标签:width ati 也会 一个个 实现 核心 bsp 分享 alpha
1. 为什么介绍此文?
Triplet net 改进工作之一,主要思想是在大数据集(人脸识别)上的困难样本挖掘。人脸识别工作对于图像对匹配而言很有借鉴意义,共性是特征的提取和样本数据的挖掘。
Tripnet net源于文章Deep metric learning using triplet network,在论文中也提出了用于训练三张图像的triplet loss。许多类似的人脸识别、匹配工作都是在大数据集上实现的,这就要求对数据的高效利用。原因是大多数样本在训练中后期不再有梯度贡献,例如含有margin的损失函数(triplet loss、softpn(pnnet中的损失函数,改进于triplet loss)),多数样本很容易满足于这个margin,此时损失函数中的loss不再发生变化,导致训练停滞阻塞。所以如何有效的进行困难样本挖掘(OHEM)成为了关键,困难样本应该包括同类(匹配样本)中距离较大的和非同类(非匹配样本)中距离较小的样本。
2. 本文的贡献
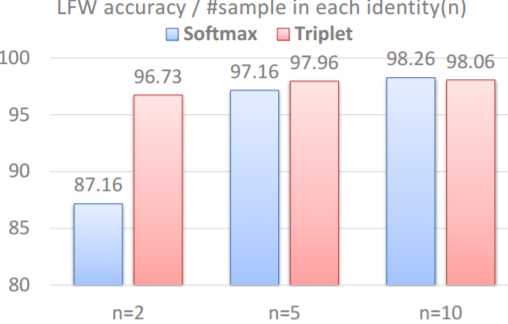
本文的主要改进在于困难样本挖掘。当下已有两种OHNM,但是作者认为在极多identities(类别极多)的数据集中不能足够有效的挖掘困难样本,这就容易陷入局部极小,无法继续更新。所以作者提出首先将数据按照相似度聚类,然后实施batch ohem,这样缩小了搜索空间,更容易挖掘出困难样本。那么为什么使用triplet loss而非softmax loss呢?因为随着类别数增多,与softmax loss相连接的全连接也会增多,导致GPU显存负担,训练周期变长。其次是如果每类只有很少的数据那么训练softmax就会很困难,如下图所示:
 然而使用triplet loss也并非容易,如何有效的在large-scale情况下高效优化?使用triplet会发现数据量激增,可组合的三元组变多,如果要遍历所有组合是不现实的,或者极其低效。主要有两种方法,一是将triplet loss转为softmax loss(triplet net一文中,将triplet loss结合了softmax的输出与mse),另一种是OHNM或batch OHNM。但是第二种挖掘样本的方法都是直接考虑在所有的样本空间来sample一个batch,如果这个batch中有不满足margin的就认为是困难样本。然而这样做并不能保证采样时正好选取了很多很相似的样本,而且(a,p,n)图像组一经选取就已经固定,不会再有其他的组合,所以效率较低。所以作者认为寻找相似的个体(类别)是提高triplet net的核心关键。
然而使用triplet loss也并非容易,如何有效的在large-scale情况下高效优化?使用triplet会发现数据量激增,可组合的三元组变多,如果要遍历所有组合是不现实的,或者极其低效。主要有两种方法,一是将triplet loss转为softmax loss(triplet net一文中,将triplet loss结合了softmax的输出与mse),另一种是OHNM或batch OHNM。但是第二种挖掘样本的方法都是直接考虑在所有的样本空间来sample一个batch,如果这个batch中有不满足margin的就认为是困难样本。然而这样做并不能保证采样时正好选取了很多很相似的样本,而且(a,p,n)图像组一经选取就已经固定,不会再有其他的组合,所以效率较低。所以作者认为寻找相似的个体(类别)是提高triplet net的核心关键。
我的理解是对于含有10个个体(人)的人脸数据,难以区分的肯定是那些长的很像的个体(比如甲与乙)。之前的困难挖掘是首先在这些打散的整体空间中随机设置(a,p,n)三元组然后成批去训练,分错的作为困难样本。这就使得你这些三元组都已经固定了,困难样本不一定是真的困难,除非运气好使得三元组中有很多甲、乙中的样本。而作者提出的想法是首先对于所有样本进行聚类,观察哪些样本比较接近,(甲和乙长得像肯定聚类结果很接近),那么我就在聚好类的子空间中选取(a,p)二元组组成batch,n在这个batch中来选取,那么这个负样本n就会是真正的困难样本。
3. 三种OHEM方法
1)Triplet with OHNM
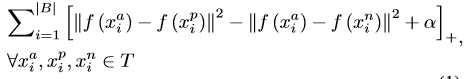
这个公式其实没有体现困难挖掘,因为它认为违背margin限制,即正样本距离没有比负样本距离小alpha(margin)时就认定为困难样本。T代表全体样本空间,所以这里的三元组都是直接从总体样本中选择的,这也是我们大多数人的做法。

看上面这个图示,红色为anchor,浅绿色为positive,天蓝色为negative,深蓝色为hard negative。
这个方法中所有的匹配对和negative都是在整体样本中选取。可见,大多数negative是远离positive匹配对的,尽管训练的时候negative也会被分到一个batch中,但是真正困难的negative很难被选择到。
总结:在打散的整体样本空间随机选择三元组。
2) Triplet with Batch OHNM
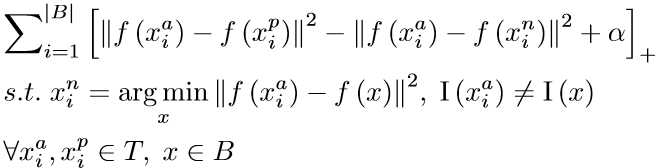
这个方法是为了在一个batch中尽可能挖掘困难样本,这时negative并非在整体样本中选取而是在一个batch中选择。就是说我只在全体样本中选匹配对,然后训练时在batch中再选择negative来训练。这就相当于缩小了搜索范围。从全局搜索变成了局部搜索,所以搜到的困难样本可能性更大。

可以看到首先是匹配对组成batch经过网络得到距离后,根据距离判断相似度,再组成三元组batch,输入到损失函数来优化。
有一点值得注意是选择不要直接选择与匹配对最近距离的negative作为困难样本,可能会导致poor training,应该选择比较近邻的样本。 我的理解是特别相似的三张图反而无法训练,因为它们本来就模糊属于一个类,这样反而造成一种“错误标记”的训练样本,使得网络陷入模式坍塌。
总结:在打散的整体样本空间随机选择二元组,在计算损失时再组成三元组。
3)Triplet with Subspace Learning
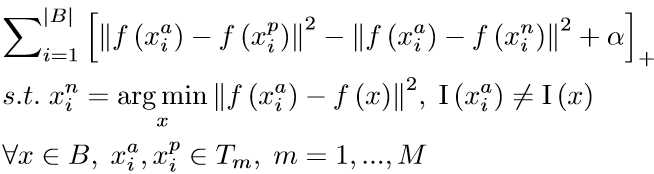
本文的方法,作者认为仅仅选择匹配对组成batch也不妥,即又追根溯源了一步。因为这个batch也是在随即打散后的整体样本中选取的,所以作者认为identity(极多个体的人脸)特别多时,那么长得相似的甲、乙二人的人脸匹配样本对同时进入一个batch的概率就会极低。那么既然长得相似的人都不在一个batch里,那就没有特别困难的样本可挖掘了。一个简单的思路就是对每个identity生成一个representation,然后根据这个representation进行kmeans聚类。最后聚类结果就是一个个subspace。其中距离相近的subspace可以看作难以区分或者说极其相似的样本。为了加速训练,利用预训练网络来初始化,尽管特征提取和聚类耗费时间,但是子空间学习大大减少了搜索空间和训练时间。

需要注意的是identity representation的选择和聚类的数目(子空间数目M)。如果M太小,那么子空间划分的就会很模糊,不是那么相似的也被聚为一类,那就难以挖掘特困难的。如果M太大,许多子空间含有的独立的identity数目就会变少,极端情况下每类单独成为一个子空间,那么挖掘效率就会很低。作者实验为每个子空间含有10k identity。
总结:在整体样本空间中先聚类成子空间,再迭代使用batch OHNM。
4. 总结与思考
总结三种方法。比方说现在有100000个不同的人的人脸数据,其中甲、乙长得特像,那么我们一定希望这两个人脸可以尽可能组合为三元组。OHNM方法是在所有样本中随机选,那么同时把甲乙选到一个三元组中的概率极小。batch OHNM方法是我先只在所有样本中随机选二元组,然后再在这一个batch里面根据距离选择negative,这时如果batch里面都有甲乙的话就有可能被找出来,这也是相对法一而言的灵活性。方法三是首先对全体样本聚类,长得相似的人肯定都被聚为了一类,那么我在这个相似子空间里挖掘岂不更容易?甲乙肯定被划分在了一个子空间,这个子空间里都是长得相似的人脸,挖掘效率更高。
可以看到法二缩小了法一的搜索空间,作者的方法又缩小了法二的搜索空间。即进一步解决了源头的问题,这个追根溯源的思考方法值得学习。
How to Train Triplet Networks with 100K Identities?
标签:width ati 也会 一个个 实现 核心 bsp 分享 alpha
原文地址:https://www.cnblogs.com/king-lps/p/9366874.html