标签:链接 code nod blog ODB 正文 ges red water
摘要: 有一个业务是查询最新审核的5条数据``sql SELECTid,titleFROMth_contentWHEREaudit_time< 1541984478 ANDstatus= ‘ONLINE‘ ORDER BYaudit_time` D.
原来链接 https://mengkang.net/1302.html
有一个业务是查询最新审核的5条数据
SELECT id, title
FROM th_content
WHERE audit_time < 1541984478
AND `status` = ‘ONLINE‘ORDER BY audit_time DESC, id DESC
LIMIT 5;
查看当时的监控情况 cpu 使用率是超过了100%,show processlist看到很多类似的查询都是处于create sort index的状态。
查看该表的结构
CREATE TABLE th_content (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
title varchar(500) CHARACTER SET utf8 NOT NULL DEFAULT ‘‘ COMMENT ‘内容标题‘,
content mediumtext CHARACTER SET utf8 NOT NULL COMMENT ‘正文内容‘,
audit_time int(11) unsigned NOT NULL DEFAULT ‘0‘ COMMENT ‘审核时间‘,
last_edit_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘最近编辑时间‘,
status enum(‘CREATED‘,‘CHECKING‘,‘IGNORED‘,‘ONLINE‘,‘OFFLINE‘) CHARACTER SET utf8 NOT NULL DEFAULT ‘CREATED‘ COMMENT ‘资讯状态‘,
PRIMARY KEY (id),
KEY idx_at_let (audit_time,last_edit_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
索引有一个audit_time在左边的联合索引,没有关于status的索引。
分析上面的sql执行的逻辑:
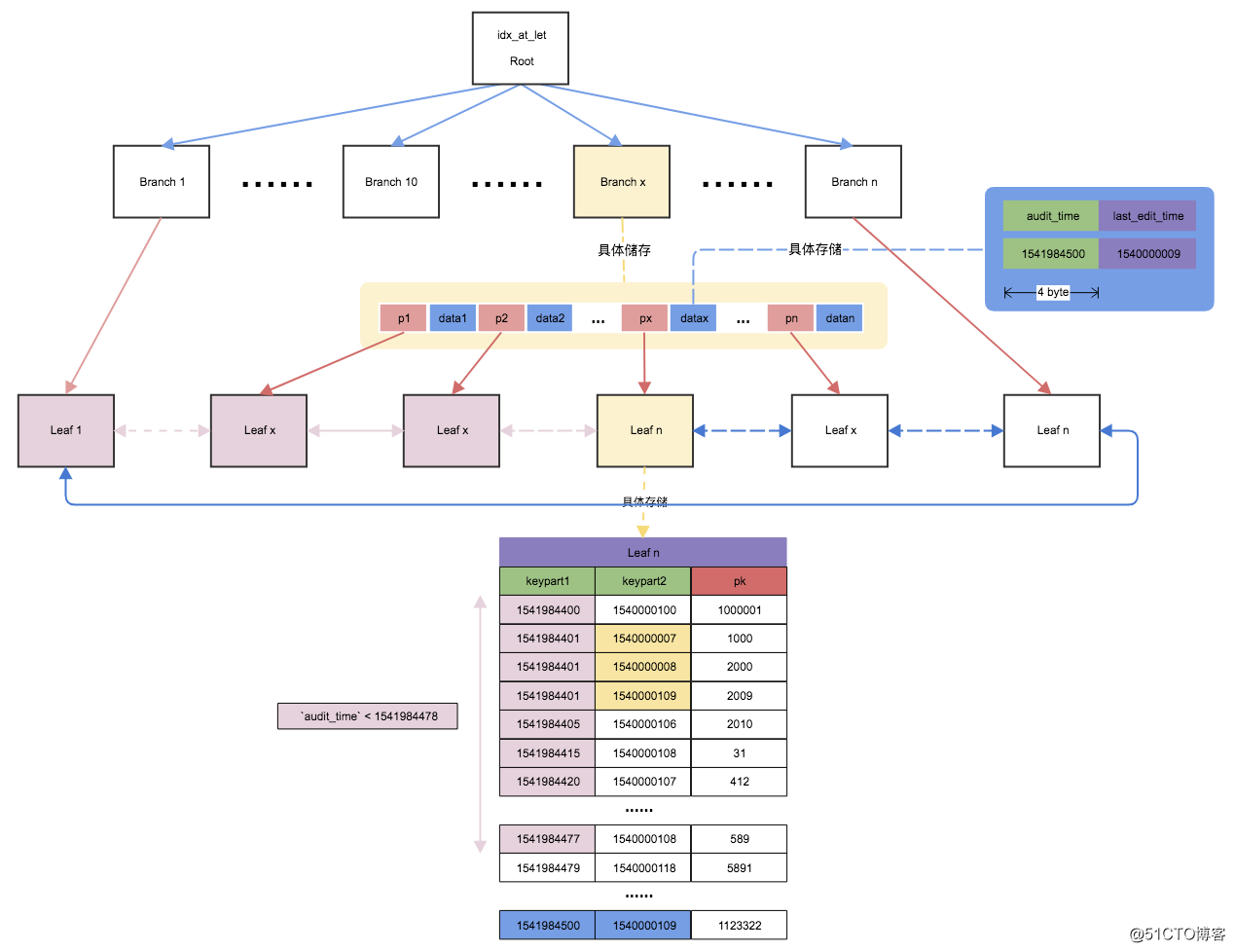
从联合索引里找到所有小于该审核时间的主键id(假如在该时间戳之前已经审核了100万条数据,则会在联合索引里取出对应的100万条数据的主键 id)
对这100万个 id 进行排序(为的是在下面一步回表操作中优化 I/O 操作,因为很多挨得近的主键可能一次磁盘 I/O 就都取到了)
回表,查出100万行记录,然后逐个扫描,筛选出status=‘ONLINE‘的行记录
最后对查询的结果进行排序(假如有50万行都是ONLINE,则继续对这50万行进行排序)
最后因为数据量很大,虽然只取5行,但是按照我们刚刚举的极端例子,实际查询了100万行数据,而且最后还在内存中进行了50万行数据库的内存排序。
所以是非常低效的。
画了一个示意图,说明第一步的查询过程,粉红色部分表示最后需要回表查询的数据行。
图中我按照索引存储规律来YY伪造填充了一些数据,如有不对请留言指出。希望通过这张图大家能够看到联合索引存储的方式和索引查询的方式
改进思路 1
范围查找向来不太好使用好索引的,如果我们增加一个audit_time, status的联合索引,会有哪些改进呢?
ALTER TABLE th_content ADD INDEX idx_audit_status (audit_time, status);
mysql> explain select id, title from th_content where audit_time < 1541984478 and status = ‘ONLINE‘ order by audit_time desc, id desc limit 5;
+----+-------------+------------+-------+------------------------------------------+------------------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+------------------------------------------+------------------+---------+------+--------+-------------+
| 1 | SIMPLE | th_content | range | idx_at_ft_pt_let,idx_audit_status | idx_audit_status | 4 | NULL | 209754 | Using where |
+----+-------------+------------+-------+------------------------------------------+------------------+---------+------+--------+-------------+
细节:因为audit_time是一个范围查找,所以第二列的索引用不上了,只能用到audit_time,所以key_len是4。而下面思路2中,还是这两个字段key_len则是5。
还是分析下在添加了该索引之后的执行过程:
从联合索引里找到小于该审核时间的audit_time最大的一行的联合索引
然后依次往下找,因为< audit_time是一个范围查找,而第二列索引的值是分散的。所以需要依次往前查找,匹配出满足条件(status=‘ONLINE‘)的索引行,直到取到第5行为止。
回表查询需要的具体数据
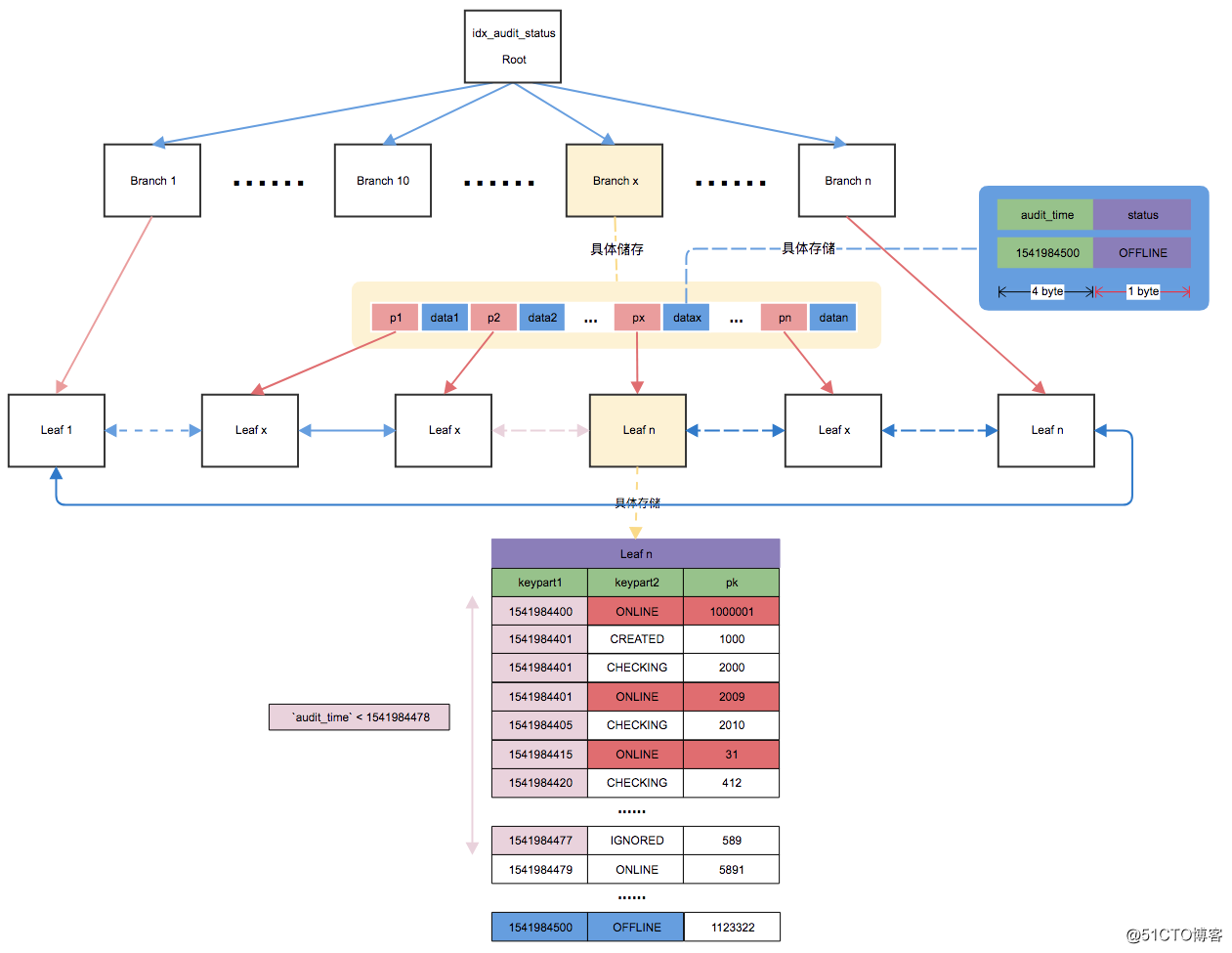
在上面的示意图中,粉红色标识满足第一列索引要求的行,依次向前查询,本个叶子节点上筛选到了3条记录,然后需要继续向左,到前一个叶子节点继续查询。直到找到5条满足记录的行,最后回表。
改进之处
因为在索引里面有status的值,所以在筛选满足status=‘ONLINE‘行的时候,就不用回表查询了。在回表的时候只有5行数据的查询了,在iops上会大大减少。
该索引的弊端
如果idx_audit_status里扫描5行都是status是ONLINE,那么只需扫描5行;
如果idx_audit_status里扫描前100万行中,只有4行status是ONLINE,则需要扫描100万零1行,才能得到需要的5行记录。索引需要扫描的行数不确定。
改进思路 2
ALTER TABLE th_content DROP INDEX idx_audit_status;
ALTER TABLE th_content ADD INDEX idx_status_audit (status, audit_time);
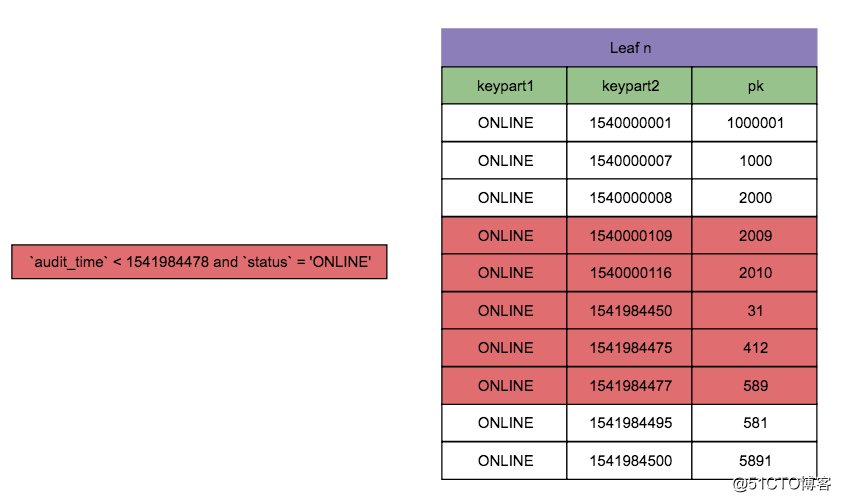
这样不管是排序还是回表都毫无压力啦。
一个案例彻底弄懂如何正确使用 mysql inndb 联合索引
标签:链接 code nod blog ODB 正文 ges red water
原文地址:http://blog.51cto.com/14031893/2320083