标签:函数名 UNC 应该 装饰器 reduce tool 注意 .com 偏函数
Python 函数
1:绝对值的函数abs()
>>> abs(-10)
10
2:map()函数
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个
list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
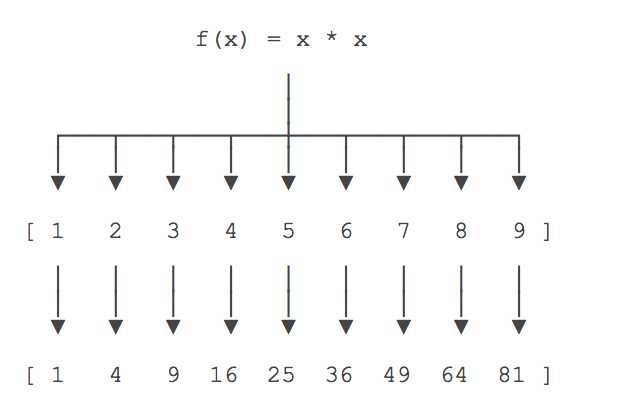
现在,我们用Python代码实现:
>>> def f(x): ... return x * x ... >>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> list(r) [1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
你可能会想,不需要map()函数,写一个循环,也可以计算出结果:
L = [] for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]: L.append(f(n)) print(L)
的确可以,但是,从上面的循环代码,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list”吗?
所以,map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])) [‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘]
只需要一行代码。
3:reduce()函数
reduce()把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce()实现:
>>> from functools import reduce >>> def add(x, y): ... return x + y ... >>> reduce(add, [1, 3, 5, 7, 9]) 25
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
>>> from functools import reduce >>> def fn(x, y): ... return x * 10 + y ... >>> reduce(fn, [1, 3, 5, 7, 9]) 13579
这个例子本身没多大用处,但是,如果考虑到字符串str也是一个序列,对上面的例子稍加改动,配合map(),我们就可以写出把str转换为int的函数:
>>> from functools import reduce >>> def fn(x, y): ... return x * 10 + y ... >>> def char2num(s): ... digits = {‘0‘: 0, ‘1‘: 1, ‘2‘: 2, ‘3‘: 3, ‘4‘: 4, ‘5‘: 5, ‘6‘: 6, ‘7‘: 7, ‘8‘: 8, ‘9‘: 9} ... return digits[s] ... >>> reduce(fn, map(char2num, ‘13579‘)) 13579
整理成一个str2int的函数就是:
from functools import reduce DIGITS = {‘0‘: 0, ‘1‘: 1, ‘2‘: 2, ‘3‘: 3, ‘4‘: 4, ‘5‘: 5, ‘6‘: 6, ‘7‘: 7, ‘8‘: 8, ‘9‘: 9} def str2int(s): def fn(x, y): return x * 10 + y def char2num(s): return DIGITS[s] return reduce(fn, map(char2num, s))
还可以用lambda函数进一步简化成:
from functools import reduce DIGITS = {‘0‘: 0, ‘1‘: 1, ‘2‘: 2, ‘3‘: 3, ‘4‘: 4, ‘5‘: 5, ‘6‘: 6, ‘7‘: 7, ‘8‘: 8, ‘9‘: 9} def char2num(s): return DIGITS[s] def str2int(s): return reduce(lambda x, y: x * 10 + y, map(char2num, s))
也就是说,假设Python没有提供int()函数,你完全可以自己写一个把字符串转化为整数的函数,而且只需要几行代码!
4: filter()函数
filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n): return n % 2 == 1 list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])) # 结果: [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s): return s and s.strip() list(filter(not_empty, [‘A‘, ‘‘, ‘B‘, None, ‘C‘, ‘ ‘])) # 结果: [‘A‘, ‘B‘, ‘C‘]
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
5: sorted()函数
Python内置的sorted()函数就可以对list进行排序:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。对比原始的list和经过key=abs处理过的list:
list = [36, 5, -12, 9, -21]
keys = [36, 5, 12, 9, 21]
我们再看一个字符串排序的例子:
>>> sorted([‘bob‘, ‘about‘, ‘Zoo‘, ‘Credit‘]) [‘Credit‘, ‘Zoo‘, ‘about‘, ‘bob‘]
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于‘Z‘ < ‘a‘,结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
>>> sorted([‘bob‘, ‘about‘, ‘Zoo‘, ‘Credit‘], key=str.lower) [‘about‘, ‘bob‘, ‘Credit‘, ‘Zoo‘]
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
>>> sorted([‘bob‘, ‘about‘, ‘Zoo‘, ‘Credit‘], key=str.lower, reverse=True) [‘Zoo‘, ‘Credit‘, ‘bob‘, ‘about‘]
从上述例子可以看出,高阶函数的抽象能力是非常强大的,而且,核心代码可以保持得非常简洁。
sorted()也是一个高阶函数。用sorted()排序的关键在于实现一个映射函数。
6: 函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
我们来实现一个可变参数的求和。通常情况下,求和的函数是这样定义的:
def calc_sum(*args): ax = 0 for n in args: ax = ax + n return ax
但是,如果不需要立刻求和,而是在后面的代码中,根据需要再计算怎么办?可以不返回求和的结果,而是返回求和的函数:
def lazy_sum(*args): def sum(): ax = 0 for n in args: ax = ax + n return ax return sum
当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
>>> f = lazy_sum(1, 3, 5, 7, 9) >>> f <function lazy_sum.<locals>.sum at 0x101c6ed90>
调用函数f时,才真正计算求和的结果:
>>> f()
25
在这个例子中,我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
请再注意一点,当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
>>> f1 = lazy_sum(1, 3, 5, 7, 9) >>> f2 = lazy_sum(1, 3, 5, 7, 9) >>> f1==f2 False
f1()和f2()的调用结果互不影响。
7: 闭包
注意到返回的函数在其定义内部引用了局部变量args,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用,所以,闭包用起来简单,实现起来可不容易。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行。我们来看一个例子:
def count(): fs = [] for i in range(1, 4): def f(): return i*i fs.append(f) return fs f1, f2, f3 = count()
在上面的例子中,每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了。
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是
>>> f1() 9 >>> f2() 9 >>> f3() 9
全部都是9!原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
def count(): def f(j): def g(): return j*j return g fs = [] for i in range(1, 4): fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f() return fs
再看看结果:
>>> f1, f2, f3 = count() >>> f1() 1 >>> f2() 4 >>> f3() 9
缺点是代码较长,可利用lambda函数缩短代码。
8: 匿名函数lambda
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])) [1, 4, 9, 16, 25, 36, 49, 64, 81]
通过对比可以看出,匿名函数lambda x: x * x实际上就是:
def f(x): return x * x
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
>>> f = lambda x: x * x >>> f <function <lambda> at 0x101c6ef28> >>> f(5) 25
同样,也可以把匿名函数作为返回值返回,比如:
def build(x, y): return lambda: x * x + y * y
9: 装饰器(Decorator)
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
>>> def now(): ... print(‘2015-3-25‘) ... >>> f = now >>> f() 2015-3-25
函数对象有一个__name__属性,可以拿到函数的名字:
>>> now.__name__ ‘now‘ >>> f.__name__ ‘now‘
现在,假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
本质上,decorator就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的decorator,可以定义如下:
def log(func): def wrapper(*args, **kw): print(‘call %s():‘ % func.__name__) return func(*args, **kw) return wrapper
观察上面的log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的@语法,把decorator置于函数的定义处:
@log def now(): print(‘2015-3-25‘)
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
>>> now()
call now():
2015-3-25
把@log放到now()函数的定义处,相当于执行了语句:
now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:
def log(text): def decorator(func): def wrapper(*args, **kw): print(‘%s %s():‘ % (text, func.__name__)) return func(*args, **kw) return wrapper return decorator
这个3层嵌套的decorator用法如下:
@log(‘execute‘) def now(): print(‘2015-3-25‘)
执行结果如下:
>>> now()
execute now():
2015-3-25
和两层嵌套的decorator相比,3层嵌套的效果是这样的:
>>> now = log(‘execute‘)(now)
我们来剖析上面的语句,首先执行log(‘execute‘),返回的是decorator函数,再调用返回的函数,参数是now函数,返回值最终是wrapper函数。
以上两种decorator的定义都没有问题,但还差最后一步。因为我们讲了函数也是对象,它有__name__等属性,但你去看经过decorator装饰之后的函数,它们的__name__已经从原来的‘now‘变成了‘wrapper‘:
>>> now.__name__ ‘wrapper‘
因为返回的那个wrapper()函数名字就是‘wrapper‘,所以,需要把原始函数的__name__等属性复制到wrapper()函数中,否则,有些依赖函数签名的代码执行就会出错。
不需要编写wrapper.__name__ = func.__name__这样的代码,Python内置的functools.wraps就是干这个事的,所以,一个完整的decorator的写法如下:
import functools def log(func): @functools.wraps(func) def wrapper(*args, **kw): print(‘call %s():‘ % func.__name__) return func(*args, **kw) return wrapper
或者针对带参数的decorator
import functools def log(text): def decorator(func): @functools.wraps(func) def wrapper(*args, **kw): print(‘%s %s():‘ % (text, func.__name__)) return func(*args, **kw) return wrapper return decorator
import functools是导入functools模块。模块的概念稍候讲解。现在,只需记住在定义wrapper()的前面加上@functools.wraps(func)即可。
10: 偏函数(Partial function)
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
在介绍函数参数的时候,我们讲到,通过设定参数的默认值,可以降低函数调用的难度。而偏函数也可以做到这一点。举例如下:
int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换
>>> int(‘12345‘) 12345
但int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做N进制的转换:
>>> int(‘12345‘, base=8) 5349 >>> int(‘12345‘, 16) 74565
假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,于是,我们想到,可以定义一个int2()的函数,默认把base=2传进去:
def int2(x, base=2): return int(x, base)
这样,我们转换二进制就非常方便了:
>>> int2(‘1000000‘) 64 >>> int2(‘1010101‘) 85
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools >>> int2 = functools.partial(int, base=2) >>> int2(‘1000000‘) 64 >>> int2(‘1010101‘) 85
所以,简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值:
>>> int2(‘1000000‘, base=10) 1000000
最后,创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数,当传入:
int2 = functools.partial(int, base=2)
实际上固定了int()函数的关键字参数base,也就是:
int2(‘10010‘)
相当于:
kw = { ‘base‘: 2 }
int(‘10010‘, **kw)
当传入:
max2 = functools.partial(max, 10)
实际上会把10作为*args的一部分自动加到左边,也就是:
max2(5, 6, 7)
相当于:
args = (10, 5, 6, 7)
max(*args)
结果为10。
当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
标签:函数名 UNC 应该 装饰器 reduce tool 注意 .com 偏函数
原文地址:https://www.cnblogs.com/nelsen-chen/p/9073956.html