标签:jsb 参数 mtk txt 之间 rtti tag jaf ike
1 public class PartSortMap extends Mapper<LongWritable,Text,Text,Text> { 2 3 public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{ 4 String line = value.toString();//读取一行数据,数据格式为“Apple 201701 30” 5 String str[] = line.split(" ");// 6 //年月当做key值,因为要根据key值设置分区,而Apple+“_”+销量当做value 7 context.write(new Text(str[1]),new Text(str[0] + "_" + str[2])); 8 } 9 }
1 public class PartParttition extends Partitioner<Text, Text> { 2 public int getPartition(Text arg0, Text arg1, int arg2) { 3 String key = arg0.toString(); 4 int month = Integer.parseInt(key.substring(4, key.length())); 5 if (month == 1) { 6 return 1 % arg2; 7 } else if (month == 2) { 8 return 2 % arg2; 9 } else if (month == 3) { 10 return 3 % arg2; 11 }else if (month == 4) { 12 return 4 % arg2; 13 }else if (month == 5) { 14 return 5 % arg2; 15 }else if (month == 6) { 16 return 6 % arg2; 17 }else if (month == 7) { 18 return 7 % arg2; 19 }else if (month == 8) { 20 return 8 % arg2; 21 }else if (month == 9) { 22 return 9 % arg2; 23 }else if (month == 10) { 24 return 10 % arg2; 25 }else if (month == 11) { 26 return 11 % arg2; 27 }else if (month == 12) { 28 return 12 % arg2; 29 } 30 return 0; 31 } 32 }
1 public class PartSortReduce extends Reducer<Text,Text,Text,Text> { 2 class FruitSales implements Comparable<FruitSales>{ 3 private String name;//水果名字 4 private double sales;//水果销量 5 public void setName(String name){ 6 this.name = name; 7 } 8 9 public String getName(){ 10 return this.name; 11 } 12 public void setSales(double sales){ 13 this.sales = sales; 14 } 15 16 public double getSales() { 17 return this.sales; 18 } 19 20 @Override 21 public int compareTo(FruitSales o) { 22 if(this.getSales() > o.getSales()){ 23 return -1; 24 }else if(this.getSales() == o.getSales()){ 25 return 0; 26 }else { 27 return 1; 28 } 29 } 30 } 31 32 public void reduce(Text key, Iterable<Text> values,Context context)throws IOException,InterruptedException{ 33 List<FruitSales> fruitList = new ArrayList<FruitSales>(); 34 35 for(Text value: values) { 36 String[] str = value.toString().split("_"); 37 FruitSales f = new FruitSales(); 38 f.setName(str[0]); 39 f.setSales(Double.parseDouble(str[1])); 40 fruitList.add(f); 41 } 42 Collections.sort(fruitList); 43 44 for(FruitSales f : fruitList){ 45 context.write(new Text(f.getName()),new Text(String.valueOf(f.getSales()))); 46 } 47 } 48 }
1 public class PartSortMain { 2 public static void main(String[] args)throws Exception{ 3 Configuration conf = new Configuration(); 4 //获取运行时输入的参数,一般是通过shell脚本文件传进来。 5 String [] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); 6 if(otherArgs.length < 2){ 7 System.err.println("必须输入读取文件路径和输出路径"); 8 System.exit(2); 9 } 10 Job job = new Job(); 11 job.setJarByClass(PartSortMain.class); 12 job.setJobName("PartSort app"); 13 14 //设置读取文件的路径,都是从HDFS中读取。读取文件路径从脚本文件中传进来 15 FileInputFormat.addInputPath(job,new Path(args[0])); 16 17 //设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中 18 FileOutputFormat.setOutputPath(job,new Path(args[1])); 19 20 21 job.setPartitionerClass(PartParttition.class);//设置自定义partition类 22 job.setNumReduceTasks(12);//设置为partiton数量 23 //设置实现了map函数的类 24 job.setMapperClass(PartSortMap.class); 25 26 //设置实现了reduce函数的类 27 job.setReducerClass(PartSortReduce.class); 28 29 //设置reduce函数的key值 30 job.setOutputKeyClass(Text.class); 31 //设置reduce函数的value值 32 job.setOutputValueClass(Text.class); 33 34 System.exit(job.waitForCompletion(true) ? 0 :1); 35 } 36 }
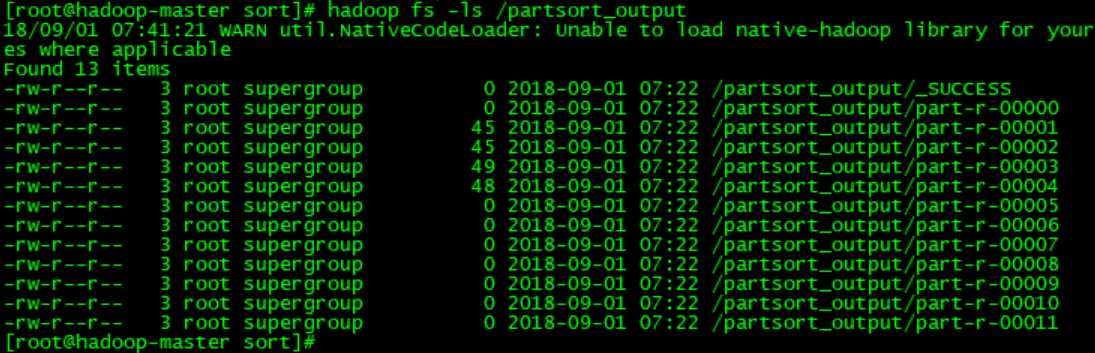

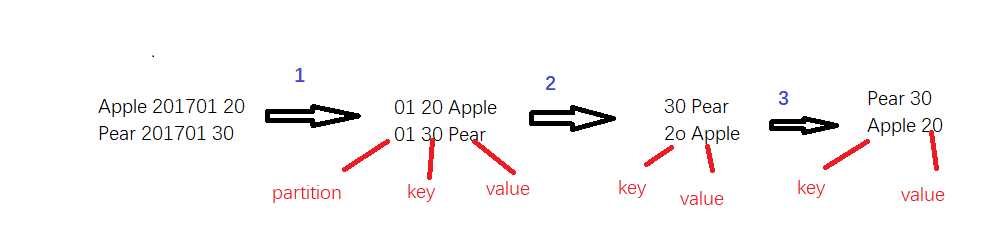
1 #!/usr/bin/python 2 import sys 3 base_numer = 99999 4 for line in sys.stdin: 5 ss = line.strip().split(‘ ‘) 6 fruit = ss[0] 7 yearmm = ss[1] 8 sales = ss[2] 9 new_key = base_number - int(sales) 10 mm = yearmm[4:6] 11 print "%s\t%s\t%s" % (int(mm), int(new_key), fruit)
1 #!/usr/bin/python 2 import sys 3 base_number = 99999 4 for line in sys.stdin: 5 idx_id, sales, fruit = line.strip().split(‘\t‘) 6 new_key = base_number - int(sales) 7 print ‘\t‘.join([val, str(new_key)])
1 set -e -x 2 HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop" 3 STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar" 4 INPUT_FILE_PATH_A="/data/fruit.txt" 5 OUTPUT_SORT_PATH="/output_sort" 6 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH 7 $HADOOP_CMD jar $STREAM_JAR_PATH 8 -input $INPUT_FILE_PATH_A 9 -output $OUTPUT_SORT_PATH 10 -mapper "python map_sort.py" 11 -reducer "python reduce_sort.py" 12 -file ./map_sort.py 13 -file ./red_sort.py 14 -jobconf mapred.reduce.tasks=12 15 -jobconf stream.num.map.output.key.fields=2 16 -jobconf num.key.fields.for.partition=1 17 -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
一起学Hadoop——使用自定义Partition实现hadoop部分排序
标签:jsb 参数 mtk txt 之间 rtti tag jaf ike
原文地址:https://www.cnblogs.com/airnew/p/9574309.html