标签:搜索 字符串 缩小 建议 区间 要求 .com mic 使用
本文将介绍3区基数快速排序、后缀排序法。
在字符串算法—字符串排序(上篇)中,我们介绍了键索引计数法、LSD基数排序、MSD基数排序。
但LSD基数排序要求需排序字符串的长度一致;MSD基数排序虽然对字符串的长度没要求,但其递归循环里的每次循环都需要进行很多操作,且需要额外的空间。
本文将介绍一种更高效的字符串排序方法:结合MSD基数排序和3区快速排序。如果对这两种算法不熟悉的,建议先去了解一下。
从例子入手:与MSD基数排序一样,我们设定每个字符串的最后一位字符的下一个位置的空字符的键索为-1。a[]是拥有一堆字符串的字符串数组。
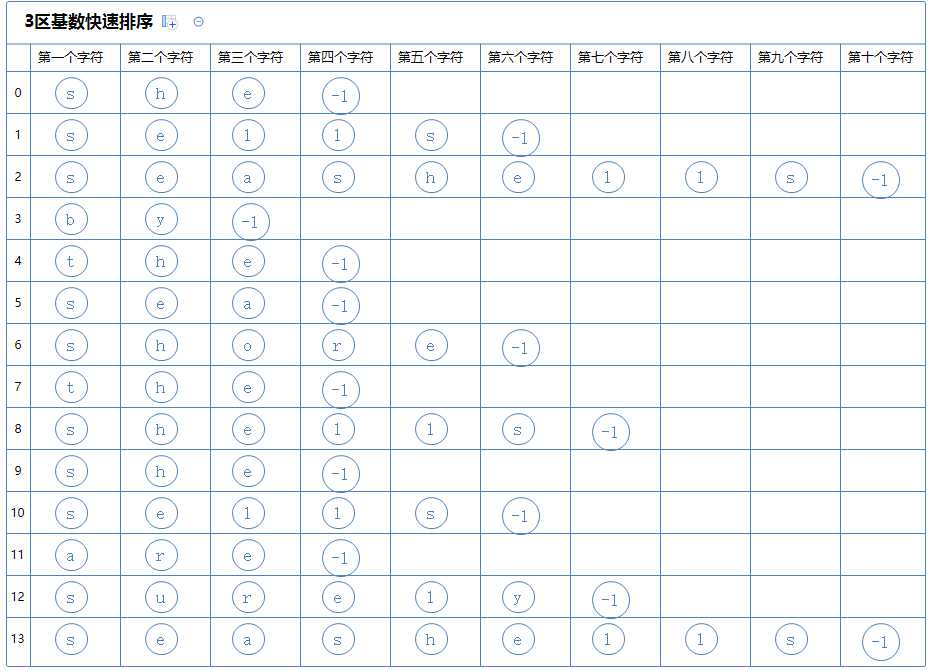
与MSD基数排序一样,每个字符配一个正数键索,用于比较字符间的大小。
首先,对a[0](she)的第一个字符(s)进行3区快速排序:
3区快速排序会把整个数组分为3个区:
第一个区里的所有字符串的第一个字符都比(she)的第一个字符(s)小,它含有a[0]、a[1];
第二个区里的所有字符串的第一个字符都与(she)的第一个字符(s)相同,它含有a[2]~a[11];
第三个区里的所有字符串的第一个字符都比(she)的第一个字符(s)大,它含有a[12]、a[13]。
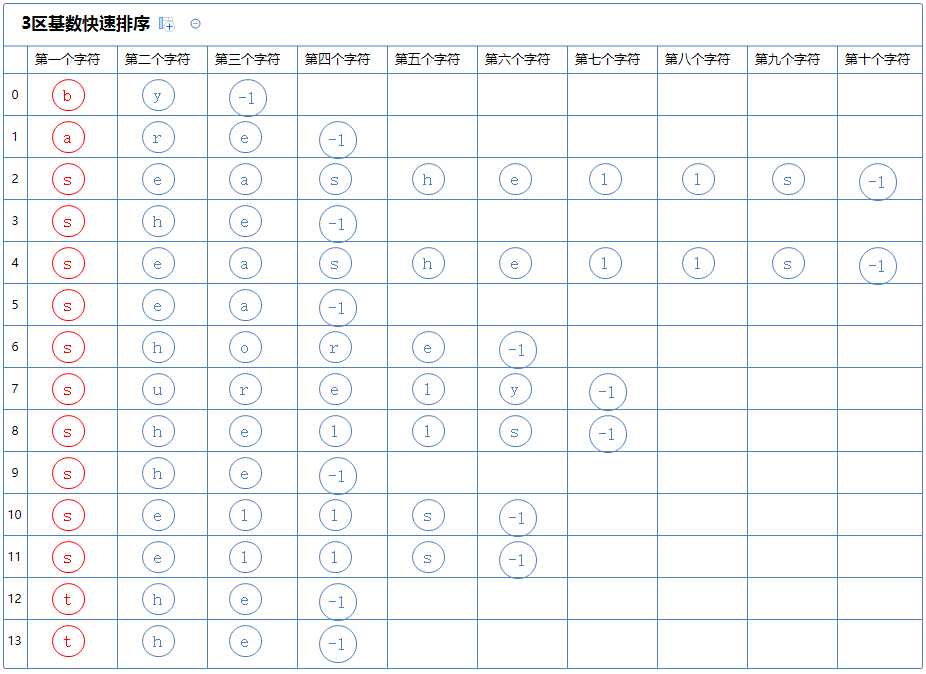
然后从上往下的,先看第一个区,此区含有多个字符串,对此区的第一个字符串(by)的第一个字符(b)进行3区快速排序:(为了方便观察,待排序的字符串用黑色表示)
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第一个字符都比(by)的第一个字符(b)小,它含有a[0];
第二个区里的所有字符串的第一个字符都与(by)的第一个字符(b)相同,它含有a[1];
第三个区里的所有字符串的第一个字符都比(by)的第一个字符(b)大,它没有元素;
然后从上往下的,先看第一个区,它只有一个字符串,此区排序完毕;
看第二个区,它只有一个字符串,此区排序完毕;
看第三个区,它没有字符串,此区排序完毕;
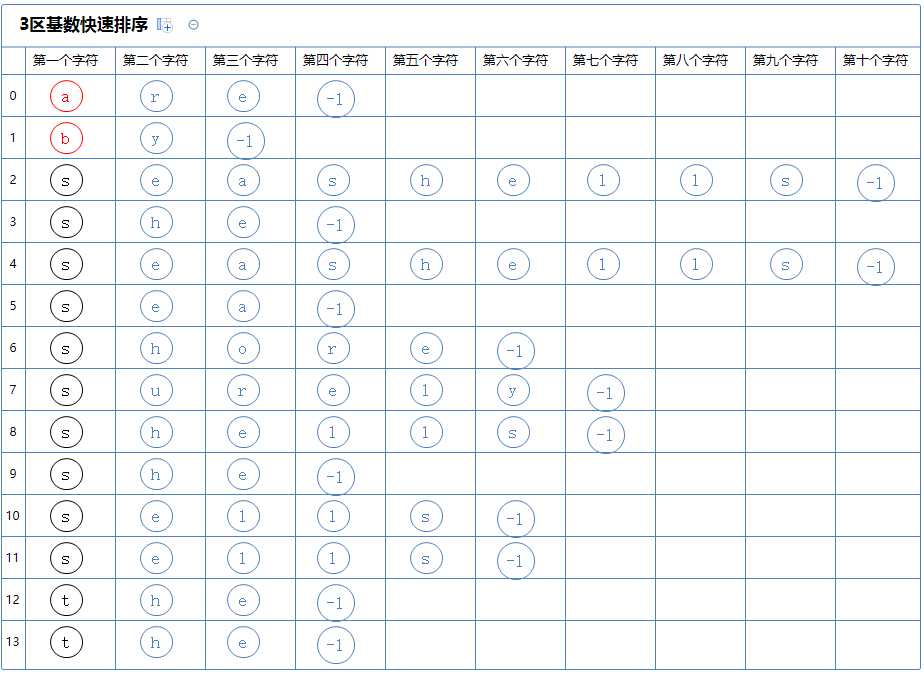
(为了方便观察,已排序完毕的字符串用绿色表示)
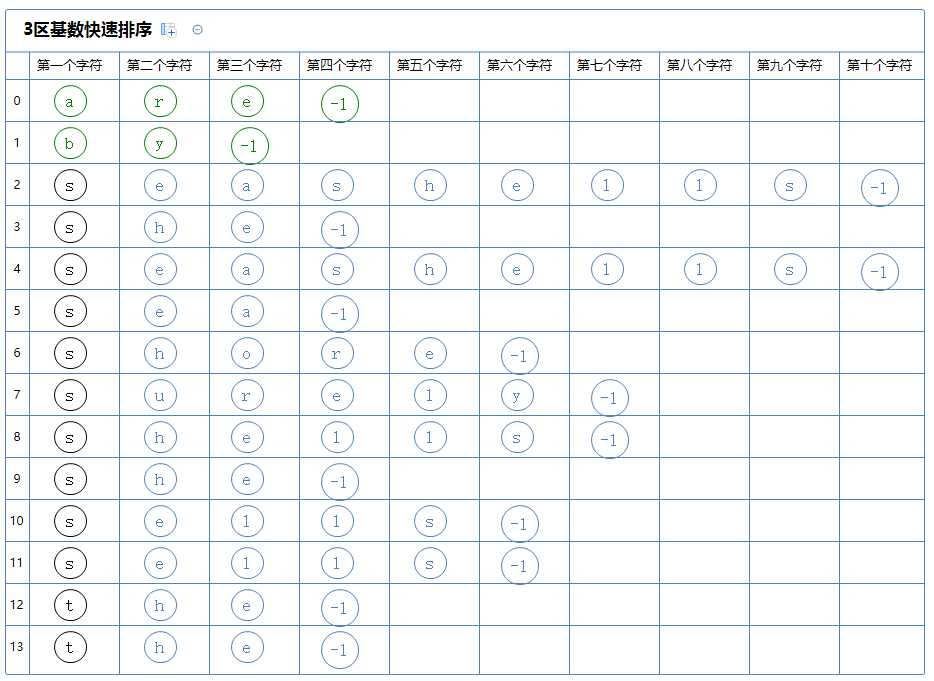
然后看下一个区,此区含有多个字符串,对此区的第一个字符串(seashells)的第二个字符(e)进行3区快速排序:
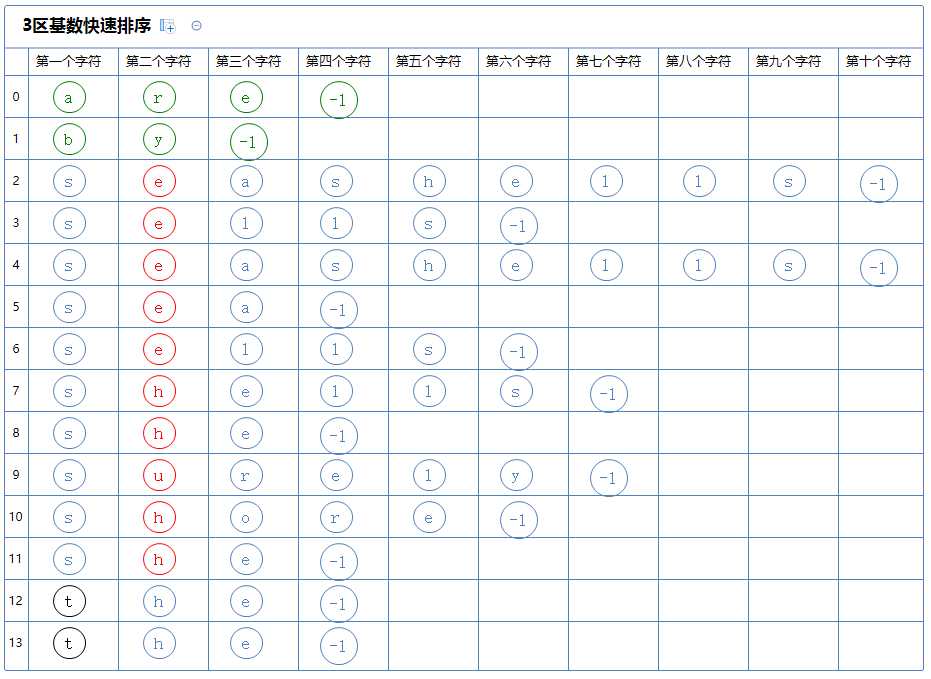
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第二个字符都比(seashells)的第二个字符(e)小,它没有元素;
第二个区里的所有字符串的第二个字符都与(seashells)的第二个字符(e)相同,它含有a[2]~a[6];
第三个区里的所有字符串的第二个字符都比(seashells)的第二个字符(e)大,它含有a[7]~a[11];
然后从上往下的,先看第一个区,它没有字符串,此区排序完毕;
看第二个区,它有多个字符串,对此区的第一个字符串(seashells)的第三个字符(a)进行3区快速排序:
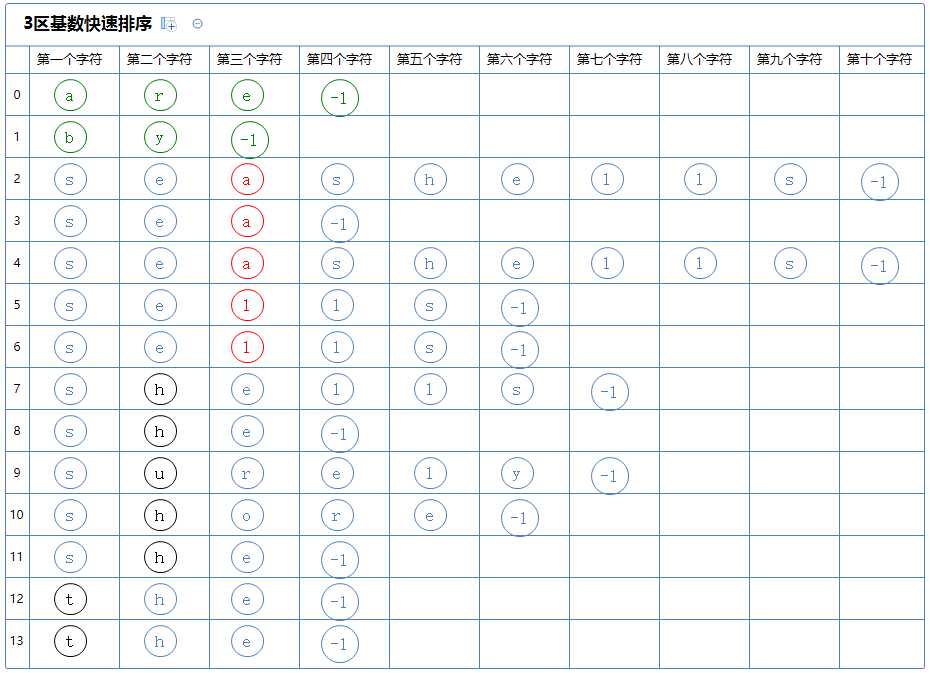
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第三个字符都比(seashells)的第三个字符(a)小,它没有元素;
第二个区里的所有字符串的第三个字符都与(seashells)的第三个字符(a)相同,它含有a[2]~a[4];
第三个区里的所有字符串的第三个字符都比(seashells)的第三个字符(a)大,它含有a[5]~a[6];
然后从上往下的,先看第一个区,它没有字符串,此区排序完毕;
看第二个区,它有多个字符串,对此区的第一个字符串(seashells)的第四个字符(s)进行3区快速排序:
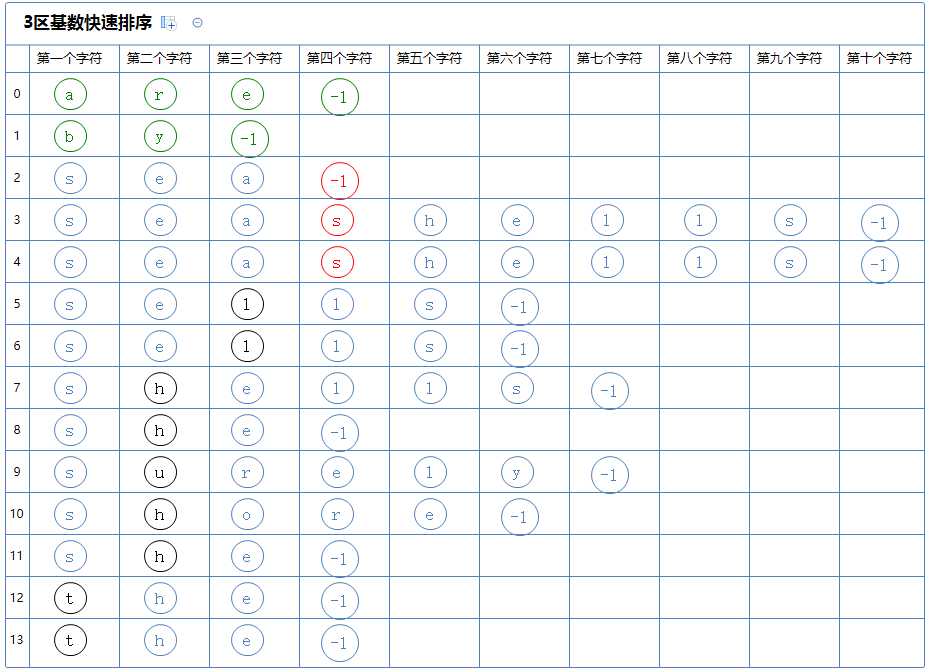
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第四个字符都比(seashells)的第四个字符(s)小,它含有a[2];
第二个区里的所有字符串的第四个字符都与(seashells)的第四个字符(s)相同,它含有a[3]~a[4];
第三个区里的所有字符串的第四个字符都比(seashells)的第四个字符(s)大,它没有元素;
然后从上往下的,先看第一个区,它只有一个字符串,此区排序完毕;
看第二个区,它有多个字符串,对此区的第一个字符串(seashells)的第五个字符(h)进行3区快速排序:
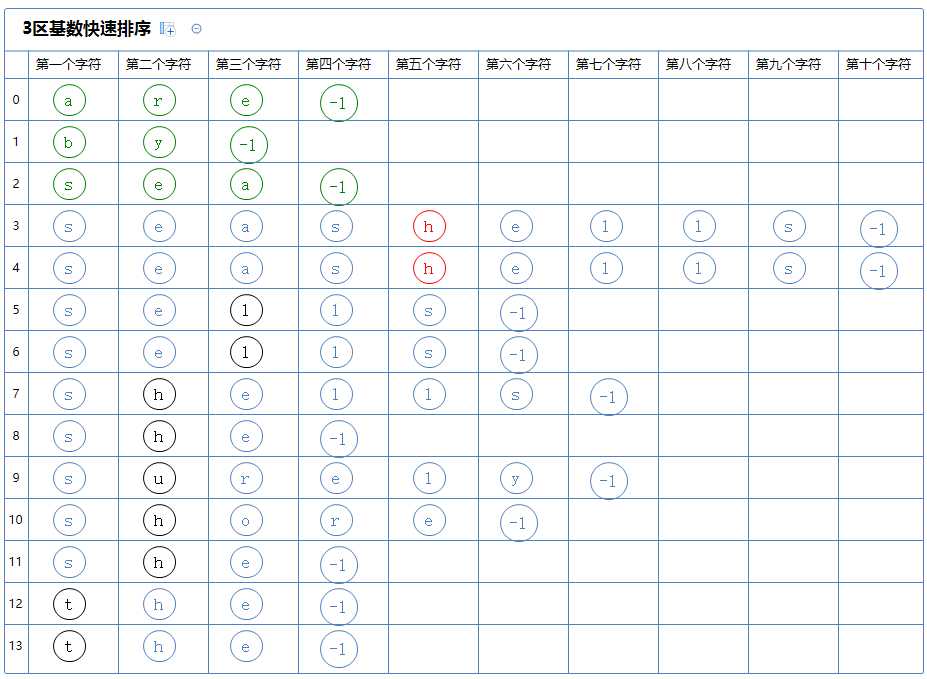
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第五个字符都比(seashells)的第五个字符(h)小,它没有元素;
第二个区里的所有字符串的第五个字符都与(seashells)的第五个字符(h)相同,它含有a[3]~a[4];
第三个区里的所有字符串的第五个字符都比(seashells)的第五个字符(h)大,它没有元素;
然后从上往下的,先看第一个区,它没有字符串,此区排序完毕;
看第二个区,它有多个字符串,对此区的第一个字符串(seashells)的第六、七、八、九、十个字符(h)进行3区快速排序:(由于这两个字符串是一样的,排序结果不变,这里省略中间过程,直接到第十个字符的排序)
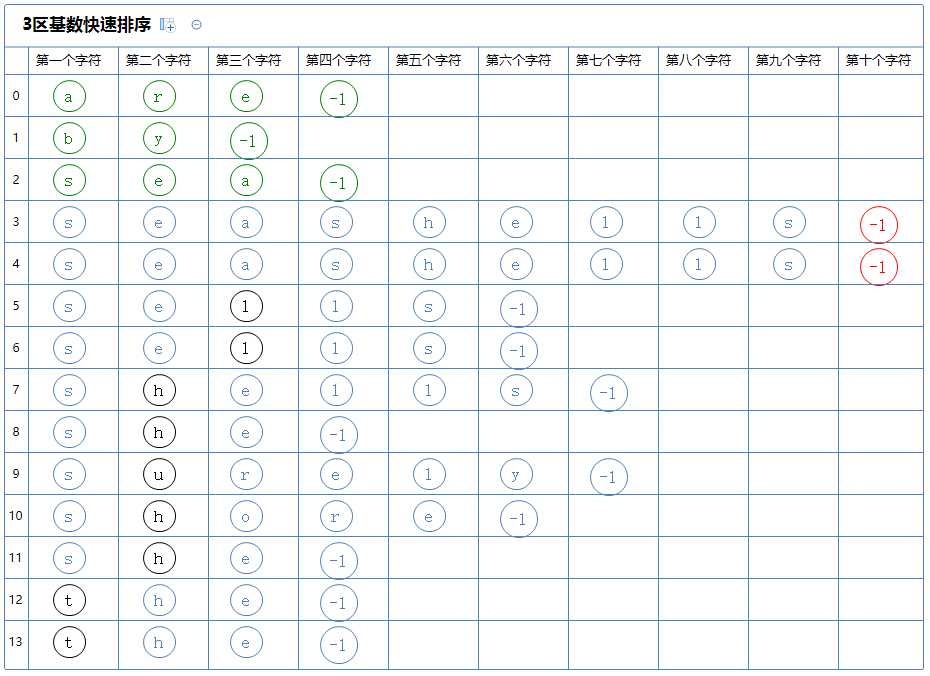
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第五个字符都比(seashells)的第五个字符(h)小,它没有元素;
第二个区里的所有字符串的第五个字符都与(seashells)的第五个字符(h)相同,它含有a[3]~a[4];
第三个区里的所有字符串的第五个字符都比(seashells)的第五个字符(h)大,它没有元素;
然后从上往下的,先看第一个区,它没有字符串,此区排序完毕;
看第二个区,它有多个字符串,但此区的第一个字符串(seashells)没有第十一个字符,故此区排序结束;
看第三个区,它没有字符串,此区排序完毕;
看下一个区,它有多个字符串,对此区的第一个字符串(sells)的第四个字符(l)进行3区快速排序:
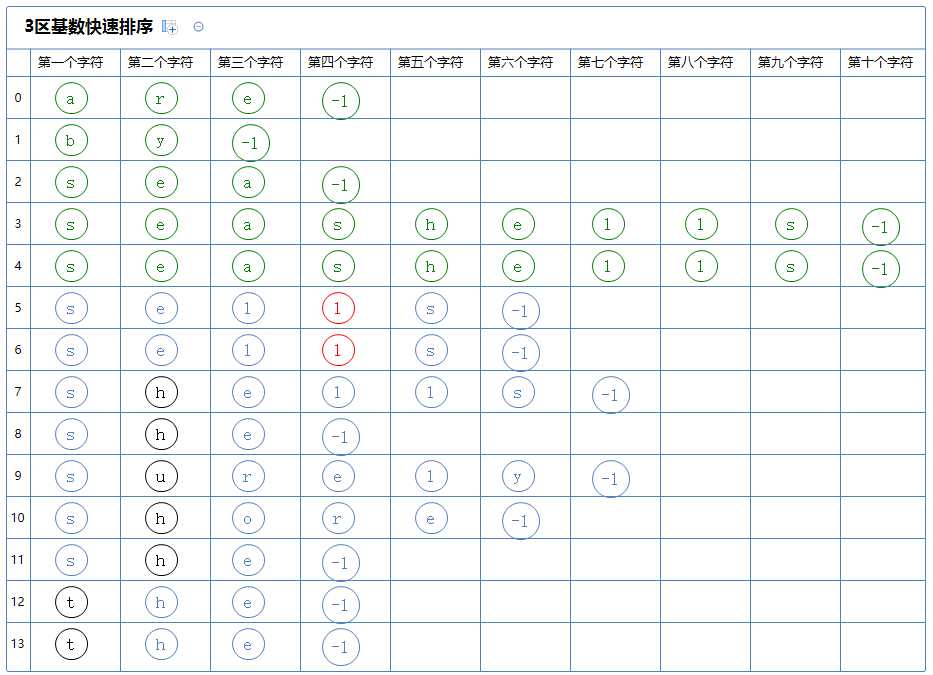
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第四个字符都比(sells)的第四个字符(l)小,它没有元素;
第二个区里的所有字符串的第四个字符都与(sells)的第四个字符(hl)相同,它含有a[5]~a[6];
第三个区里的所有字符串的第四个字符都比(sells)的第四个字符(l)大,它没有元素;
然后从上往下的,先看第一个区,它没有字符串,此区排序完毕;
看第二个区,它有多个字符串,对此区的第一个字符串(sells)的第五、六个字符(h)进行3区快速排序:(由于这两个字符串是一样的,排序结果不变,这里省略中间过程,直接到第六个字符的排序)
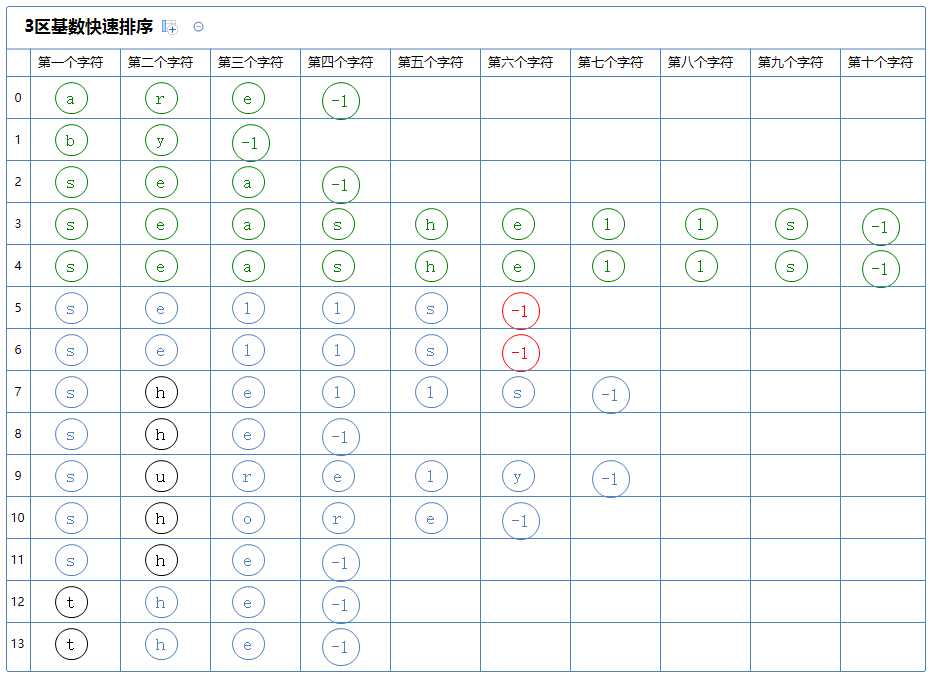
3区快速排序会把整个区分为3个区:
第一个区里的所有字符串的第六个字符都比(sells)的第六个字符小,它没有元素;
第二个区里的所有字符串的第六个字符都与(sells)的第六个字符相同,它含有a[5]~a[6];
第三个区里的所有字符串的第六个字符都比(sells)的第六个字符大,它没有元素;
然后从上往下的,先看第一个区,它没有字符串,此区排序完毕;
看第二个区,它有多个字符串,但此区的第一个字符串(sells)没有第七个字符,故此区排序结束;
看第三个区,它没有字符串,此区排序完毕;
看下一个区,它有多个字符串,对此区的第一个字符串(shells)的第三个字符(e)进行3区快速排序:
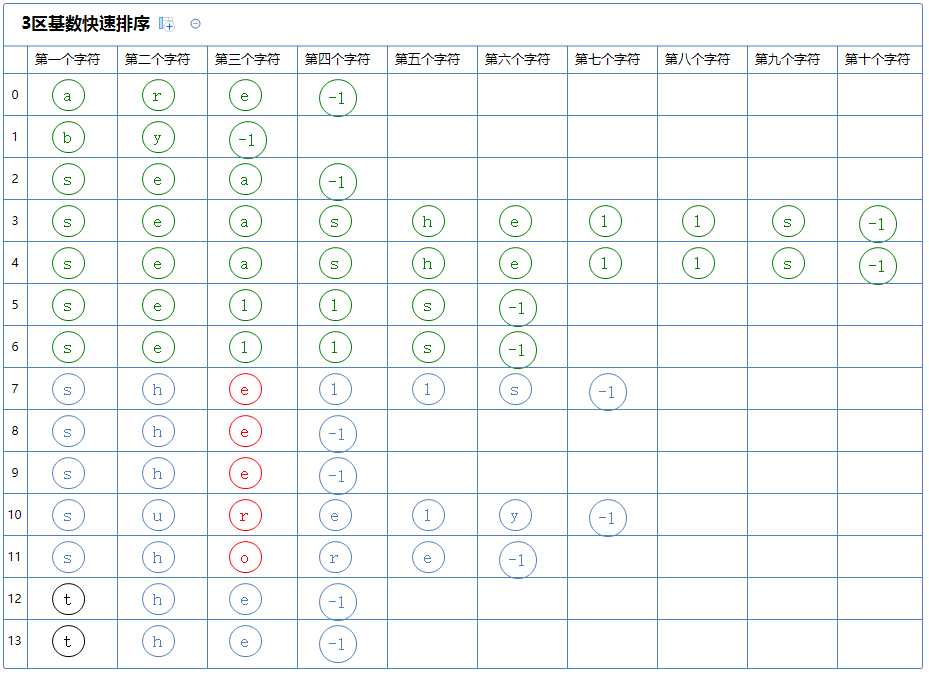
如此类推,直到所有区排序完毕。
总结一下:
1. 对第一个字符串的第一个字符通过3区快速排序把这堆字符串排一次序,根据排序结果进行分区;
2. 从上往下处理各个分区:如果分区只有一个字符串,则此区处理完毕;如果有多个字符串,则对此区的第一个字符串的第d个字符进行排序、分区、处理分区。(d值随着排序进行而改变)
3. 所有分区处理完后,排序完毕,算法结束。
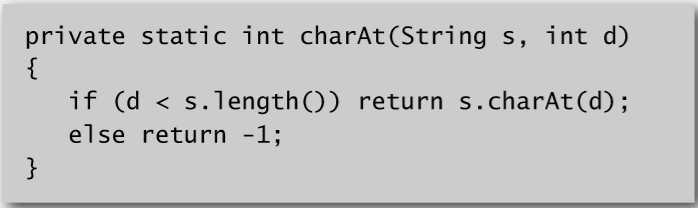
代码实现:

注释:
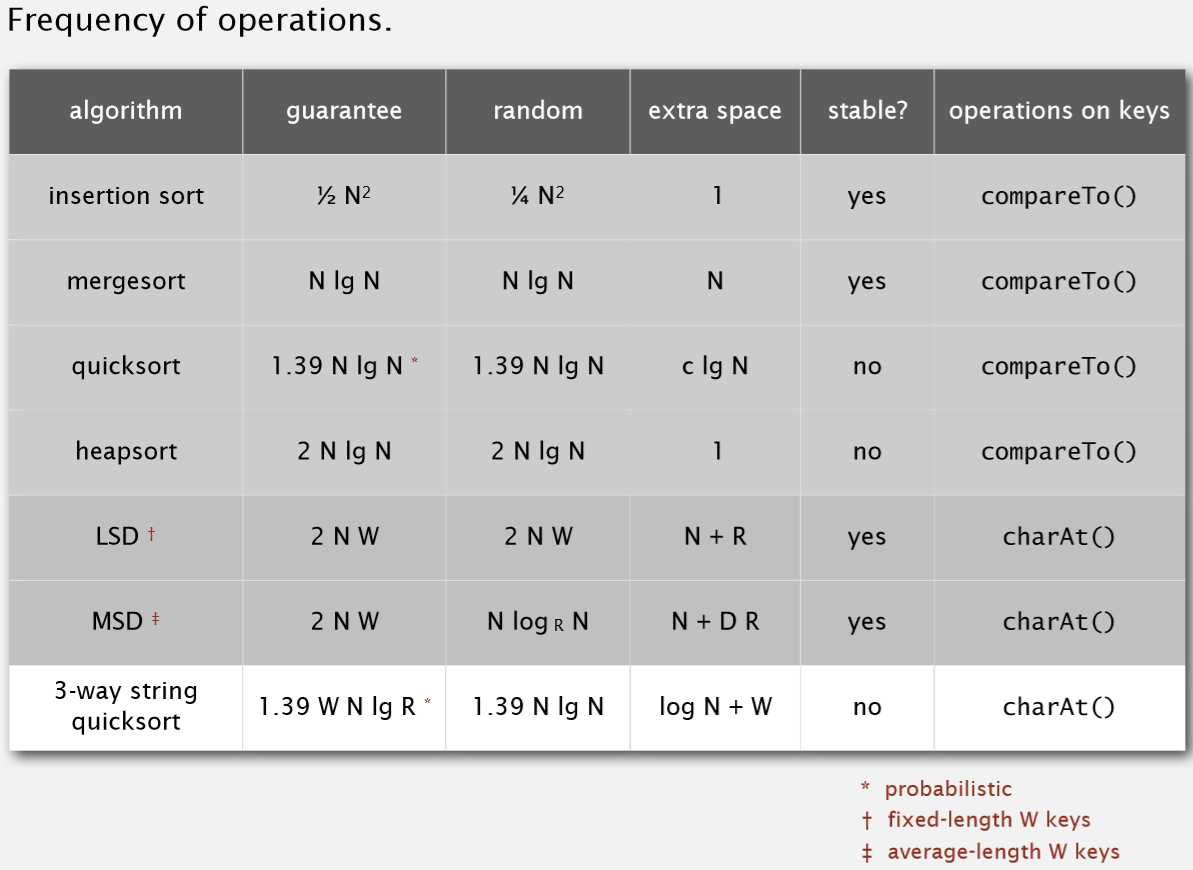
N为要排序的元素个数。
LSD的W: 由于LSD只针对于要排序的那堆字符串长度相同,故W为字符串的长度。
MSD的W: 要排序的那堆字符串的长度平均值。
guarantee: 算法保证能在多少次操作后完成。
random: 如果要排序的数组里的元素顺序是随机的,则算法可以在多少次操作后完成。
extra space: 算法需要的额外空间。
3区基数快速排序不需要构建额外数组,相比于MSD,它对内存是比较友好的,但它是不稳定(unstable)的。
当我们面对着搜索关键词、寻找文章中最长的重复词等需求时,可以用后缀排序法来高效解决。
从例子入手:假设我们有一段语句如下

我们把这段语句看成是一个字符数组S[],则S[0]=i; S[1]=t;S[2]=w;......
然后把这段语句变成一个字符串数组A[]:

A[0]由S[0]~S[14]组成;A[1]由S[1]~S[14]组成;A[2]由S[2]~S[14]组成;......;A[14]由S[14]组成;
然后用MSD基数排序或者3区基数快速排序对这个字符串数组排序:

排完序后,后缀排序法就结束了。
现在我们根据不同的需求,进行不同的操作:
一. 需求:寻找关键词
假设我们现在要从上面那段语句中寻找“itwas”这个词,我们将使用二分法检索(binary search)。
首先简单回顾一下二分法检索:
将给定值key与数组中间位置上元素的关键码(key)比较,如果相等,则检索成功;
否则,若key小,则在数组前半部分中继续进行二分法检索;若key大,则在数组后半部分中继续进行二分法检索。
这样,经过一次比较就缩小一半的检索区间,如此进行下去,直到检索成功或检索失败。
然后回到我们现在的需求。
itwas这个词的第一个字符为i,然后在字符串数组A[]中所有字符串的第一个字符里进行二分法检索。
检索结果:A[0],A[9]符合。
然后itwas这个词的第二个字符为t,在A[0],A[9]的第二个字符中进行二分法检索,仍然符合。
然后检索itwas的第三、四、五个字符,如果全部符合,则A[0],A[9]就是我们要找的关键词。A[0],A[9]就是原语句的第0、9个字符。
需求完成。
二. 需求:寻找文章中最长的重复词
其实当我们后缀排序完后,重复词已经紧挨在一起了,找出来也很简单:
A[0]与A[1]对比,找到重复词为"as",长度为2,as暂时为最长的重复词;
A[1]与A[2]对比,没有重复词;
A[2]与A[3]对比,没有重复词;
A[3]与A[4]对比,没有重复词;
A[4]与A[5]对比,找到重复词为"itwas",长度为5,5>2,更新itwas为最长的重复词;
A[5]与A[6]对比,没有重复词;
如此类推。。。
A[13]与A[14]对比,找到重复词为"wa",长度为2,2<5, 不更新最长的重复词;
A[14]为最后一个元素,对比完毕,此语句最长重复词为"itwas"。
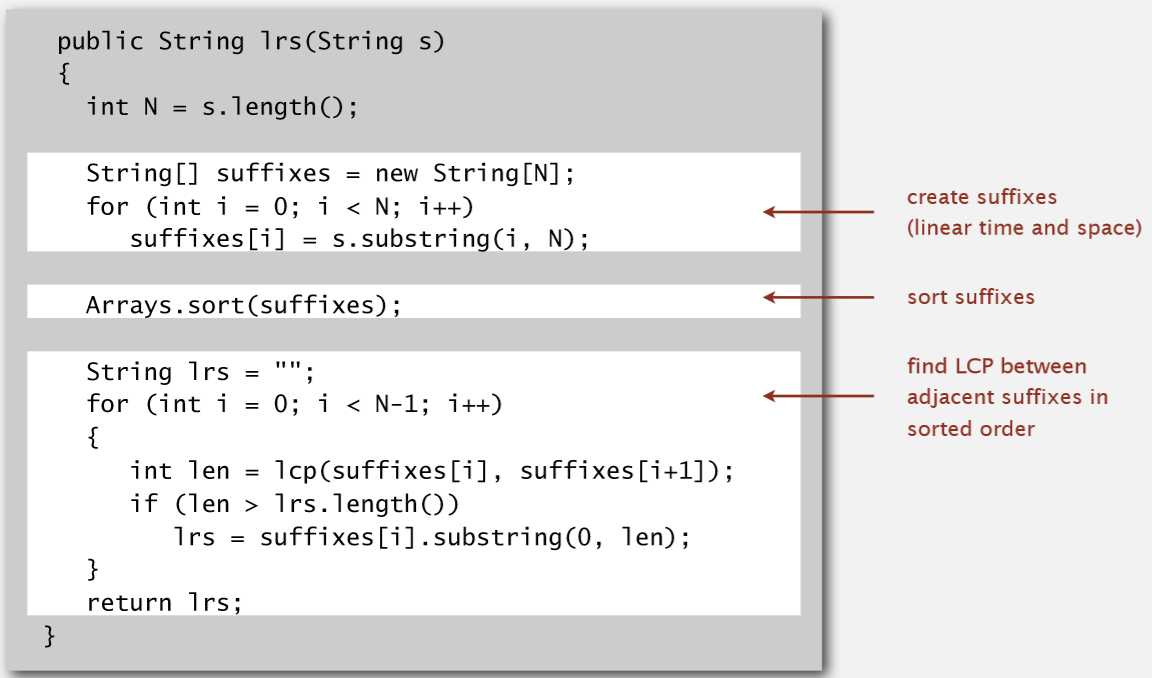
对比方法也不难实现:把两个词相同位置的字符进行逐一对比,一旦出现不相同,则结束对比,返回相同的字符,形成重复词。
实现代码:
标签:搜索 字符串 缩小 建议 区间 要求 .com mic 使用
原文地址:https://www.cnblogs.com/mcomco/p/10366184.html