标签:实验 背景 AC 9.png pre ESS under 过滤 输入
操作系统:Win10 1709 X64
python版本:3.6.5
依赖模块:PIL、tesserocr。
需要说明的是,在windows系统上PowerShell通过PIP3 install tesserocr安装验证码识别模块时,需要先安装Tesseract (一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强。)可执行文件。
以中国知网的注册页面为例,我们常被要求输入这类简单的字母组成,背景含很多杂线的验证码,如下图所示:
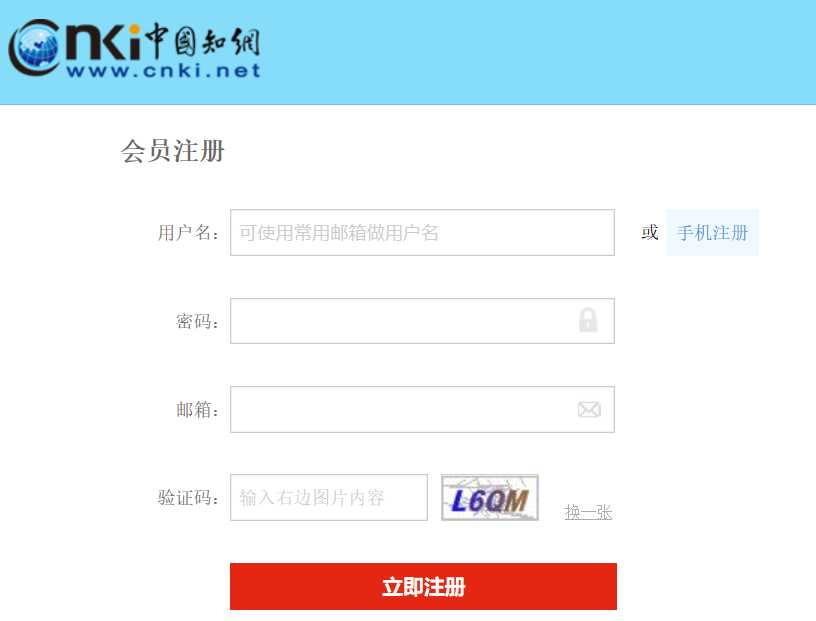
我们对验证码另存为到本地代码所在目录,取名:test.png.
下图是直接用对应模块识别的代码示例:
import tesserocr from PIL import Image image=Image.open(‘test.png‘) image.show() #可以打印出图片,供预览 print(tesserocr.image_to_text(image))

原始图片尺寸较小,极少情况下如果无法正常识别,可以借助图片处理工具PIL模块进行图片等比例放大后保存。此例中直接运行上述代码,结果为“VHIHI”,即使是肉眼可见较为清晰的验证码,如果图片未经处理直接交由tesserocr解析,也可能识别率很低。
通常情况下,我们还需要做些额外的图片处理,如转灰度图,二值化等。
利用Image对应的convert()方法传参L,即可将图片转为灰度图。
image=image.convert(‘L‘)
image.show()
传入1即可完成二值化,如下:
image=image.convert(‘1‘)
image.show()
当然我们更多时候需要根据图片的实际情况指定二值化的阈值,比如我们将阈值设定为80,先转灰度图,再二值化,代码如下:
import tesserocr from PIL import Image image=Image.open(‘test.png‘) image=image.convert("L") threshold=80 table=[] for i in range(256): if i <threshold: table.append(0) else: table.append(1) image=image.point(table,‘1‘) image.show() print(tesserocr.image_to_text(image))
观察到处理后图片如右: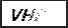
尽管图片已经转为灰度图,且过滤了大部分杂线,但是图片关键像素丢失严重,识别结果自然也不尽如人意,结果:“VH.”。
此时我们根据图片的实际情况,人为调整程序中预设的阈值到130,再观察: ,这次的图片转换效果显著,我们再次查看识别结果,“VHRU”,与肉眼观察到的别无二致,合乎要求。
,这次的图片转换效果显著,我们再次查看识别结果,“VHRU”,与肉眼观察到的别无二致,合乎要求。
可见验证码的识别除了用好识别模块,还需要在必要时引入PIL(图片处理模块)进行图片预处理,预处理过程中的阈值等设定也存有技巧,不同的参数设定,会完全影响最终的识别率。
现实中很多网站的验证码要远比例子中的来得复杂,尤其是12306购票网站的验证码,使行为验证码开始高速发展,肉眼分辨起来都异常困难,这就要求我们对验证码的识别技术要不断提升,才能突破网站逐步升级的反爬虫机制。
标签:实验 背景 AC 9.png pre ESS under 过滤 输入
原文地址:https://www.cnblogs.com/new-june/p/9249903.html
{kind=link}