标签:setdaemon 总数 传输 odi pca parse top 环境 build
1.最基本的抓站
import urllib2 content = urllib2.urlopen(‘http://XXXX‘).read()
2.使用代理服务器
这在某些情况下比较有用,比如IP被封了,或者比如IP访问的次数受到限制等等。
|
1 2 3 4 5 |
|
3.1`需要登录的情况 cookie 表单
import urllib postdata=urllib.urlencode({ ‘username‘:‘XXXXX‘, ‘password‘:‘XXXXX‘, ‘continueURI‘:‘http://www.verycd.com/‘, ‘fk‘:fk, ‘login_submit‘:‘登录‘ })
3.2伪装浏览器
import urllib2 import random url = "http://www.itcast.cn" #注意是列表 ua_list = [ "Mozilla/5.0 (Windows NT 6.1; ) Apple.... ", "Mozilla/5.0 (X11; CrOS i686 2268.111.0)... " ] #随机选择 user_agent = random.choice(ua_list) request = urllib2.Request(url) #也可以通过调用Request.add_header() 添加/修改一个特定的header request.add_header("User-Agent", user_agent) # 第一个字母大写,后面的全部小写 request.get_header("User-agent") response = urllib2.urlopen(req) html = response.read() print html
3.3反‘反盗链’
某些站点有所谓的反盗链设置,其实说穿了很简单,就是检查你发送请求的header里面,referer站点是不是他自己,所以我们只需要像3.3一样,把headers的referer改成该网站即可,以黑幕著称地cnbeta为例:
|
1 2 3 |
|
4.多线程并发抓取
单线程太慢的话,就需要多线程了,这里给个简单的线程池模板 这个程序只是简单地打印了1-10,但是可以看出是并发地。
队列还要加强学习
from threading import Thread from Queue import Queue from time import sleep #q是任务队列 #NUM是并发线程总数 #JOBS是有多少任务 q = Queue() NUM = 2 JOBS = 10 #具体的处理函数,负责处理单个任务 def do_somthing_using(arguments): print arguments #这个是工作进程,负责不断从队列取数据并处理 def working(): while True: arguments = q.get() do_somthing_using(arguments) sleep(1) q.task_done() #fork NUM个线程等待队列 for i in range(NUM): t = Thread(target=working) t.setDaemon(True) t.start() #把JOBS排入队列 for i in range(JOBS): q.put(i) #等待所有JOBS完成 q.join()
5.验证码的处理
碰到验证码咋办?这里分两种情况处理:
1、google那种验证码,凉拌
2、简单的验证码:字符个数有限,只使用了简单的平移或旋转加噪音而没有扭曲的,这种还是有可能可以处理的,一般思路是旋转的转回来,噪音去掉,然后划分单个字符,划分好了以后再通过特征提取的方法(例如PCA)降维并生成特征库,然后把验证码和特征库进行比较。这个比较复杂
6 gzip/deflate支持
现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以 VeryCD 的主页为例,未压缩版本247K,压缩了以后45K,为原来的1/5。这就意味着抓取速度会快5倍。
然而python的urllib/urllib2默认都不支持压缩,要返回压缩格式,必须在request的header里面写明‘accept-encoding‘,然后读取response后更要检查header查看是否有‘content-encoding‘一项来判断是否需要解码,很繁琐琐碎。如何让urllib2自动支持gzip, defalte呢?
7. 更方便地多线程
总结一文的确提及了一个简单的多线程模板,但是那个东东真正应用到程序里面去只会让程序变得支离破碎,不堪入目。在怎么更方便地进行多线程方面我也动了一番脑筋。先想想怎么进行多线程调用最方便呢?
1、用twisted进行异步I/O抓取
事实上更高效的抓取并非一定要用多线程,也可以使用异步I/O法:直接用twisted的getPage方法,然后分别加上异步I/O结束时的callback和errback方法即可。
from twisted.web.client import getPage from twisted.internet import reactor links = [ ‘http://www.verycd.com/topics/%d/‘%i for i in range(5420,5430) ] def parse_page(data,url): print len(data),url def fetch_error(error,url): print error.getErrorMessage(),url # 批量抓取链接 for url in links: getPage(url,timeout=5) .addCallback(parse_page,url) \ #成功则调用parse_page方法 .addErrback(fetch_error,url) #失败则调用fetch_error方法 reactor.callLater(5, reactor.stop) #5秒钟后通知reactor结束程序
8. 一些琐碎的经验
opener.open和urllib2.urlopen一样,都会新建一个http请求。通常情况下这不是什么问题,因为线性环境下,一秒钟可能也就新生成一个请求;然而在多线程环境下,每秒钟可以是几十上百个请求,这么干只要几分钟,正常的有理智的服务器一定会封禁你的。
然而在正常的html请求时,保持同时和服务器几十个连接又是很正常的一件事,所以完全可以手动维护一个 HttpConnection 的池,然后每次抓取时从连接池里面选连接进行连接即可。
这里有一个取巧的方法,就是利用squid做代理服务器来进行抓取,则squid会自动为你维护连接池,还附带数据缓存功能,而且squid本来就是我每个服务器上面必装的东东,何必再自找麻烦写连接池呢
2、设定线程的栈大小
栈大小的设定将非常显著地影响python的内存占用,python多线程不设置这个值会导致程序占用大量内存,这对openvz的vps来说非常致命。stack_size必须大于32768,实际上应该总要32768*2以上
3、设置失败后自动重试
def get(self,req,retries=3): try: response = self.opener.open(req) data = response.read() except Exception , what: print what,req if retries>0: return self.get(req,retries-1) else: print ‘GET Failed‘,req return ‘‘ return data
4、设置超时
import socket socket.setdefaulttimeout(10) #设置10秒后连接超时
相同点
本质上都是通过 http/https 协议请求互联网数据
不同点
爬虫一般为自动化程序,无需用用户交互,而浏览器不是
运行场景不同;浏览器运行在客户端,而爬虫一般都跑在服务端
能力不同;浏览器包含渲染引擎、javascript 虚拟机,而爬虫一般都不具备这两者。
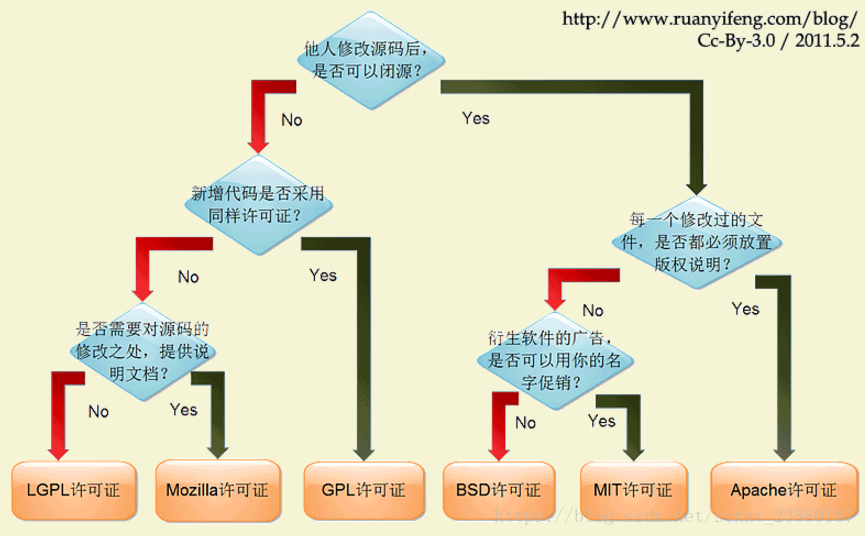
大概有上百种。很少有人搞得清楚它们的区别。即使在最流行的六种----GPL、BSD、MIT、Mozilla、Apache和LGPL
在Python中,一个.py文件就称之为一个模块
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。(包由很多模块组成,包就是命名空间)
每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码
其中 if __name__ ==‘__main__‘: 确保服务器只会在该脚本被 Python 解释器直接执行的时候才会运行,而不是作为模块导入的时候。
其中__name__属性的意思:
1、__name__是一个变量。前后加了双下划线是因为是因为这是系统定义的名字。普通变量不要使用此方式命名变量。
2、__name__就是标识模块的名字的一个系统变量。这里分两种情况:假如当前模块是主模块(也就是调用其他模块的模块),那么此模块名字就是__main__,通过if判断这样就可以执行“__mian__:”后面的主函数内容;假如此模块是被import的,则此模块名字为文件名字(不加后面的.py),通过if判断这样就会跳过“__mian__:”后面的内容。
通过上面方式,python就可以分清楚哪些是主函数,进入主函数执行;并且可以调用其他模块的各个函数等等。
神级总结:
one.py
two.py
所有规范就多写函数,变量别乱放。
转帖致敬:
https://blog.csdn.net/sinat_23880167/article/details/80508490
标签:setdaemon 总数 传输 odi pca parse top 环境 build
原文地址:https://www.cnblogs.com/baili-luoyun/p/10247319.html