标签:区域 最大 图片 分享 bubuko 分享图片 方法 重要 界面

梯度是一个向量,它的最重要性质就是指出了函数f在其自变量y增加时最大增长率的方向。
负梯度指出f的最陡下降方向 利用这个性质,可以设计一个迭代方案来寻找函数的最小值。
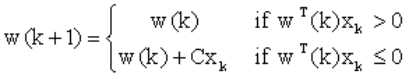
式中的w(k)、xk随迭代次数k而变,是变量。 定义一个对错误分类敏感的准则函数J(w, x)。先任选一个初始权向量w(1),计算准则函数J的梯度,然后从w(1)出发,在最陡方向(梯度方向)上移动某一距离得到下一个权向量w(2) 。
若正确地选择了准则函数J(w,x),则当权向量w是一个解时,J达到极小值(J的梯度为零)。由于权向量是按J的梯度值减小,因此这种方法称为梯度法(最速下降法)。
为了使权向量能较快地收敛于一个使函数J极小的解,C值的选择是很重要的。
若C值太小,则收敛太慢; 若C值太大,则搜索可能过头,引起发散。

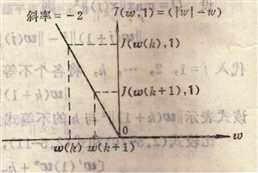


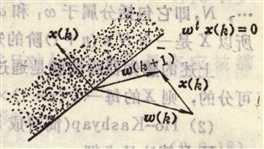
设已由前一步迭代得到w(k)的值。 读入模式样本xk,判别wT(k)xk是否大于0。
在示意图中,xk界定的判别界面为wT(k)xk=0。
当w(k)在判别界面的负区域时, wT(k)xk<0。 校正: w(k+1)= w(k)+ xk ,这里取C=1。 校正后, w(k+1)向量比w(k)向量更接近于模式xk所决定的正区域。
讨论:
若模式是线性可分的,选择合适的准则函数J(w,x),算法就能给出解。 若模式不是线性可分的,算法的结果就会来回摆动,得不到收敛。
作业:
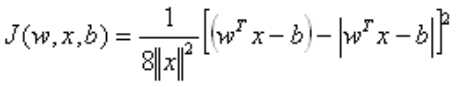
采用梯度法和准则函数 式中实数b>0,试导出两类模式的分类算法。
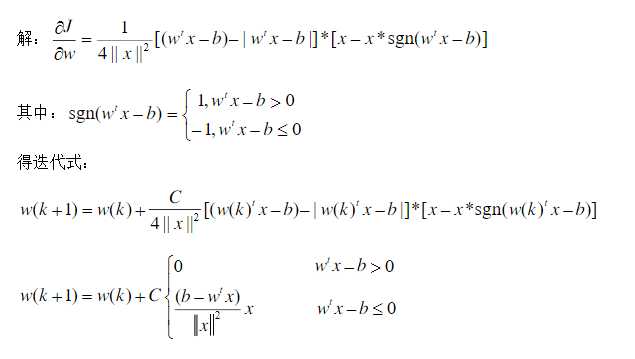
【模式识别与机器学习】——3.8可训练的确定性分类器的迭代算法
标签:区域 最大 图片 分享 bubuko 分享图片 方法 重要 界面
原文地址:https://www.cnblogs.com/chihaoyuIsnotHere/p/9789252.html