标签:div 基本 一个 and tor 运算符 temp 生命周期 copy
C++STL中的vector模板类非常好用,有效解决了数组大小固定的问题。
而vector本身是封装好的,一般使用时只需要知道vector提供的接口即可,而它的内部是怎样实现的一直没有去了解。
看了邓公的数据结构,收获颇多。
1.秩:一个元素的秩就是它的前驱元的个数(它的前面的元素的个数),各元素的秩互异。
通过秩(记为r)可以唯一确定向量中的一个元素,这是向量独有的元素访问方式,称为循秩访问。
2.向量中的元素:向量中的元素不必为基本类型,也不必是可以比较大小的数值型。
可以是更具一般性的某一类的对象。(在C++中可以理解为,向量的元素可以是一个结构体或者类)
3.向量支持的ADT接口
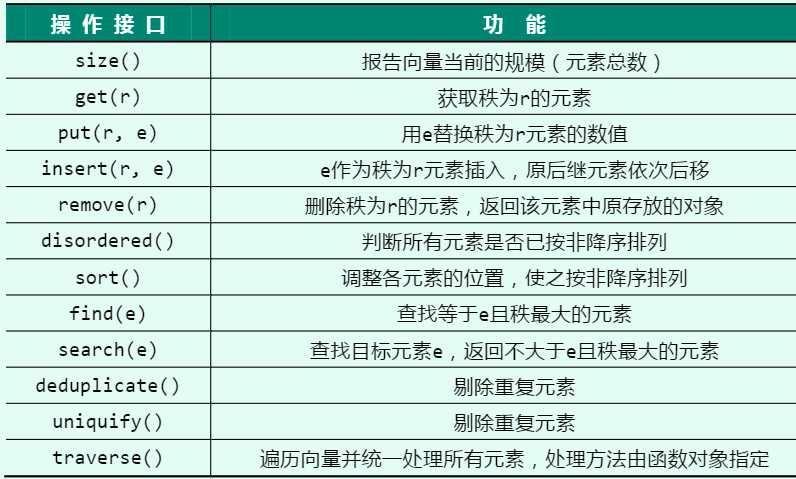
图片来源:《数据结构(C++语言版)第三版》 邓俊辉
了解过C++vector就知道,上面的大部分接口,C++提供的模板类都是支持的。
4.向量内部结构的本质
描述:向量结构在内部维护一个元素类型为T的私有数组,其容量由私有变量capacity指示,其有效元素数量(即当前向量的实际规模)由变量size指示。
//注意区别capacity和size,capacity可以理解为一个水桶的容量,而size相当于装在水桶中的水的体积,所以恒有size<=capacity
意思是,在向量这个结构内部,系统创建了一个数组,这个数组的元素不必是基本类型(C++template实现),描述其大小的数值储存在私有变量capacity中。
数组的大小是固定的,而一直以来vector都是作为变长数组来使用的,所以向量结构的核心在于,能对数组进行扩容。
扩容的方法很简单,在向向量中添加元素时,将当前的size+1,与capacity进行比较,如果size+1<=capacity,那么该元素成功添加到向量中(水桶不满),
如果size+1>capacity,也就是即将发生数组越界时(水桶满了),向量将new一个容量更大的数组,将原来数组中的元素复制到新的更大的数组中去,然后销毁原数组,释放空间。
通俗一点讲就是,小水桶装满了,就买一个更大的水桶,把小水桶中的水倒进去,然后把小水桶扔了防止占空间。
这就是向量实现数组扩容的基本思路,然而,怎样扩容,扩容多大合适,是有讲究的。
5.构造与析构
默认构造方法:向量被系统创建,然后借助构造函数初始化。默认构造方法为,根据创建者指定的容量向系统申请储存空间,创建数组_elem[]。若容量没有指定,则使用容量默认值DEFAULT_CAPACITY。_size初始化为0。
重载构造函数:

基于复制的构造方法:
1 //基于数组A的区间[lo,hi]构造 2 template <typename T> 3 void Vector<T>::copyFrom(T const*A, Rank lo, Rank hi) 4 { 5 //分配空间 6 _elem = new T[_capacity = 2 * (hi - lo)]; 7 _size = 0; 8 //逐一复制 9 while (lo < hi) 10 _elem[_size++] = A[lo++]; 11 }
析构方法:析构函数不能重载
1 ~Vector(){delete []_elem;}
忽略分配和回收空间的时间,构造与析构的时间复杂度均为O(1)
6.动态空间管理
装填因子:向量实际规模与其内部数组容量的比值(size/capacity),它是衡量空间利用率的指标
静态空间管理:比如数组,数组在其生命周期内大小固定,一方面,数组容量过小,很容易出现溢出,而另一方面,数组容量过大,导致空间利用率低
动态空间管理的目的就是,使得空间既能足够大以致不会溢出,也不会太大使得空间浪费,归纳起来就是,使得装填因子始终在(0,1)这个区间上
向量扩容:
1 template <typename T> void Vector<T>::expand() 2 { 3 //尚未满,不必扩容 4 if(_size<_capacity) 5 return; 6 //不得低于最小容量 7 if(_capacity<DEFAULT_CAPACITY) 8 _capacity=DEFAULT_CAPACITY; 9 T* oldElem=_elem; 10 //容量加倍 11 _elem=new T[_capacity<<1]; 12 //复制原向量内容 13 for(int i=0;i<_size;i++) 14 _elem[i]=oldElem[i]; 15 //释放原空间 16 delete [] oldElem; 17 }
这里选择容量加倍是很有讲究的,在这之前需要先了解分摊分析。
分摊分析:
对于一个操作的序列来讲,平摊分析得出的是在特定问题中这个序列下每个操作的平摊开销。一个操作序列中可能存在一、两个开销比较大的操作,在一般地分析下,如果割裂了各个操作的相关性或忽视问题的具体条件,那么操作序列的开销分析结果就可能会不够紧确,导致对于操作序列的性能做出不准确的判断。用平摊分析就可以得出更好的、更有实践指导意义的结果。因为这个操作序列中各个操作可能会是相互制约的,所以开销很大的那一两个操作,在操作序列总开销中的贡献也会被削弱和限制。所以最终会发现,对于序列来讲,每个操作平摊的开销是比较小的。
换句话说,对于一个操作序列来讲,平摊分析得出的是这个序列下每个操作的平摊开销。
每次扩容,系统都要将原向量中的元素进行复制,这需要花费额外的时间,那么,扩容一倍的策略时间复杂度即为O(2n)=O(n),这种策略的效率貌似很低,但O(n)仅仅是相对单次扩容而言。可以知道,经过一次扩容后,至少要再经过n次操作,才需要再一次扩容,而随着向量规模逐渐增大,n也越来越大,那么需要进行扩容操作的概率也就越来越小,平均而言,加倍扩容的成本并不很高。
缩容:一般情况下,下溢并不常见,需要用到缩容的场合很少,但不排除某些场合对空间利用率要求较高
1 template <typename T> void Vector<T>::shrink() 2 { 3 if(_capacity<DEFAULT_CAPACITY<<1) 4 return; 5 if(_size<<2>_capacity) //以25%为界 6 return; 7 T* oldElem=_elem; 8 //容量减半 9 _elem=new T[_capacity>>=1]; 10 //复制原向量内容 11 for(int i=0;i<_size;i++) 12 _elem[i]=oldElem[i]; 13 //释放原空间 14 delete [] oldElem; 15 }
这里选取25%为界,一旦空间利用率降至25%以下,将执行缩容操作。
实际应用中,为避免频繁缩容,可使用更低阀值,取0时即为禁止缩容。
7.引用元素
向量ADT为我们提供了get操作,实际应用中,可以像数组一样用下标运算符获取元素。
但向量中的元素并不一定是基本类型,这时需要对下标运算符“[]”进行重载。
1 template <typename T> T& Vector<T>::operaator[](Rank r) const 2 {return _elem[r];}
8.向量置乱算法
1 template <typename T> void permute(Vector<T>& V) 2 { 3 for(int i=V.size();i>0;i--) 4 swap(V[i-1],V[rand()%i]); 5 }
应用于软件测试,仿真模拟等方面,保证测试的覆盖面和仿真的真实性
封装置乱算法
1 template <typename T> void Vector<T>::unsort(Rank lo, Rank hi) 2 { 3 T* V = _elem + lo; 4 for (int i = V.size(); i > 0; i--) 5 swap(V[i - 1], V[rand() % i]); 6 }
这样封装以后,就可以对外提供一个置乱接口,可置乱任意区间[lo,hi]之间的元素
9.判等器和比较器
系统提供的比较符号包括“==”,“<=”,">="都是仅适用于数值类型的数据的,而向量的元素类型并不局限于基本类型,所以,要实现判等器和比较器,核心在于实现它们的通用性。
通常采用对比较操作进行封装形成比较器或在定义相应的数据类型时重载“==”,“>=”等运算符
10.查找
无序向量
有序向量
11.插入
12.删除
13.去重
无序向量
有序向量
14.遍历
15.排序
标签:div 基本 一个 and tor 运算符 temp 生命周期 copy
原文地址:https://www.cnblogs.com/CofJus/p/10306746.html