标签:NPU iges 中文乱码问题 hold 51cto 自动跳转 重复 正式 没有响应
Web服务的本质2之前讲过这个,在这里:http://blog.51cto.com/steed/2071271
不过当时没讲透,这次再展开一点点。
Web服务的通信本质上就是通过socket发送字符串请求,然后也会返回响应。
发送的请求有请求头和请求体。返回的响应也有响应头和响应体。
格式:请求头和请求体中间使用\r\n\r\n分隔。而请求头之间会使用\r\n来分隔。响应头和响应体类似。
改写一下当时用Socket模拟的Web服务的响应内容。原本返回的是一个响应头和一个响应体。
这次返回301跳转。然后把跳转的url放到另外一个请求头location里。最后再自定义了一个请求头。之前的分隔符都是\r\n。最后用\r\n\r\n表示响应头结束,后面就是响应体,不过301跳转不需要响应体就不写了:
import socket
def handle_request(conn):
data = conn.recv(1024) # 接收数据,随便收到啥我们都回复Hello World
# conn.send(‘HTTP/1.1 200 OK\r\n\r\n‘.encode(‘utf-8‘)) # 响应头以及响应头和响应体之间的分隔符
# conn.send(‘Hello World‘.encode(‘utf-8‘)) # 回复的内容,就是网页的内容,也就是响应体
conn.send(‘HTTP/1.1 301 / Moved Permanently\r\n‘.encode(‘utf-8‘))
conn.send(‘location: http://www.baidu.com\r\n‘.encode(‘utf-8‘))
conn.send(‘MyKey: MyValue\r\n\r\n‘.encode(‘utf-8‘))
def main():
# 先起一个socket服务端
server = socket.socket()
server.bind((‘localhost‘, 8000))
server.listen(5)
# 然后持续监听
while True:
conn, addr = server.accept() # 开启监听
handle_request(conn) # 将连接传递给handle_request函数处理
conn.close() # 关闭连接
if __name__ == ‘__main__‘:
main()上面的socket启动之后,使用浏览器访问,会跳转到指定的页面,并且能在后台查看到自定义的响应头的内容。
再补充一个登录GitHub的示例,这个是Form表单验证的。
GitHub的登录验证使用的是Form表单。
验证登录是否成功可以访问这个页面:https://github.com/settings/profile
如果没有登录,会跳转到登录页面。如果页面正常打开了,并且能读取到里面的用户信息了,说明登录认证成功。代码如下:
import requests
from bs4 import BeautifulSoup
s = requests.Session()
r1 = s.get(‘https://github.com/login‘)
r1.encoding = r1.apparent_encoding
bs1 = BeautifulSoup(r1.text, features=‘html.parser‘)
form = bs1.find(‘form‘)
input_list = form.find_all(‘input‘)
data = {}
for input in input_list:
name = input.attrs.get(‘name‘)
value = input.get(‘value‘) # 和上面的方法效果是一样的
data[name] = value
# 不能把密码上传啊
with open(‘password/s3.txt‘) as f:
auth = f.read()
auth = auth.split(‘\n‘)
data[‘login‘] = auth[0]
data[‘password‘] = auth[1]
r2 = s.post(‘https://github.com/session‘, data=data)
bs2 = BeautifulSoup(r2.text, features=‘html.parser‘)
title = bs2.find(‘title‘)
print(title) # 登录成功返回的页面
r3 = s.get(‘https://github.com/settings/profile‘)
r3.encoding = r3.apparent_encoding # 获取页面的编码,解决乱码问题
bs3 = BeautifulSoup(r3.text, features=‘html.parser‘)
title = bs3.find(‘title‘)
print(title) # 用户信息页面的title
name = bs3.find(‘input‘, id="user_profile_name")
print(name.get(‘value‘)) # 用户的 Name这里讲的对于GitHub这个网站不适用。
一般Form表单验证的页面,如果验证失败会刷新当前页面。如果验证成功,则会发一个跳转。如果是跳转的机制,就可以通过这个来判断是否验证成功了。
关于重定向返回的响应内容,上面Web服务的本质2里已经演示的很清楚了。
可以判断返回的状态码,重定向的状态码是301或302:
print(response.status_code)另外重定向除了状态码,还有一个location,指向跳转的地址:
location = response.headers.get(‘location‘) # 跳转的url会在location里有了location不但能判断是否验证成功了,还能知道下一步默认该往哪里发送请求。
Web登录地址:https://wx.qq.com/
页面打开后,会显示一个二维码,需要我们有手机微信扫一下。手机授权后,页面会自动跳转完成登录。这里虽然没有我们在浏览器上操作,但是一旦手机授权后,页面就会自动跳转。这里是用长轮训的方法持续想服务器提交请求,直到收到服务器返回后执行后会的操作。
先看一下长轮询在后台的请求: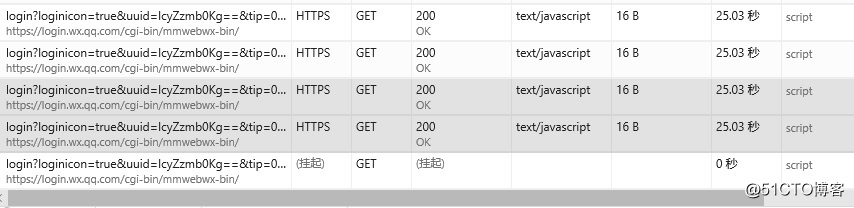
长轮询:客户端向服务器发送Ajax请求,服务器接到请求后hold住连接,直到有新消息才返回响应信息并关闭连接,客户端处理完响应信息后再向服务器发送新的请求。
优点:在无消息的情况下不会频繁的请求,耗费资源小。
缺点:服务器hold连接会消耗资源,返回数据顺序无保证,难于管理维护。
实例:WebQQ、Hi网页版、Facebook IM。
合理选择“心跳”频率:
这里必须由客户端不停地进行请求来维持,所以在客户端和服务器间保持正常的“心跳”至为关键,间隔时间应小于WEB服务器的超时时间,一般建议在10~20秒左右。上面的截图里是25秒。
长轮训是在服务端做的,客户端只需要用个尾递归不停的调用自己发送get请求,get请求是阻塞的,服务器返回之前都会等在那里。拿到回复的数据后,再分析一下是调用自己递归还是进入下一步处理。
二维码就是要扫描的图片,可以轻松的从前端代码里找到img标签,也可以在后台调试工具的网络部分找到图片的URL,大概的样子如下:
https://login.weixin.qq.com/qrcode/xxxxxxxxxx==这里可以看到关键URL最后的那部分,这部分参数之后就叫uuid。
但是用爬虫直接爬 https://wx.qq.com/ 页面的时候,返回的img标签里找不到这个关键的uuid。事实上哪里都没找到。uuid是通过另外一个get请求获取到的,请求的URL如下:
https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_=1539869227976这个请求返回的uuid会在响应体力,但是在Edge的后台显示是没有响应体的,可能是没有没有解析成功。用google浏览器的话应该是能看到返回的数据的。get请求的所有参数里,这里只需要修改一个最后的时间戳,注意下时间戳的位数,这里乘了1000。
下面是请求二维码图片,然后下载图片的代码:
import requests
import time
import re
s = requests.Session()
params = {
‘appid‘: ‘wx782c26e4c19acffb‘,
‘redirect_uri‘: ‘https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxnewloginpage‘,
‘fun‘: ‘new‘,
‘lang‘: ‘zh_CN‘,
‘_‘: int(time.time() * 1000)
}
r1 = s.get(‘https://login.wx.qq.com/jslogin‘, params=params)
print(r1.text)
uuid = re.findall(‘window.QRLogin.uuid = "(.*)"‘, r1.text)
uuid = uuid[0]
print(uuid)
r2 = s.get(‘https://login.weixin.qq.com/qrcode/‘ + uuid)
with open(‘%s.jpeg‘ % uuid, ‘wb‘) as f:
f.write(r2.content)之后就是不停的发送那个长轮训请求了。
如果超时,服务器会返回408状态码。这时就要再继续发请求。
手机扫码后则会返回201状态码,并且还有微信的头像。这时就可以处理头像了。头像的图片是base64编码的,网上找一下就有转码的方法,如果是写前端,直接把这段编码设置为img标签的src属性就行了。
接着上面的编码:
r = 1541893233750 - time.time() * 1000
params = {
‘loginicon‘: ‘true‘,
‘uuid‘: uuid,
‘tip‘: ‘0‘,
‘r‘: r,
‘_‘: time.time() * 1000
}
while True:
r3 = s.get(‘https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login‘, params=params)
print(r3.text)
code = re.findall("window.code=(\d\d\d)", r3.text)
code = code[0]
if code == ‘201‘:
userAvatar = re.findall("window.userAvatar = ‘(.*)‘;", r3.text)
userAvatar = userAvatar[0]
break
# 每次请求只是自增1,这样就和准确的时间有误差了
# 应该是用这个来控制长时间不扫码,服务器就会拒绝请求
params[‘_‘] += 1
# 是什么不知道,但是每次都是按时间戳的1000倍减少的
params[‘r‘] = 1541893233750 - time.time() * 1000
# base64转码生成头像的图片
import base64
strs = userAvatar.replace("data:img/jpg;base64,", "")
imgdata = base64.b64decode(strs)
with open(‘头像.jpg‘, ‘wb‘) as f:
f.write(imgdata)拿到了头像之后,仍然会进入一个发送长轮训的阶段,等待手机再点一下登录授权。现在的这个长轮训和之前的长轮训是一样的,也就是上面的代码不需要退出while循环,而是在判断返回的code是201的时候,拿到头像,然后还是继续循环发送长轮询,等手机再点一下完成登录授权后,返回的code是200,此就可以退出while循环了。
上面的代码修改一下:
r = 1541893233750 - time.time() * 1000
params = {
‘loginicon‘: ‘true‘,
‘uuid‘: uuid,
‘tip‘: ‘0‘,
‘r‘: r,
‘_‘: time.time() * 1000
}
code = ‘408‘
r3 = None
while code == ‘408‘:
r3 = s.get(‘https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login‘, params=params)
print(r3.text)
code = re.findall("window.code=(\d\d\d)", r3.text)
code = code[0]
if code == ‘201‘:
userAvatar = re.findall("window.userAvatar = ‘(.*)‘;", r3.text)
userAvatar = userAvatar[0]
import base64
strs = userAvatar.replace("data:img/jpg;base64,", "")
imgdata = base64.b64decode(strs)
with open(‘头像.jpg‘, ‘wb‘) as f:
f.write(imgdata)
# 201收到响应之后,继续发送长轮询
params[‘_‘] += 1
params[‘r‘] = 1541893233750 - time.time() * 1000
r3 = s.get(‘https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login‘, params=params)
code = re.findall("window.code=(\d\d\d)", r3.text)
code = code[0]
# 每次请求只是自增1,这样就和准确的时间有误差了
# 应该是用这个来控制长时间不扫码,服务器就会拒绝请求
params[‘_‘] += 1
# 是什么不知道,但是每次都是按时间戳的1000倍减少的
params[‘r‘] = 1541893233750 - time.time() * 1000
print(r3.text)
redirect_uri = re.findall("window.redirect_uri=\"(.*)\";", r3.text)[0]
print(redirect_uri)之后返回code是408才继续长轮训,返回201,则收下头像的图片然后再发起一次长轮训(这部分代码有点重复,不过保证示例的整个过程清晰)。返回其他的code否退出循环,这里正常会返回200。
上面的步骤最后会拿到一个 redirect_uri ,值是一个url,可以直接访问。不同实际在浏览器收到200返回码之后发的请求的url有点小区别:
"https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxnewloginpage?ticket=XXXXXXXXXXXXOOOOOOOOOOOO@qrticket_0&uuid=XXXXXXXXXX==&lang=zh_CN&scan=153xxxx221"
"https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxnewloginpage?ticket=XXXXXXXXXXXXOOOOOOOOOOOO@qrticket_0&uuid=XXXXXXXXXX==&lang=zh_CN&scan=153xxxx221&fun=new&version=v2"实际浏览器发送的请求会多两个参数,
如果用默认的 redirect_uri 发送请求,返回的是一个html,这个应该是Web微信的界面,但是不带任何数据,原因就是没有认证信息。
如果加上上面额外的参数,则收到的信息像下面这个样子:
<error>
<ret>0</ret>
<message></message>
<skey>@crypt_d1544694_9eb666666b490ff4444c94ab4444f0d2</skey>
<wxsid>tMlup2XXXXXX0pIp</wxsid>
<wxuin>1112345678</wxuin>
<pass_ticket>mFJdwSibpJ5R%2FbQ564HXXXXXOOOOO%2FEiEO86KPL3EI6F2poriL4OOOOOOXXXXXX%2B</pass_ticket>
<isgrayscale>1</isgrayscale>
</error>上面这个就是XML格式的凭证,之后基于登录后的操作,都要带着凭证提交。类似Cookie,但是这里不用Cookie而是用这个。这里把XML也用BeautifulSoup解析一下,把凭证里所有的 key 、 value 保存为一个字典。
再发一次请求,redirect_uri 里加上2个参数。然后把返回的拼接解析后转成字典打印出来:
params = {
‘fun‘: ‘new‘,
‘version‘: ‘v2‘
}
r4 = s.get(redirect_uri, params=params)
print(r4.text)
soup = BeautifulSoup(r4.text, features=‘html.parser‘)
target = soup.find(‘error‘)
ticket = {}
for item in target.children:
ticket[item.name] = item.text
print(ticket)到此登录告一段落,把最后的凭证保存好
在浏览器开发者模式的网络分页里,可以找到如下紧挨着的3个请求:
请求的代码如下,拿到请求后要转一下编码,否则是乱码:
url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit"
params = {
# ‘r‘: ‘1976951002‘, # 这是什么不知道,不加也没问题
‘lang‘: ‘zh_CN‘,
‘pass_ticket‘: ticket[‘pass_ticket‘],
}
json_data = {"BaseRequest": {
"Uin": ticket[‘wxuin‘],
"Sid": ticket[‘wxsid‘],
"Skey": ticket[‘skey‘],
"DeviceID": "e189955857229638",
}}
r5 = s.post(url, params=params, json=json_data)
r5.encoding = r5.apparent_encoding
print(r5.apparent_encoding)
print(r5.text)从返回的信息里看,有部分最近订阅号和最近联系人的信息。数据都是以JSON字符串的形式返回的。之后再继续分析和处理之前,先执行一步 jso.loads(r5.text) 反序列化转成对象。
可用生成一个html来展示:
# 把页面的内容生成一个html来展示
import json
obj = json.loads(r5.text)
user = obj[‘User‘]
f = open(‘wx.html‘, ‘w‘, encoding=‘utf-8‘)
f.write(‘<meta charset="UTF-8">\n‘)
f.write("<h1>Web 微信</h1>\n")
f.write("<h3>用户名:%s</h3>\n" % user[‘NickName‘])
contactList = obj[‘ContactList‘]
f.write("<h3>最近联系人</h3>\n")
f.write("<ul>\n")
for i in contactList:
# print(i)
user_info = i[‘RemarkName‘] or i[‘NickName‘]
if i[‘Sex‘]:
sex = "男" if i[‘Sex‘] == 1 else "女"
user_info = "%s(%s)" % (user_info, sex)
if i[‘Signature‘]:
user_info = "%s: %s" % (user_info, i[‘Signature‘])
f.write("<li>%s</li>\n" % user_info)
f.write("</ul>\n")
mpSubscribeMsgList = obj[‘MPSubscribeMsgList‘]
f.write("<h3>最近公众号信息</h3>\n")
f.write("<ul>\n")
for i in mpSubscribeMsgList:
# print(i)
f.write("<li>%s</li>\n" % i[‘NickName‘])
f.write("<ul>\n")
for article in i[‘MPArticleList‘]:
f.write("<li><a href=‘%s‘>%s</a></br>%s</li>\n" % (article[‘Url‘], article[‘Title‘], article[‘Digest‘]))
f.write("</ul>\n")
f.write("</ul>\n")
f.close()这里拿到的信息只是概况,联系人和公众号都不全,都是最近的联系人。
另外信息里面还有头像和公众号文章的图片,下载没问题,但是要在html里用img标签写src是显示不出来的。做了外链限制
继续在浏览器开发者模式的网络分页里找,在凭证的后面是上面的POST的初始化请求webwxinit。继续往后找,主要看响应体,有很多图片的请求是可以跳过的,都是下载头像之类的。找到返回内容最长的那个应该就是联系人列表了。另外还有一个返回的内容也很多,可能是公众号,不过这里不管那个了。
获取联系人列表的代码:
# 获取所有联系人信息,这个请求是会验证cookie的
url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact"
params = {
‘pass_ticket‘: ticket[‘pass_ticket‘],
‘r‘: int(time.time() * 1000),
‘seq‘: ‘0‘,
‘skey‘: ticket[‘skey‘]
}
r6 = s.get(url, params=params)
# r6.encoding = r6.apparent_encoding # apparent_encoding 自动获取到的编码是错的
# print(r6.apparent_encoding)
r6.encoding = "utf-8" # 直接指定"utf-8"就对了
# 自动获取到的编码是"Windows-1254"这个是别名,正式名称是"cp1254"。
# 写哪个都一样的,不过问题是,不能用,编码是错的,大概就是误导我们的
# Python36/Lib/encodings/aliases.py 这个文件里有所有编码的别名的对应关系
print(r6.text)
with open(‘contact.txt‘, ‘w‘, encoding=‘utf-8‘) as f:
f.write(r6.text)这里有几个坑:
之后先要分析一波联系人,把返回的内容先保存到本地,之后不用再反复去请求了。
对文件的内容解析,先看下有哪些字段:
import json
with open(‘contact.txt‘, encoding=‘utf-8‘) as f:
obj = json.load(f)
for i in obj:
print(i)一共就4个key:
进行到这里,已经对自己所有的联系人进行一波统计分析了。比如男女比例,地区分布。不过数据分析不是这里的重点
到这里就不一点点分析了,下面的代码,就能发消息了(中文还有问题):
# 找到联系人信息
name = "这里填联系人的名字"
msg = "Hello" # 发中文会有乱码,不过这个是json序列化的问题
to_user_obj = None
obj = json.loads(r6.text)
for member in obj[‘MemberList‘]:
if name in member["NickName"] or name == member["RemarkName"]:
to_user_obj = member
break
if to_user_obj:
print(to_user_obj["Signature"])
else:
to_user_obj = user
print("未找到联系人")
# 发消息
url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxsendmsg"
params = {
‘lang‘: ‘zh_CN‘,
‘pass_ticket‘: ticket[‘pass_ticket‘],
}
# 这个字典之前用过,之前里面只有BaseRequest
# 现在保留BaseRequest,还要加上Msg
time_stamp = time.time() * 1000
json_data[‘Msg‘] = {
‘ClientMsgId‘: time_stamp,
‘Content‘: msg,
‘FromUserName‘: user["UserName"], # 之前获取用户信息里拿到的
‘LocalID‘: time_stamp,
‘ToUserName‘: to_user_obj["UserName"],
‘Type‘: 1, # 这个是消息类型,1是文本
}
json_data[‘Scene‘] = 0 # 不知道是啥,照着写
r7 = s.post(url=url, params=params, json=json_data)
print(r7.text)中文乱码问题
如果发送“你好”,对方会收到“\u4f60\u597d”,这个是中文的Unicode编码,是在json.dumps里变的:
>>> import json
>>> json.dumps("你好")
‘"\\u4f60\\u597d"‘
>>> json.dumps("Hello")
‘"Hello"‘
>>> json.dumps("你好", ensure_ascii=False)
‘"你好"‘
>> 中文在json序列化的时候,默认会转成Unicode,不过可以加上ensure_ascii参数不转。
之前自己做写django项目的时候,如果客户端 josn.dumps 了,服务端再 json.loads 一下,中文就回来了。现在服务端是人家的,只能让客户端不要对中文进行转码
自己做json序列化就不能把参数传给json了,否则还会把json字符串再序列化一次。data参数和json参数都是请求体,传给json参数后,原本requests会帮我做一些事情,现在要自定义就得自己调整了。把自己序列化后的字符串传给data,data就原样接收了。但是要让服务端把请求体(body)的内容作为json字符串处理。修改请求头的 ‘Content-Type‘ 的值。改一下之前的POST请求:
# r7 = s.post(url=url, params=params, json=json_data) # 这个不能发中文
headers = s.headers
headers[‘Content-Type‘] = ‘application/json‘
data = json.dumps(json_data, ensure_ascii=False).encode(‘utf-8‘)
r7 = s.post(url=url, params=params, headers=headers, data=data)上面在传参给data之前还要还要 data.encode(‘utf-8‘) 处理一下,否则会报错。如果直接给字符串的话,最终会执行 body.encode("latin-1") ,这个编译不了,所以就报错了,错误信息会有提示。另外参考下面requests里的这小段代码,json序列化之后,也是把字符串用encode转成bytes类型的。所以直接给bytes类型。
if not data and json is not None:
# urllib3 requires a bytes-like body. Python 2‘s json.dumps
# provides this natively, but Python 3 gives a Unicode string.
content_type = ‘application/json‘
body = complexjson.dumps(json)
if not isinstance(body, bytes):
body = body.encode(‘utf-8‘)下面是发送成功后返回的消息:
{
"BaseResponse": {
"Ret": 0,
"ErrMsg": ""
},
"MsgID": "9025779609933123936",
"LocalID": "1540098759694.243"
}还是看浏览器开发者模式的网络分页,里面还是会有一个长轮训。不过实际上没那么简单,这里至少要处理2个请求。一个是长轮训请求,会有2种返回状态:
消息同步的POST请求会接收收到的消息,也可能是0条消息,但是还是得同步一次,否则长轮训会一直返回2。另外最初的 SyncKey 只有4个,在 POST 之后还会多2个,最好也更新到之后的请求里。
另外消息发送人和接收人,收到的都是一串类似id的东西,这个要去之前的联系人列表里查找 "UserName" 然后获取 "NickName" 。这里没做,只是简单的把发送人的id打印出来了。这个id不是固定的,每次连接web微信,返回的联系人列表的id都不一样。
接收消息的代码如下:
# 收消息
url = "https://webpush.wx.qq.com/cgi-bin/mmwebwx-bin/synccheck"
sync_key = json.loads(r5.text)["SyncKey"]
params = {
‘skey‘: ticket[‘skey‘],
‘sid‘: ticket[‘wxsid‘],
‘uin‘: ticket[‘wxuin‘],
‘deviceid‘: ‘e941046347280021‘, # 这个一直在变,貌似没啥影响
‘_‘: int(time.time() * 1000) - 26846,
}
print("持续接收消息")
while True:
sync_key_list = []
for item in sync_key["List"]:
sync_key_list.append("%s_%s" % (item["Key"], item["Val"]))
synckey = "|".join(sync_key_list)
params_update = {
‘synckey‘: synckey,
‘_‘: params[‘_‘] + 1,
‘r‘: int(time.time() * 1000),
}
params.update(params_update)
print("发起 r8 长轮训")
try:
r8 = s.get(url=url, params=params)
print(r8.text)
except requests.exceptions.ConnectionError as e:
print("捕获到异常")
params[‘_‘] -= 1
continue
# 返回 ‘window.synccheck={retcode:"0",selector:"0"}‘ 则继续长轮训
# 返回 ‘window.synccheck={retcode:"0",selector:"2"}‘ 则发起POST
if r8.text == ‘window.synccheck={retcode:"0",selector:"2"}‘:
print("POST同步:webwxsync")
sync_url = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxsync"
sync_params = {
‘lang‘: ‘zh_CN‘,
‘skey‘: ticket[‘skey‘],
‘sid‘: ticket[‘wxsid‘],
‘pass_ticket‘: ticket[‘pass_ticket‘],
}
json_data["SyncKey"] = json.loads(r5.text)["SyncKey"] # 在之前r5的基础上加一个SyncKey字典
r9 = s.post(sync_url, params=sync_params, json=json_data)
# r9.encoding = r9.apparent_encoding
print(r9.apparent_encoding) # 自动获取到的编码还是有问题
r9.encoding = ‘utf-8‘
# print(r9.text)
r9_obj = json.loads(r9.text)
add_msg_count = r9_obj[‘AddMsgCount‘]
print("你有 %s 条消息" % add_msg_count)
add_msg_list = r9_obj[‘AddMsgList‘]
for add_msg in add_msg_list:
content = add_msg["Content"]
from_user_name = add_msg["FromUserName"]
print(content, "<==", from_user_name)
sync_key = json.loads(r9.text)["SyncKey"] # 这里会多2条SyncKey这里还有个坑,如果代码运行起来之后,马上就有消息进来(对方回复的太快),我测的时候会发生异常。也没找到啥原因,而且如果是等一下再有消息来跑着也很正常。最后就用try把异常捕获处理了。
另外消息数量会累加,可能还有一个已读消息的请求,这个没有继续深入。
标签:NPU iges 中文乱码问题 hold 51cto 自动跳转 重复 正式 没有响应
原文地址:http://blog.51cto.com/steed/2307177