标签:oat 解析 方式 img body 分词器 一个 mit 不能
Document:文档对象,是一条原始数据
| 文档编号 | 文档内容 |
|---|---|
| 1 | 谷歌地图之父跳槽FaceBook |
| 2 | 谷歌地图之父加盟FaceBook |
| 3 | 谷歌地图创始人拉斯离开谷歌加盟Facebook |
| 4 | 谷歌地图之父跳槽Facebook与Wave项目取消有关 |
| 5 | 谷歌地图之父拉斯加盟社交网站Facebook |
==一条记录就是一个document,document的每一个字段就是一个Field==

private final static File INDEX_FILE = new File("E:\\DevelopTools\\indexDir");
public static void indexCreate(Document doc) throws Exception {
// 创建目录对象,指定索引库的存放位置;FSDirectory文件系统;RAMDirectory内存
Directory dir = FSDirectory.open(INDEX_FILE);
// 创建分词器对象
Analyzer analyzer = new IKAnalyzer();
// 创建索引写入器配置对象,第一个参数版本VerSion.LATEST,第二个参数分词器
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
// 创建索引写入器
IndexWriter indexWriter = new IndexWriter(dir, conf);
// 向索引库写入文档对象
indexWriter.addDocument(doc);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
}@Test
public void createTest() throws Exception {
//
Document doc = new Document();
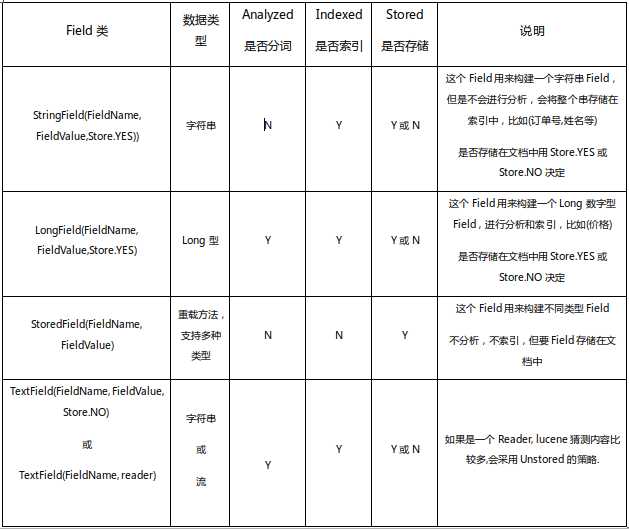
doc.add(new LongField("id", 1, Store.YES));
doc.add(new TextField("title", "谷歌地图之父跳槽FaceBook", Store.YES));
doc.add(new TextField("context", "据国外媒体报道,曾先后负责谷歌地图和Wave开发工作的拉斯·拉斯姆森(Lars Rasmussen)已经离开谷歌,并将加盟Facebook。", Store.YES));
indexCreate(doc);
}public static void indexSearcher(Query query, Integer n) throws IOException {
// 初始化索引库对象
Directory dir = FSDirectory.open(INDEX_FILE);
// 索引读取工具
IndexReader indexReader = DirectoryReader.open(dir);
// 索引搜索对象
IndexSearcher indexSeracher = new IndexSearcher(indexReader);
// 执行搜索操作,返回值topDocs
TopDocs topDocs = indexSeracher.search(query, n);
// 匹配搜索条件的总记录数
System.out.println("一共命中:" + topDocs.totalHits + "条数据");
// 获得得分文档数组对象,得分文档对象包含得分和文档编号
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc;
float score = scoreDoc.score;
System.out.println("文档编号:" + docID);
System.out.println("文档得分:" + score);
// 获取文档对象,通过索引读取工具
Document document = indexReader.document(docID);
System.out.println("id:" + document.get("id"));
System.out.println("title:" + document.get("title"));
System.out.println("context:" + document.get("context"));
}
indexReader.close();
}@Test
public void searchTest() throws Exception {
//单一字段的查询解析器
// 创建查询解析器对象
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse("谷歌");
//根据Query搜索,返回评分最高的n条记录
indexSearcher(query, 10);
/*多字段的查询解析器
MultiFieldQueryParser parser = new MultiFieldQueryParser(new String[]{"id","title"}, new IKAnalyzer());
Query query = parser.parse("1");*/
}//词条查询,查询条件必须是最小粒度不可再分割的内容
Query query = new TermQuery(new Term("title", "谷歌"));
//通配符查询, ?:匹配一个字符, *:匹配多个字符
Query query = new WildcardQuery(new Term("title", "*歌*"));
//模糊查询, 参数:1-词条,查询字段及关键词,关键词允许写错;2-允许写错的最大编辑距离,并且不能大于2(0~2)
Query query = new FuzzyQuery(new Term("title", "facebool"), 1);
//数值范围查询,查询非String类型的数据或者说是一些继承Numeric类的对象的查询,参数1-字段;2-最小值;3-最大值;4-是否包含最小值;5-是否包含最大值
Query query = NumericRangeQuery.newLongRange("id", 2l, 4l, true, true);
//组合查询, 交集: Occur.MUST + Occur.MUST, 并集:Occur.SHOULD + Occur.SHOULD, 非:Occur.MUST_NOT
BooleanQuery query = new BooleanQuery();
Query query1 = NumericRangeQuery.newLongRange("id", 2l, 4l, true, true);
Query query2 = new WildcardQuery(new Term("title", "*歌*"));
query.add(query1, Occur.SHOULD);
query.add(query2, Occur.SHOULD);//本质先删除再添加,先删除所有满足条件的文档,再创建文档, 因此,修改索引通常要根据唯一字段
public static void indexUpdate(Term term, Document doc) throws IOException {
Directory dir = FSDirectory.open(INDEX_FILE);
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(dir, conf);
indexWriter.updateDocument(term, doc);
indexWriter.commit();
indexWriter.close();
}@Test
public void updateTest() throws Exception {
Term term = new Term("title", "facebook");
Document doc = new Document();
doc.add(new LongField("id", 1L, Store.YES));
doc.add(new TextField("title", "谷歌地图之父跳槽FaceBook", Store.YES));
doc.add(new TextField("context", "河马程序员加盟FaceBook", Store.YES));
indexUpdate(term, doc);
}// 执行删除操作(根据词条),要求id字段必须是字符串类型
public static void indexDelete(Term term) throws IOException {
Directory dir = FSDirectory.open(INDEX_FILE);
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(dir, conf);
indexWriter.deleteDocuments(term);
indexWriter.commit();
indexWriter.close();
}
public static void indexDeleteAll() throws IOException {
Directory dir = FSDirectory.open(INDEX_FILE);
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(dir, conf);
indexWriter.deleteAll();
indexWriter.commit();
indexWriter.close();
}@Test
public void deleteTest() throws Exception {
/*
* Term term = new Term("context", "facebook"); indexDelete(term);
*/
indexDeleteAll();
}标签:oat 解析 方式 img body 分词器 一个 mit 不能
原文地址:https://www.cnblogs.com/lifuwei/p/9179493.html