标签:src 存储 字符 定制 tps 子模块 获取 geturl .com
概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求。其常被用到的子模块在Python3中的为urllib.request和urllib.parse,在Python2中是urllib和urllib2。
使用流程:

---
# 爬取搜狗首页的页面数据 import urllib.request # 1.指定url url = ‘https://www.sogou.com/‘ #2.发起请求:urlopean可以根据指定的url发起请求,且返回一个响应对象 response = urllib.request.urlopen(url=url) #3.获取页面数据:read函数返回的就是响应对象中存储的页面数据(byte)-二进制形式 page_text = response.read() #print(page_text) #4.持久化存储 with open(‘./sogou.html‘,‘wb‘)as f: f.write(page_text) print(‘写入数据成功‘)
urlopen函数原型: urllib.request.urlopen(url, data=None, timeout=<object object at 0x10af327d0>, *, cafile=None, capath=None, cadefault=False, context=None) 在上述案例中我们只使用了该函数中的第一个参数url。在日常开发中,我们能用的只有url和data这两个参数。 url参数:指定向哪个url发起请求 data参数:可以将post请求中携带的参数封装成字典的形式传递给该参数(暂时不需要理解,后期会讲) urlopen函数返回的响应对象,相关函数调用介绍: response.headers():获取响应头信息 response.getcode():获取响应状态码 response.geturl():获取请求的url response.read():获取响应中的数据值(字节类型)
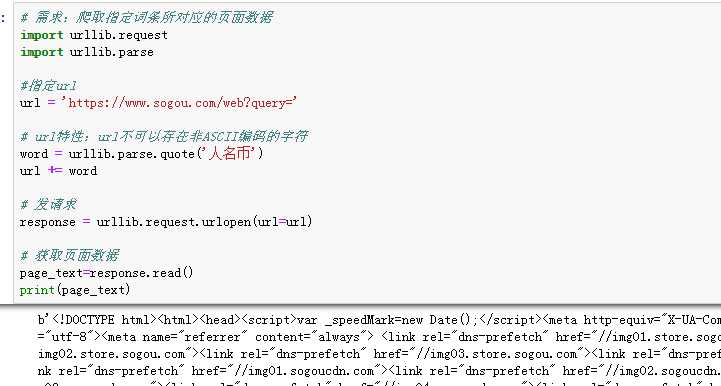
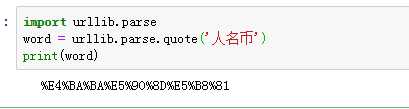
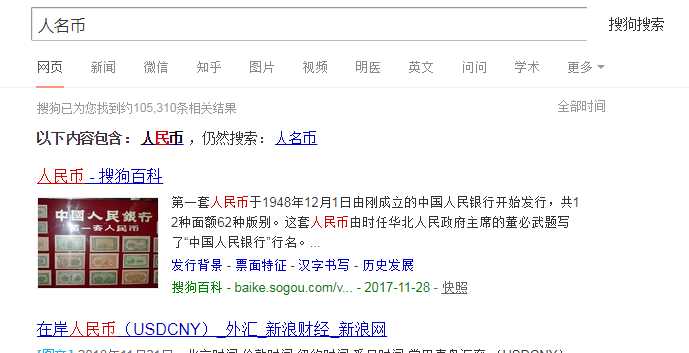
# 需求:爬取指定词条所对应的页面数据 import urllib.request import urllib.parse #指定url url = ‘https://www.sogou.com/web?query=‘ # url特性:url不可以存在非ASCII编码的字符 word = urllib.parse.quote(‘人名币‘) url += word # 发请求 response = urllib.request.urlopen(url=url) # 获取页面数据 page_text=response.read() # print(page_text) #4.持久化存储 with open(‘rmb.html‘,‘wb‘)as f: f.write(page_text) print(‘写入数据成功‘)
双击rmb.html出现页面:
网站检查请求的UA,如果发现UA是爬虫程序,则拒绝提供网站数据
- User-Agent(UA):请求载体的身份标识
- 反反爬机制:伪装爬虫程序请求的UA--如何通过代码实现
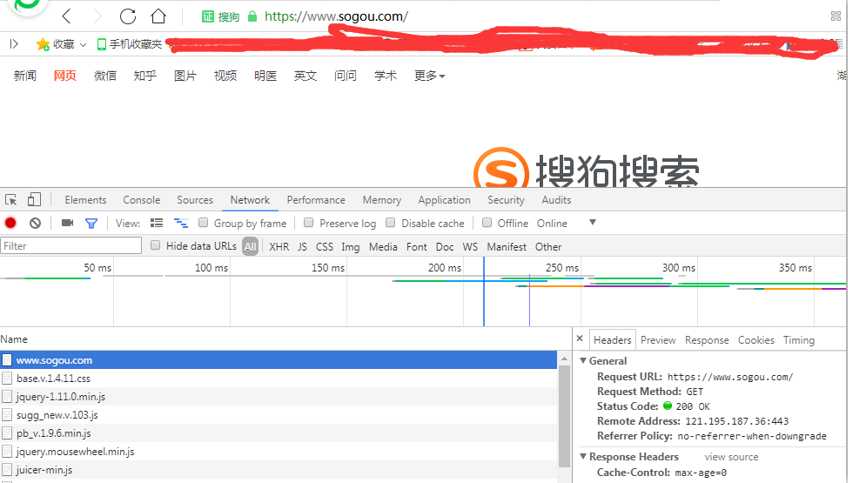
在百度浏览器下点击F12
然后输入www.sogou.com
------------------------
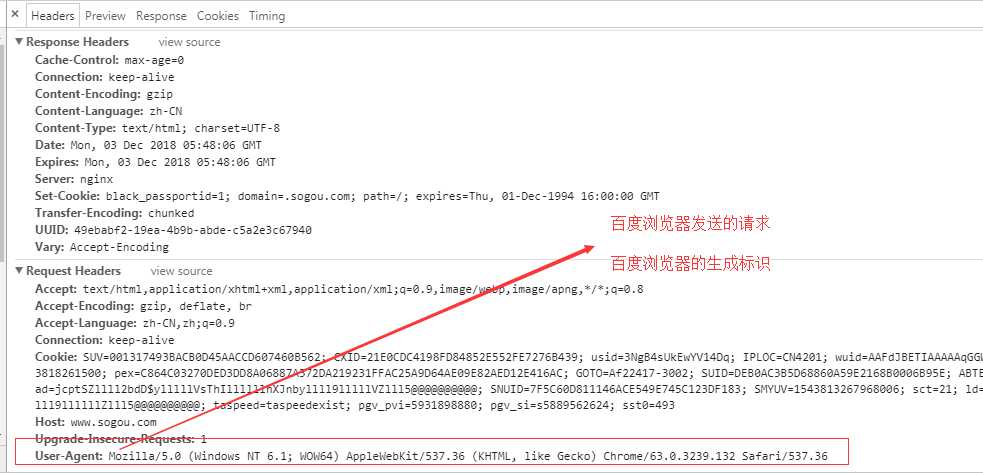
import urllib.request #被访问的搜狗网页 url = ‘https://www.sogou.com/‘ # UA伪装 #1.自制定一个请求对象 #存储任意的请求头信息 # 此处用的百度的UA headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘} #该请求对象的UA进行了成功的伪装 request = urllib.request.Request(url=url,headers=headers) # 2.针对自定制的请求发起请求 response = urllib.request.urlopen(request) print(response.read())
标签:src 存储 字符 定制 tps 子模块 获取 geturl .com
原文地址:https://www.cnblogs.com/foremostxl/p/10058146.html