,增加细节等等。主要考虑三个方面,近似的精度、运行时间、内存占用多少。
作者想用一个模型来拟合十种图像操作。
All operators are approximated using an identical architecture with no hyperparameter tuning.
已经有很多中,图片处理的加速算法,比如中值滤波器等等,但是他们的问题没有一般性。有一般性的是上面提到的下采样方法。
整个网络是Context aggregation networks(CAN),核心就是:
\[ L_i^s = \phi\left ( \psi^s(b_i^s+\sum_jL_j^{s-1}*_{r_s}K_{i,j}^s) \right) \]
其中,\(L_i^s\)是\(s\)层\(L^s\)的第\(i\)个特征层,\(*_{r_s}\)代表空洞卷积操作,\(K_{i,j}^s\)代表3X3的卷积核,\(b_i^s\)是偏置项,$ \psi^s\(是自适应的归一化函数,\) \phi$ 是像素级的非线性单元LReLU:\(\phi(x) = max(\alpha x,x)\) 。其中\(\alpha\)取的是0.2。
在使用batch Normalization的时候,也就是在给网络添加了BN层,作者发现对风格迁移、铅笔画有帮助,在其他操作上的表现不是很好,越是提出来自适应的BN,也就是自适应归一化函数。
\[\phi^s(x) = \lambda_s x + \mu_s BN(x)\]、
其中,\(\lambda_s ,\mu_s \in \mathbb{R}\) 是在反向传播中学习的参数。
训练是时候,是输入图片对,进行有监督训练,用了很多loss函数训练,最后发现均方误差才是最好的。
\[\ell(\mathcal{K},\mathcal{B}) = \sum_i \frac{1}{N_i} \parallel \hat{f} (I_i;\mathcal{K},\mathcal{B}) - f(I_i)\parallel \]
那些复杂的loss,b并没有给实验提高精度。
为了提高模型对分辨率的使用能力,在训练的过程中,随机选择图片的分辨率在(320p到1440p)之间。这些图片是随机裁剪的获得的。训练的采用Adam ,迭代500k次,耗时一天。
网络的具体细节:
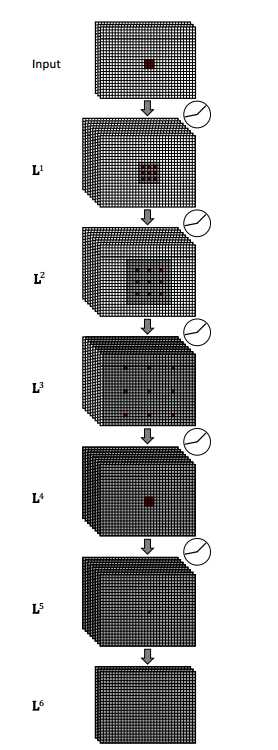
上图只是演示图,实际上的更深。圆圈表示非线性函数LReLU。除了第一层和最后一层是三个通道外,其余均是多个通道,倒数第二层使用1X1的卷积,无非线性转化,得到最后的一层。
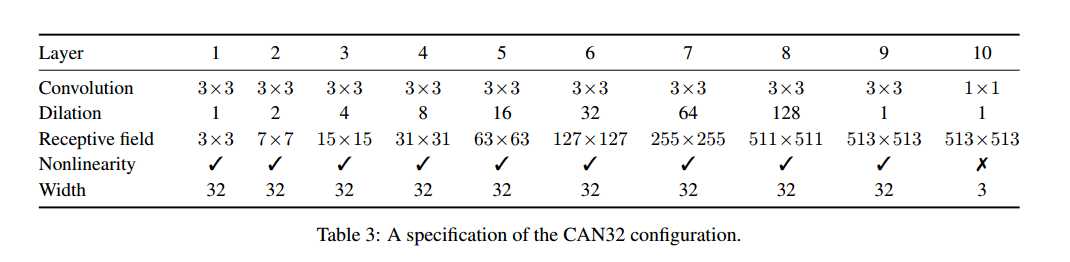
CAN 32的结构(d = 10 and w = 32 )如下:
Encoder-decoder网络。说是参考U-Net搞得一个hourglass-shaped networks (沙漏型网络,这个形容词不错)。对于U-Net主要的修改是,为了减少计算量和内存,减少了一半的卷积核;缩放了最后结果输出,使得输出图片和输入一样大。(关于这个修改,我觉得很不科学啊,既然要和它对比,为什么要阉割之后再对比呢?)
文章给出的理由是:
we found that this is sufficient to get high accuracy and it matches our configuration of the other baselines.
然后又说,能够获得差不多的精度,甚至更快~缺点主要是参数太多,高出两个数量级。
还有一个是FCN-8s。这个模型的问题是,参数多,精度低。
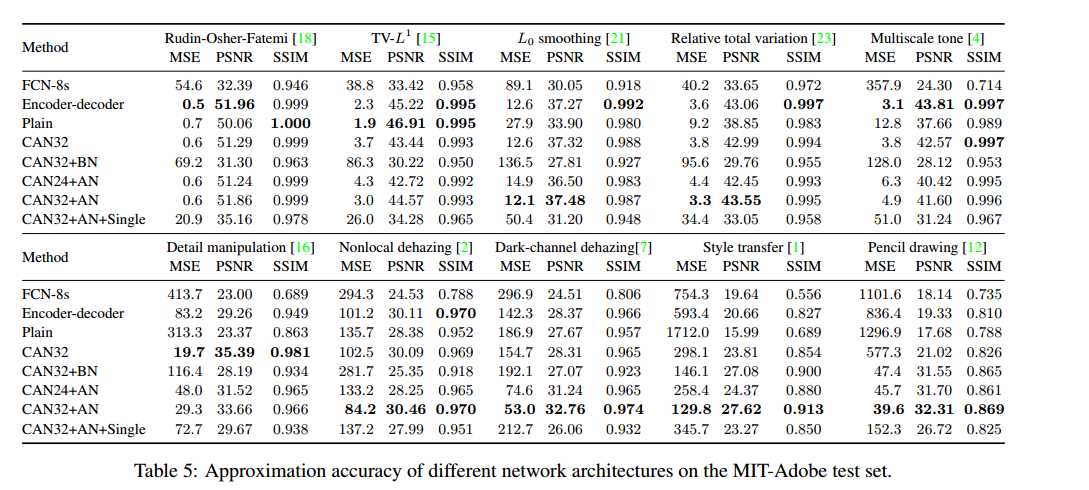
作者另外做了关于深度和宽度(应该说是通道数)的实验。
?
作者工作量不少,可能也跟任务特别多有关,相当于整合了很多任务。模型最大的特点就是参考那篇ICLR 2016,大量使用空洞卷积。这个模型我也想过,只是没想到去用来代替这么多任务。实验有些地方不是很好,比如Unet那块。还是有些启发的。2333。
Note_Fast Image Processing with Fully-Convolutional Networks
原文地址:https://www.cnblogs.com/blog4ljy/p/9064799.html