标签:文件名 后台运行 app driver user red ons row 必须
>>> import requests >>> requests.get(‘http://www.baidu.com‘) <Response [200]>
>>> import selenium >>> from selenium import webdriver >>> driver = webdriver.Chrome() DevTools listening on ws://127.0.0.1:60980/devtools/browser/7c2cf211-1a8e-41ea-8e4a-c97356c98910 >>> driver.get(‘http://www.baidu.com‘)
上述命令可以直接打开chrome浏览器,并且打开百度。但是,在这之前我们必须安装一个chromedriver,并且安装googlchrome浏览器,可自行去官网下载。当我们安装完毕后再运行这些测试代码可能依旧会出现一闪而退的情况,那么问题出在,chrome和chromdriver的版本不兼容,可以在官网下载chrome更高的版本,或者chromedriver更低的版本,但是只要都是最高版本就没问题。
>>> from selenium import webdriver >>> driver = webdriver.PhantomJS() >>> driver.get(‘http://www.baidu.com‘) >>> driver.page_source ‘<!DOCTYPE html><!--STATUS OK--><html><head>\n
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(‘<html></html>‘,‘lxml‘) >>>
>>> from pyquery import PyQuery as pq #将其重命名 >>> doc = pq(‘<html></html>‘) >>> doc = pq(‘<html>hello world</html>‘) >>> result = doc(‘html‘).text() >>> result ‘hello world‘
>>> import pymysql >>> conn = pymysql.connect(host=‘localhost‘,user=‘root‘,password = ‘123456‘,port=3306,db=‘mysql‘) >>> cursor = conn.cursor() >>> cursor.execute(‘select * from db‘) 0
>>> import pymongo >>> client = pymongo.MongoClient(‘localhost‘) >>> db = client[‘newtestdb‘] >>> db[‘table‘].insert({‘name‘:‘tom‘}) ObjectId(‘5b868ee4c4d17a0b2466f748‘) >>> db[‘table‘].find_one({‘name‘:‘tom‘}) {‘_id‘: ObjectId(‘5b868ee4c4d17a0b2466f748‘), ‘name‘: ‘tom‘} >>> #完成了单条数据的查询
>>> import redis >>> r = redis.Redis (‘localhost‘,6379) >>> r.set(‘name‘,‘tom‘) True >>> r.get(‘name‘) b‘tom‘ >>> #是一个byte型数据类型
C:\Users\dell>jupyter notebook [I 20:32:37.552 NotebookApp] The port 8888 is already in use, trying another port. [I 20:32:37.703 NotebookApp] Serving notebooks from local directory: C:\Users\dell
可以在选项 new 中建立新python3文件,并且可以编写代码。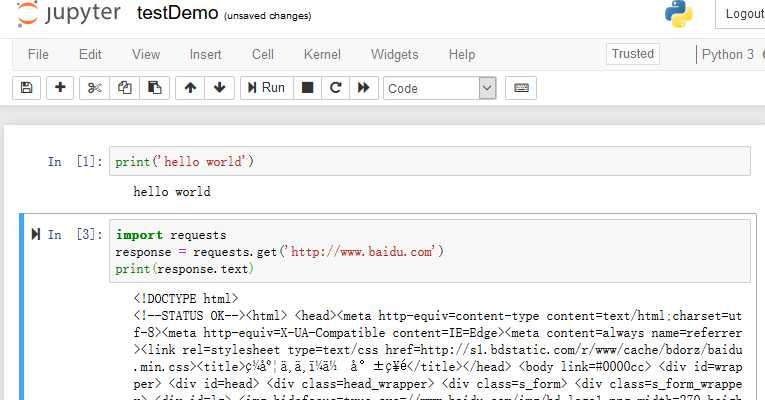
默认的文件名为unite,此处将其改为testDemo,使用快捷键ctrl+回车 运行,按键B跳转至新的编辑行。
标签:文件名 后台运行 app driver user red ons row 必须
原文地址:https://www.cnblogs.com/dadahuan/p/9556706.html