标签:rip -name 命令行 机制 github 两种 disco 丢失 写日志
开发者在面对 kubernetes 分布式集群下的日志需求时,常常会感到头疼,既有容器自身特性的原因,也有现有日志采集工具的桎梏,主要包括:
本文档将介绍一种 Docker 日志收集工具 log-pilot,结合 Elasticsearch 和 kibana 等工具,形成一套适用于 kubernetes 环境下的一站式日志解决方案。
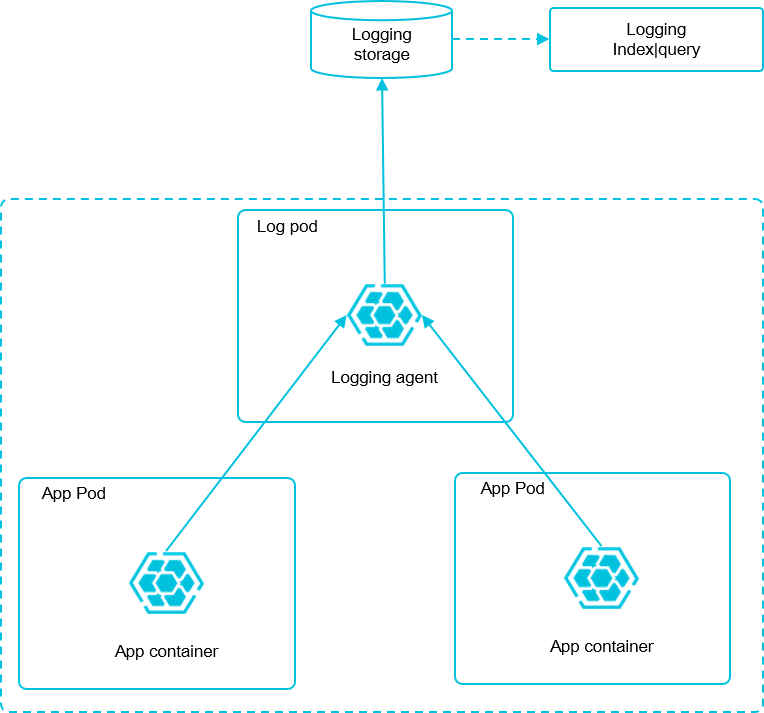
log-Pilot 是一个智能容器日志采集工具,它不仅能够高效便捷地将容器日志采集输出到多种存储日志后端,同时还能够动态地发现和采集容器内部的日志文件。
针对前面提出的日志采集难题,log-pilot 通过声明式配置实现强大的容器事件管理,可同时获取容器标准输出和内部文件日志,解决了动态伸缩问题,此外,log-pilot 具有自动发现机制,CheckPoint 及句柄保持的机制,自动日志数据打标,有效应对动态配置、日志重复和丢失以及日志源标记等问题。
目前 log-pilot 在 Github 完全开源,项目地址是 https://github.com/AliyunContainerService/log-pilot 。您可以深入了解更多实现原理。
Log-Pilot 支持容器事件管理,它能够动态地监听容器的事件变化,然后依据容器的标签来进行解析,生成日志采集配置文件,然后交由采集插件来进行日志采集。
在 kubernetes 下,Log-Pilot 可以依据环境变量 aliyun_logs_$name = $path 动态地生成日志采集配置文件,其中包含两个变量:
aliyun.logs.catalina=stdout 来采集 tomcat 标准输出日志。aliyun_logs_access=/usr/local/tomcat/logs/*.log来采集 tomcat 容器内部的日志。当然如果你不想使用 aliyun 这个关键字,Log-Pilot 也提供了环境变量 PILOT_LOG_PREFIX 可以指定自己的声明式日志配置前缀,比如 PILOT_LOG_PREFIX: "aliyun,custom"。此外,Log-Pilot 还支持多种日志解析格式,通过 aliyun_logs_$name_format=<format> 标签就可以告诉 Log-Pilot 在采集日志的时候,同时以什么样的格式来解析日志记录,支持的格式包括:none、json、csv、nginx、apache2 和 regxp。
Log-Pilot 同时支持自定义 tag,我们可以在环境变量里配置 aliyun_logs_$name_tags="K1=V1,K2=V2",那么在采集日志的时候也会将 K1=V1 和 K2=V2 采集到容器的日志输出中。自定义 tag 可帮助您给日志产生的环境打上 tag,方便进行日志统计、日志路由和日志过滤。
本文档采用 node 方式进行部署,通过在每台机器上部署一个 log-pilot 实例,收集机器上所有 Docker 应用日志。
您已经开通容器服务,并创建了一个 kubernetes 集群。本示例中,创建的 Kubernetes 集群位于华东 1 地域。
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/elasticsearch.yml$ kubectl get svc,StatefulSet -n=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/elasticsearch-api ClusterIP 172.21.5.134 <none> 9200/TCP 22h
svc/elasticsearch-discovery ClusterIP 172.21.13.91 <none> 9300/TCP 22h
...
NAME DESIRED CURRENT AGE
statefulsets/elasticsearch 3 3 22hkubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/log-pilot.ymlkubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/kibana.yml在 elasticsearch + log-pilot + Kibana 这套日志工具部署完毕后,现在开始部署一个日志测试应用 tomcat,来测试日志是否能正常采集、索引和显示。
编排模板如下。
apiVersion: v1
kind: Pod
metadata:
name: tomcat
namespace: default
labels:
name: tomcat
spec:
containers:
- image: tomcat
name: tomcat-test
volumeMounts:
- mountPath: /usr/local/tomcat/logs
name: accesslogs
env:
- name: aliyun_logs_catalina
value: "stdout" ##采集标准输出日志
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/catalina.*.log" ## 采集容器内日志文件
volumes:
- name: accesslogs
emptyDir: {}tomcat 镜像属于少数同时使用了 stdout 和文件日志的 Docker 镜像,适合本文档的演示。在上面的编排中,通过在 pod 中定义环境变量的方式,动态地生成日志采集配置文件,环境变量的具体说明如下:
aliyun_logs_catalina=stdout表示要收集容器的 stdout 日志。aliyun_logs_access=/usr/local/tomcat/logs/catalina.*.log 表示要收集容器内 /usr/local/tomcat/logs/ 目录下所有名字匹配 catalina.*.log 的文件日志。在本方案的 elasticsearch 场景下,环境变量中的 $name 表示 Index,本例中 $name即是 catalina 和 access 。
上面部署的 kibana 服务的类型采用 NodePort,默认情况下,不能从公网进行访问,因此本文档配置一个 ingress 实现公网访问 kibana,来测试日志数据是否正常索引和显示。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana-ingress
namespace: kube-system #要与 kibana 服务处于同一个 namespace
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: kibana #输入 kibana 服务的名称
servicePort: 80 #输入 kibana 服务暴露的端口$ kubectl get ingress -n=kube-system
NAME HOSTS ADDRESS PORTS AGE
shared-dns * 120.55.150.30 80 5m
您也可以执行以下命令,进入 elasticsearch 对应的 pod,在 index 下列出 elasticsearch 的所有索引。
$ kubectl get pods -n=kube-system #找到 elasticsearch 对应的 pod
...
$ kubectl exec -it elasticsearch-1 bash #进入 elasticsearch 的一个 pod
...
$ curl ‘localhost:9200/_cat/indices?v‘ ## 列出所有索引
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana x06jj19PS4Cim6Ajo51PWg 1 1 4 0 53.6kb 26.8kb
green open access-2018.03.19 txd3tG-NR6-guqmMEKKzEw 5 1 143 0 823.5kb 411.7kb
green open catalina-2018.03.19 ZgtWd16FQ7qqJNNWXxFPcQ 5 1 143 0 915.5kb 457.5kb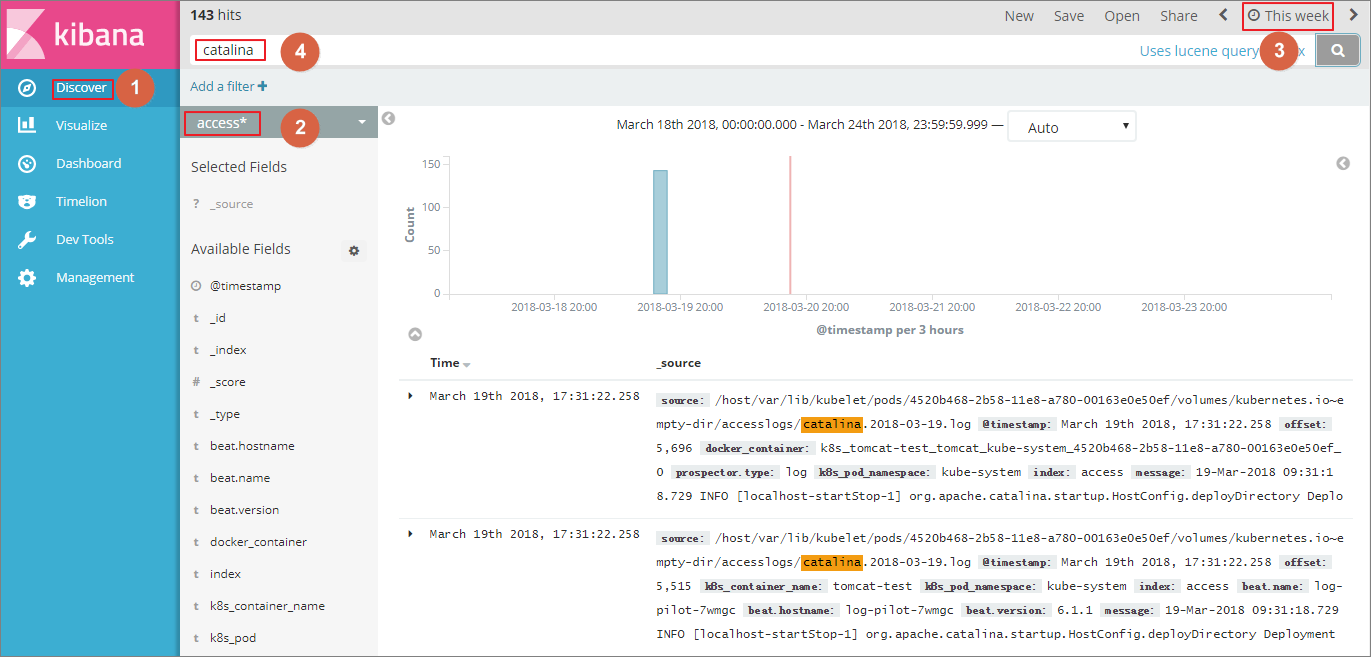
至此,在阿里云 Kubernetes 集群上,我们已经成功测试基于 log-pilot、elasticsearch 和 kibana 的日志解决方案,通过这个方案,我们能有效应对分布式 kubernetes 集群日志需求,可以帮助提升运维和运营效率,保障系统持续稳定运行。
利用 log-pilot + elasticsearch + kibana 搭建 kubernetes 日志解决方案
标签:rip -name 命令行 机制 github 两种 disco 丢失 写日志
原文地址:https://www.cnblogs.com/weifeng1463/p/10274021.html