标签:步骤 随机 wiki bim 卷积层 存在 尺寸 表达式 get
卷积可能是现在深入学习中最重要的概念。卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿。但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮助您彻底理解卷积。
已经有一些关于深度学习卷积的博客文章,但我发现他们都对不必要的数学细节高度混淆,这些细节没有以任何有意义的方式进一步理解。这篇博客文章也会有很多数学细节,但我会从概念的角度来看待他们,在这里我用每个人都应该能够理解的图像表示底层数学。这篇博文的第一部分是针对任何想要了解深度学习中卷积和卷积网络的一般概念的人。本博文的第二部分包含高级概念,旨在进一步提高深度学习研究人员和专家对卷积的理解。
这整篇博文都将回答这个问题,但是首先了解这个问题的方向可能会非常有用,那么什么是粗略的卷积?
您可以将卷积想象为信息的混合。想象一下,有两个桶装满了信息,这些信息被倒入一个桶中,然后按照特定的规则混合。每桶信息都有自己的配方,用于描述一个桶中的信息如何与另一个桶混合。因此,卷积是一个有序的过程,两个信息来源交织在一起。
卷积也可以用数学来描述,事实上,它是一种数学运算,如加法,乘法或导数,虽然这种操作本身很复杂,但它可以用来简化更复杂的方程。卷积在物理学和工程学中用于简化这种复杂的方程,第二部分 - 经过简短的卷积数学发展 - 我们将把这些科学领域和深度学习之间的想法联系起来并整合起来,以更深入地理解卷积。但现在我们将从实际的角度来看卷积。
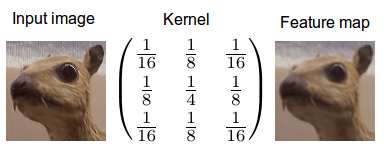
当我们对图像应用卷积时,我们将其应用于两个维度 - 即图像的宽度和高度。我们混合两个信息桶:第一个桶是输入图像,它总共有三个像素矩阵 - 每个矩阵用于红色,蓝色和绿色通道; 一个像素由每个颜色通道中0到255之间的整数值组成。第二个桶是卷积核,一个浮点数的单个矩阵,其中模式和数字的大小可以被认为是如何在卷积操作中将输入图像与内核交织在一起的配方。内核的输出是经过改变的图像,在深度学习中经常被称为特征图。每个颜色通道都会有一个功能图。
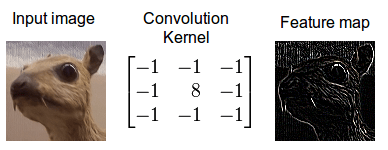
我们现在通过卷积执行这两个信息的实际交织。应用卷积的一种方法是从内核大小的输入图像中获取图像补丁 - 这里我们有一个100×100图像和一个3×3内核,所以我们需要3×3补丁 - 然后执行与图像补丁和卷积核的元素明智的乘法。这个乘法的和然后导致 特征映射的一个像素。在计算了特征映射的一个像素之后,图像块提取器的中心将一个像素滑动到另一个方向,并且重复该计算。当以这种方式计算了特征映射的所有像素时,计算结束。以下gif中的一个图像补丁说明了此过程。
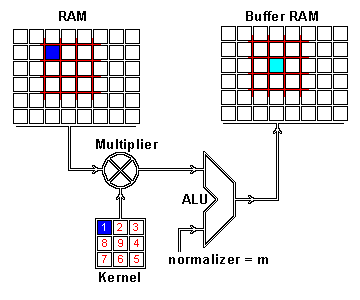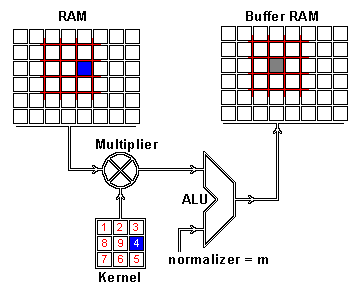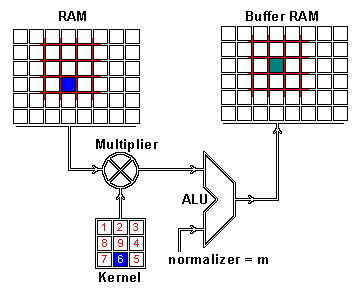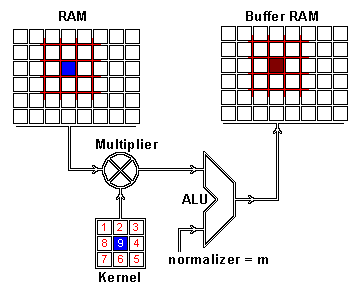
对结果特征映射的一个像素进行卷积运算:原始图像(RAM)的一个图像块(红色)与内核相乘,并且其总和被写入特征映射像素(缓冲区RAM)。GIF由格伦·威廉姆森谁运行一个网站,具有许多技术GIF格式。
正如你所看到的,还有一个规范化过程,其中输出值通过内核的大小(9)进行归一化; 这是为了确保图片和特征地图的总强度保持不变。
图像中可能存在很多令人分心的信息,这与我们试图实现的目标无关。一个很好的例子就是我在Burda Bootcamp中与Jannek Thomas一起完成的一个项目。Burda Bootcamp是一个快速原型开发实验室,学生在黑客马拉松式的环境中工作,以非常短的时间间隔创造技术上有风险的产品。与我的9位同事一起,我们在2个月内创建了11款产品。在一个项目中,我想用深度自动编码器建立时尚图像搜索:您上传时尚物品的图像,自动编码器应找到包含相似风格衣服的图像。
现在,如果你想区分衣服的风格,衣服的颜色不会那么有用; 像品牌标志等微小的细节也不是很重要。最重要的可能是衣服的形状。通常,衬衫的形状与衬衫,外套或裤子的形状非常不同。因此,如果我们可以过滤图像中不必要的信息,那么我们的算法不会被颜色和品牌标志等不必要的细节分散注意力。我们可以通过使用内核来卷积图像来轻松实现这一点。
我的同事Jannek Thomas对数据进行了预处理,并应用了一个Sobel边缘检测器(类似于上面的内核)将除图像外形外的所有图像都滤除掉 - 这就是为什么卷积应用通常称为滤波,内核通常被称为过滤器(这个过滤过程的更精确的定义将在下面进行说明)。如果您想要区分不同类型的衣服,由于只保留相关的形状信息,所以从边缘检测器内核生成的特征图将非常有用。

Sobel过滤了训练过的自动编码器的输入和结果:左上角的图像是搜索查询,其他图像是具有自动编码器代码的结果,该代码与通过余弦相似度测量的搜索查询最相似。你会发现autoencoder真的只是看着搜索查询的形状而不是它的颜色。但是,您也可以看到,对于穿着衣服的人(第5列)的图像以及对衣架形状(第4列)敏感,此步骤不起作用。
我们可以更进一步:有几十个不同的内核可以生成许多不同的特征映射,例如使图像更清晰(更多细节),或模糊图像(更少的细节),并且每个特征映射可以帮助我们的算法在它的任务上做得更好(细节,比如夹克上的3而不是2个按钮可能很重要)。
使用这种过程 - 输入,转换输入并将转换后的输入提供给算法 - 称为特征工程。特征工程是非常困难的,只有很少的资源可以帮助你学习这个技巧。因此,很少有人能够巧妙地将特征工程应用于广泛的任务。特征工程是 - 手下来 - 在Kaggle比赛中获得好成绩的最重要的技能。特征工程是如此的困难,因为对于每种类型的数据和每种类型的问题,不同的特征都做得很好:图像任务的特征工程知识对于时间序列数据来说是无用的; 即使我们有两个相似的图像任务,但设计好的特征并不容易,因为图像中的对象也决定了什么会起作用,哪些不会起作用。这需要很多经验才能完成这一切。
所以特征工程是非常困难的,你必须从头开始为每个新任务做好。但是当我们看图像时,是否有可能自动找到最适合于任务的内核?
卷积网正是这样做的。我们没有在内核中使用固定数字,而是将参数分配给这些内核,这些内核将在数据上进行训练。当我们训练我们的卷积网络时,内核在为给定相关信息过滤给定图像(或给定特征映射)方面会变得越来越好。这个过程是自动的,被称为特征学习。特征学习自动地推广到每个新任务:我们只需要简单地训练我们的网络以找到与新任务相关的新滤波器。这使得卷积网络如此强大 - 特征工程没有困难!
通常我们不是在卷积网络中学习单个内核,而是在同一时间学习多个内核的层次结构。例如,应用于256×256图像的32x16x16内核将生成32个尺寸为241×241的特征映射(这是标准尺寸,尺寸可能因实现而异;
我们现在对卷积是什么以及卷积网络发生了什么以及卷积网络如此强大的原因有了很好的直觉。但是我们可以深入了解一个卷积操作中真正发生的事情。在这样做的时候,我们会看到计算卷积的最初解释是相当麻烦的,我们可以开发更复杂的解释,这将有助于我们更广泛地考虑卷积,以便我们可以将它们应用于许多不同的数据。为了更深入地理解,第一步是理解卷积定理。
为了进一步发展卷积的概念,我们利用了卷积定理,该卷积定理将时域/空域中的卷积(其中卷积的特征是难以积分的积分或和)与频率/傅立叶域中的单纯元素乘法相关联。这个定理非常强大,被广泛应用于许多科学领域。卷积定理也是原因之一快速傅立叶变换(FFT)算法是由一些人认为的20中最重要的算法之一个世纪。
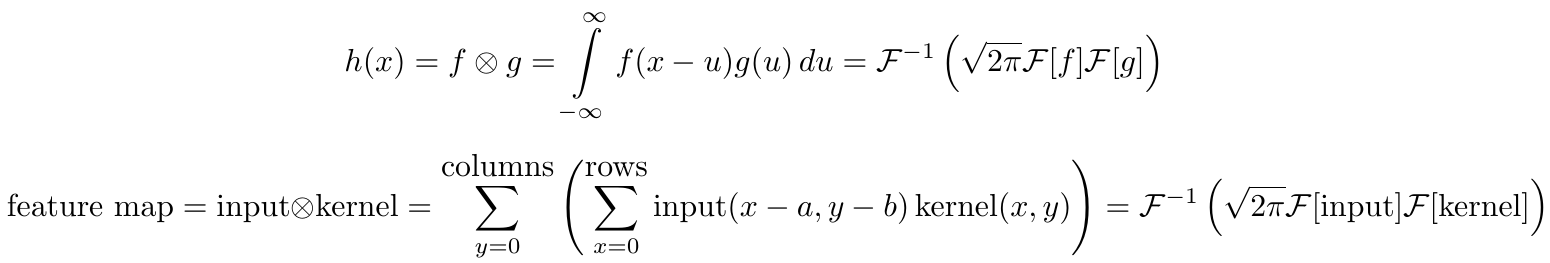
第一个方程是两个一般连续函数的一维连续卷积定理; 第二个方程是离散图像数据的二维离散卷积定理。这里



为了更好地理解卷积定理中会发生什么,我们现在来看看关于数字图像处理的傅里叶变换的解释。
快速傅里叶变换是一种将数据从空间/时间域转换为频率域或傅立叶域的算法。傅里叶变换用类似波浪的余弦和正弦项来描述原始函数。重要的是要注意,傅立叶变换通常是复数值,这意味着一个真实的值被转换成一个具有实部和虚部的复数值。通常虚部只对某些操作很重要,并将频率转换回空间/时间范围,在本篇博文中大部分将被忽略。在下面,您可以看到一个可视化如何通过傅立叶变换来转换信号(通常具有时间参数的信息的函数,通常是周期性的)。
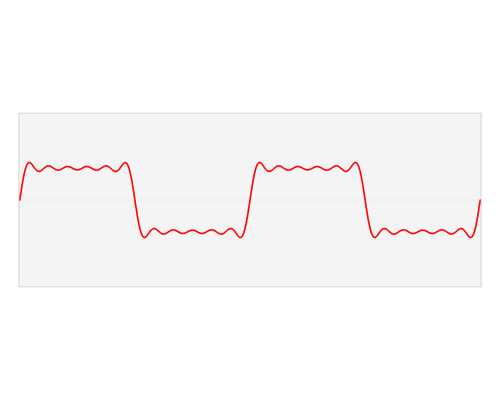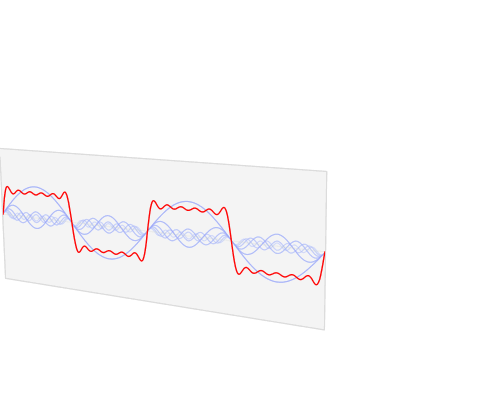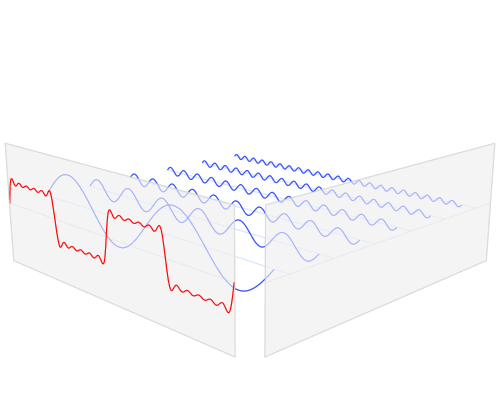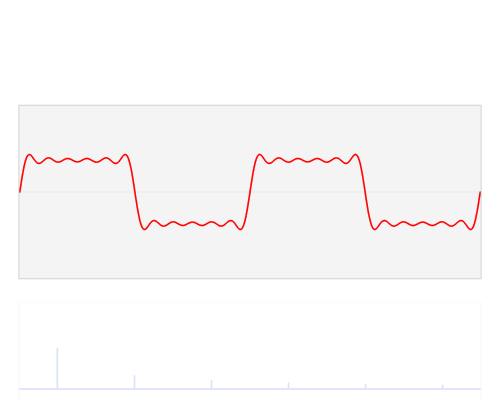
时域(红色)转换到频域(蓝色)。资源
您可能不知道这一点,但很可能您每天都会看到傅里叶变换值:如果红色信号是歌曲,那么蓝色值可能是您的MP3播放器显示的均衡器条。

Fisher&Koryllos的图像(1998)。鲍勃费舍尔还运行一个关于傅立叶变换和一般图像处理的优秀网站。
我们怎样才能想象图像的频率?想象一张纸上面有两种图案之一。现在想象一下,波从纸的一个边缘传播到另一个波,这个波在每个特定颜色的条纹穿透纸张并且在另一个上方盘旋。这种波以特定的间隔穿透黑色和白色部分,例如每两个像素 - 这代表了频率。在傅立叶变换中,较低的频率靠近中心,较高的频率位于边缘(图像的最大频率处于边缘)。具有高强度(图像中的白色)的傅立叶变换值的位置根据原始图像中强度最大变化的方向排序。

我们立即看到傅里叶变换包含了很多关于图像中物体方向的信息。如果一个物体被转过37度,则很难从原始像素信息中判断出来,但是傅里叶变换后的值很清楚。
这是一个重要的见解:由于卷积定理,我们可以想象,卷积网络对傅立叶域中的图像起作用,并且从上面的图像我们现在知道该域中的图像包含大量关于方向的信息。因此,卷积网络在旋转图像时应该优于传统算法,事实确实如此(虽然当我们将它们与人类视觉进行比较时,卷积网络仍然非常糟糕)。
卷积运算经常被描述为一个滤波操作,以及为什么卷积核通常被命名为滤波器的原因将从下一个例子中看出,这个例子非常接近卷积。

如果我们用傅立叶变换对原始图像进行变换,然后将它乘以由傅里叶域中的零填充的圆圈(零=黑色),我们会过滤掉所有高频值(它们将被设置为零,因为零填充值)。请注意,滤波后的图像仍然具有相同的条纹图案,但其质量现在更糟 - 这是jpeg压缩的工作原理(尽管使用了不同但相似的变换),我们转换图像,仅保留某些频率并转换回空间图像域; 在这个例子中,压缩比将是黑色区域与圆圈大小的大小。
如果我们现在想象这个圆是一个卷积核,那么我们就完全有了卷积 - 就像在卷积网中一样。还有很多技巧可以加速并稳定用傅里叶变换计算卷积,但这是如何完成的基本原理。
现在我们已经确立了卷积定理和傅里叶变换的意义,现在我们可以将这种理解应用到科学的不同领域,并增强我们对深度学习中卷积的解释。
流体力学关注于为流体如空气和水的流动(飞机周围的空气流动;水在桥的悬挂部分周围流动)创建微分方程模型。傅里叶变换不仅简化了卷积,而且还简化了差分,这就是为什么傅里叶变换广泛用于流体力学领域或任何具有微分方程的领域。有时,找到流体流动问题的分析解决方案的唯一方法是用傅立叶变换来简化偏微分方程。在这个过程中,我们有时可以用两个函数的卷积来重写这种偏微分方程的解,这样就可以很容易地解释解。一维扩散方程就是这种情况,
通过用外力移动液体(用勺子搅拌),可以混合两种液体(牛奶和咖啡) - 这就是所谓的对流,通常速度非常快。但是你也可以等待,两种流体会自己混合(如果它是化学可能的话) - 这就是所谓的扩散,与对流相比通常非常缓慢。
想象一下,水族馆由一个薄而可拆卸的屏障分成两部分,其中水族箱的一侧充满咸水,另一侧充满淡水。如果您现在仔细地移除薄壁屏障,两种流体将混合在一起,直到整个水族箱到处都有相同浓度的盐。这个过程更加“猛烈”,淡水和咸水之间的咸味差异越大。
现在想象你有一个方形的水族箱,有256×256的薄壁屏障,分隔256×256立方体,每个立方体含有不同的盐浓度。如果现在去除屏障,两个立方体之间几乎没有混合,盐浓度差异很小,但两个立方体之间的盐混合浓度非常不同。现在想象一下,256×256网格是一个图像,立方体是像素,盐浓度是每个像素的强度。现在我们不用扩散盐浓度,而是扩散了像素信息。
事实证明,这只是扩散方程解法卷积的一部分:一部分简单地说就是某个区域某一流体的初始浓度 - 或者图像方面 - 初始图像的初始像素强度。为了完成将卷积解释为扩散过程,我们需要解释扩散方程的解的第二部分:传播子。
传播者是概率密度函数,它表示流体粒子在哪个方向随时间扩散。这里的问题是我们在深度学习中没有概率函数,但是卷积核 - 我们如何统一这些概念?
我们可以应用一个归一化,将卷积核变成概率密度函数。这就像计算分类任务中输出值的softmax一样。这里是上面第一个例子中边缘检测器内核的softmax归一化。
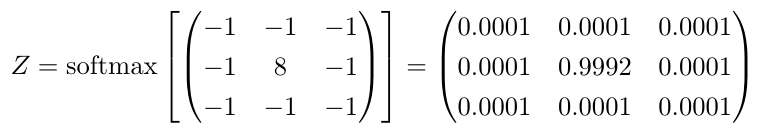
边缘检测器的Softmax:为计算softmax标准化,我们将内核的每个值[latex background =“ffffff”] {x} [/ latex]并应用[latex background =“ffffff”] {e ^ x} [ /胶乳]。之后,我们除以所有[latex background =“ffffff”] {e ^ x} [/ latex]的总和。请注意,这种计算softmax的技术对于大多数卷积核是很好的,但对于更复杂的数据,计算有点不同以确保数值稳定性(对于非常大和非常小的值,浮点计算固有地不稳定,您必须在这种情况下仔细导航周围的麻烦)。
现在我们对扩散方面的图像进行卷积的全面解释。我们可以将卷积运算想象成一个两部分扩散过程:首先,像素强度发生变化的强扩散(从黑色到白色,或从黄色到蓝色等),其次,区域中的扩散过程受到调节通过卷积核的概率分布。这意味着内核区域中的每个像素根据内核概率密度扩散到内核中的另一个位置。
对于上面的边缘检测器,几乎周围区域的所有信息都集中在一个空间中(这对流体中的扩散是不自然的,但是这种解释在数学上是正确的)。例如,所有低于0.0001值的像素将很可能流入中心像素并在那里累积。在相邻像素之间的最大差异处最终浓度将是最大的,因为这里扩散过程是最明显的。反过来,相邻像素的最大差异就在那里,在不同对象之间的边缘处,所以这解释了为什么上面的内核是边缘检测器。
所以我们有它:卷积作为信息的扩散。我们可以直接在其他内核上应用这种解释。有时我们必须应用softmax标准化来解释,但通常这些数字本身会说明会发生什么。以下面的内核为例。你现在可以解释内核在做什么了吗?点击这里 找到解决方案(有一个链接回到这个位置)。
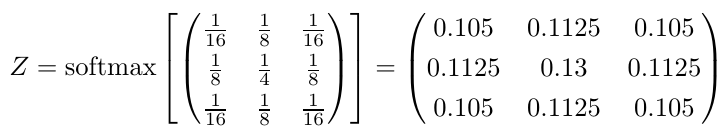
如果我们有一个具有概率的卷积核,我们怎么会有确定性行为?根据传播者的说法,我们必须根据内核的概率分布来解释单粒子扩散,不是吗?
是的,这确实是事实。然而,如果你摄取一小部分液体,比如说一小滴水,那么在这小小的水滴中仍然有数以百万计的水分子,而根据传播者的概率分布,单个分子随机表现出来,一束分子具有准确的确定性行为 - 这是统计力学的重要解释,因此也是流体力学中的扩散。我们可以将传播者的概率解释为信息或像素强度的平均分布; 因此,从流体力学的观点来看,我们的解释是正确的。但是,卷积也有一个有效的随机解释。
传播者是量子力学中的一个重要概念。在量子力学中,一个粒子可以处于一个叠加的位置,它有两个或更多的属性,这些属性通常会在我们的经验世界中排除自己:例如,在量子力学中,一个粒子可以同时在两个地方 - 这是一个单一的对象两个地方。
但是,当您测量粒子的状态时(例如粒子现在在哪里)时,它会在一个地方或另一个地方。换句话说,通过观察粒子来破坏叠加态。传播者然后描述你可以期望粒子的概率分布。因此,在测量之后,根据传播者的概率分布,粒子可能在A处具有30%的概率并且在B处具有70%的概率。
如果我们有颗粒纠缠(在一定距离的鬼影行为),一些粒子可以同时容纳数百乃至数百万个不同的状态 - 这是量子计算机承诺的力量。
所以如果我们将这种解释用于深度学习,我们可以认为图像中的像素处于叠加状态,因此在每个图像块中,每个像素同时在9个位置(如果我们的内核是3×3 )。一旦我们应用了卷积,我们就进行了一次测量,每个像素的叠加就像卷积核的概率分布所描述的那样折叠成一个单独的位置,或者换句话说:对于每个像素,我们随机选择9个像素中的一个像素(具有内核的概率)并且所得到的像素是所有这些像素的平均值。为了这种解释是真实的,这需要是一个真正的随机过程,这意味着,相同的图像和相同的内核通常会产生不同的结果。这种解释并不是一对一地与卷积相关,但它可能会让你思考如何以随机方式应用卷积或如何开发卷积网络的量子算法。量子算法将能够计算所有可能的组合由内核用一次计算描述,并以线性时间/量子位的方式描述图像和内核的大小。
卷积与互相关密切相关。互相关是一种操作,它需要一小段信息(一首歌的几秒钟)来过滤大量信息(整首歌)的相似性(在YouTube上使用类似的技术来自动为视频版权侵权标记) 。
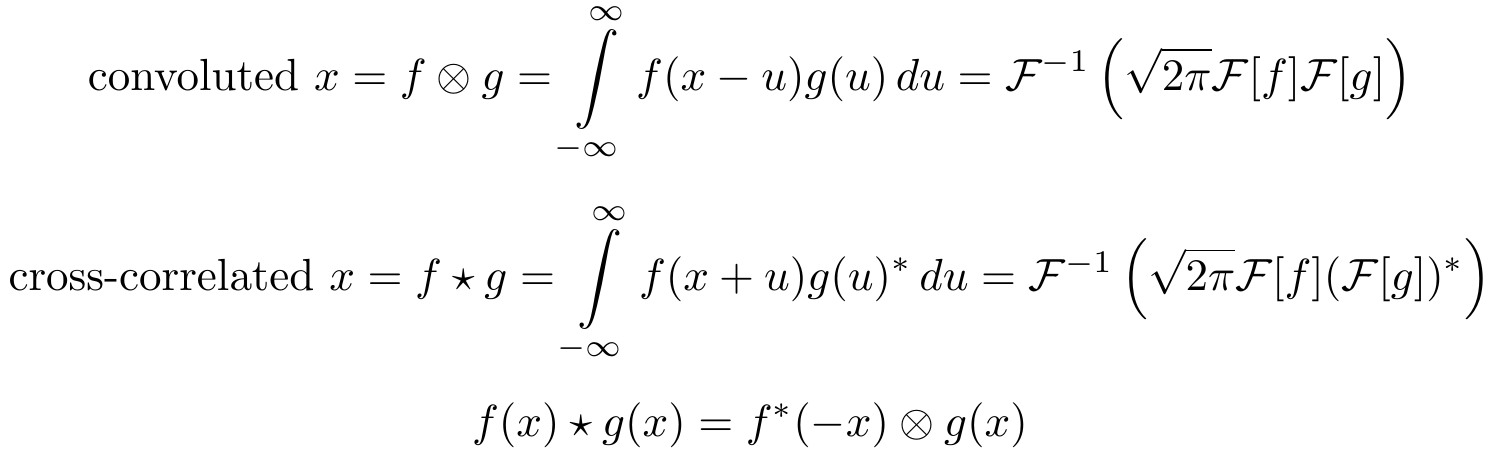
互相关和卷积之间的关系:这里[latex背景=“ffffff”] {\ star} [/ latex]表示互相关和[latex background =“ffffff”] {f ^ *} [/ latex]表示复共轭[latex background =“ffffff”] {f} [/ latex]。
虽然交叉相关看起来很笨拙,但我们可以轻松将其与深度学习中的卷积联系起来:我们可以简单地将搜索图像颠倒过来以通过卷积执行互相关。当我们执行人脸图像与脸部上方图像的卷积时,结果将是脸部与人物匹配位置处的一个或多个明亮像素的图像。

通过卷积进行互相关:输入和内核用零填充,内核旋转180度。白点标记图像和内核之间最强的像素相关性的区域。请注意,输出图像位于空间域中,逆傅立叶变换已应用。图片来自史蒂文史密斯关于数字信号处理的优秀免费在线书籍。
这个例子还说明了用零填充来稳定傅里叶变换,这在许多版本的傅立叶变换中都是必需的。有一些版本需要不同的填充方案:有些实现会在内核周围扭转内核,只需要填充内核,而其他实现则执行分而治之的步骤,并且根本不需要填充。我不会在此扩展; 关于傅立叶变换的文献是巨大的,并且有许多技巧可以让它运行得更好 - 特别是对于图像。
在较低层次上,卷积网络将不会执行互相关,因为我们知道它们在最初的卷积层中执行边缘检测。但是在后面的层次中,更多的抽象特征被生成,卷积网络有可能通过卷积学习执行互相关。可以想象,来自互相关的明亮像素将被重定向到检测面部的单位(Google大脑项目在其架构中有一些专用于面部,猫等的单元;也许互相关在这里起作用?) 。
统计模型和机器学习模型有什么区别?统计模型通常集中在很少的变量上,这些变量很容易解释。统计模型的建立是为了回答问题:药物A比药物B好吗?
机器学习模型与预测性能有关:药物A对于年龄为X的人增加17.83%的成功结果,对于年龄为Y的人,药物B增加22.34%。
机器学习模型通常比统计模型更有效,但它们不可靠。统计模型对于得出准确可靠的结论非常重要:即使药物A比药物B好17.83%,我们也不知道这是否是偶然的原因; 我们需要统计模型来确定这一点。
时间序列数据的两个重要统计模型是加权移动平均数和自回归模型,它们可以组合成ARIMA模型(自回归积分移动平均模型)。与长期短期递归神经网络等模型相比,ARIMA模型相当薄弱,但当您的维度数据较低时(1-5维),ARIMA模型非常稳健。虽然他们的解释通常很费力,但ARIMA模型不像深度学习算法那样是一个黑盒子,如果您需要非常可靠的模型,这是一个很大的优势。
事实证明,我们可以将这些模型重写为卷积,因此我们可以证明深度学习中的卷积可以解释为产生局部ARIMA特征的函数,然后传递到下一层。然而,这个想法并没有完全重叠,所以我们必须保持谨慎,并且看看我们何时能够实施这个想法。
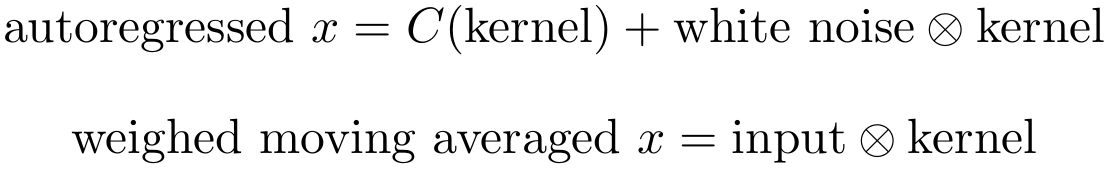
这}")
当我们对数据进行预处理时,我们通常将其与白噪声非常相似:我们经常将它置于零点附近,并将方差/标准偏差设置为1。创建不相关变量的用处不大,因为它的计算密集程度很高,但从概念上讲,它很简单:我们沿着数据的特征向量重新定位坐标轴。
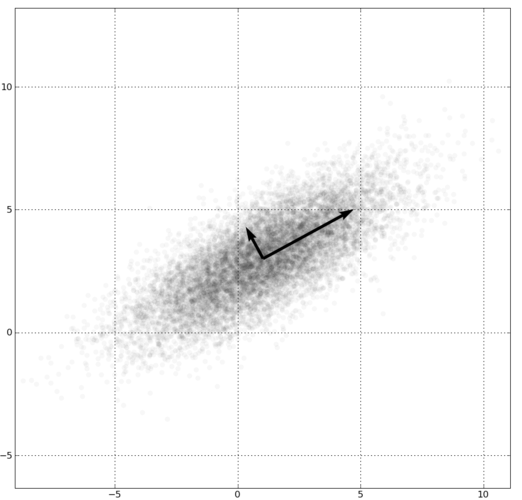
通过沿着特征向量重定向的解相关:这些数据的特征向量由箭头表示。如果我们想解相关数据,我们调整轴的方向与特征向量具有相同的方向。这种技术也用于PCA中,其中具有最小方差(最短特征向量)的维度在重定向后被丢弃。
现在,如果我们认为
加权移动平均数的解释很简单:它只是一些具有一定权重(内核)的数据(输入)的标准卷积。当我们查看页面末尾的高斯平滑内核时,这种解释变得更加清晰。高斯平滑核可以被解释为每个像素的邻域中的像素的加权平均值,或者换句话说,像素在其邻域中被平均(像素“融入”,边缘被平滑)。
虽然单个内核不能同时创建自回归和加权移动平均特征,但我们通常拥有多个内核,并且所有这些内核都可能包含一些特征,如加权移动平均模型和一些类似自回归模型的特征。
在这篇博文中,我们已经看到卷积是什么以及为什么它在深度学习中如此强大。图像补丁的解释很容易理解并且容易计算,但是它有许多概念上的限制。我们通过傅里叶变换开发了卷积,并且看到傅立叶变换包含大量关于图像方向的信息。 随着强大的卷积定理,我们开发了卷积解释作为跨像素信息的扩散。然后,我们从量子力学的角度扩展传播者的概念,以接受通常确定性过程的随机解释。我们发现互相关与卷积非常相似,并且卷积网络的性能可能取决于通过卷积诱导的特征映射之间的相关性。最后,我们完成了卷积与自回归和移动平均模型的关联。
就我个人而言,我发现在这篇博客文章中工作非常有趣。我感觉很久以前,我的数学和统计学本科学习以某种方式被浪费了,因为他们太不切实际了(即使我学习应用数学)。但后来 - 像一个新兴的财产 - 所有这些思想联系在一起,实际上有用的理解出现了。我认为这是一个很好的例子,为什么一个人应该耐心,仔细研究所有的大学课程 - 即使他们起初似乎毫无用处。
上述测验的解决方案:信息在所有像素中扩散几乎相等; 对于相差较大的相邻像素,这个过程将更加强大。这意味着锐利的边缘将被平滑,并且在一个像素中的信息将扩散并与周围的像素轻微混合。这个核被称为高斯模糊或高斯平滑。继续阅读。来源:1 2
图片来源参考
RB Fisher,K. Koryllos,“互动教材; 在文本中嵌入图像处理操作员演示“,Int。J.of Pattern Recognition and Artificial Intelligence,Vol 12,No 8,pp 1095-1123,1998。
卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
标签:步骤 随机 wiki bim 卷积层 存在 尺寸 表达式 get
原文地址:https://www.cnblogs.com/noticeable/p/9194795.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}