标签:rom ber 应该 传递 patch 相关 返回 ast 共享数据
(1)原始方法
(2)接口式编程
(1)xml 中引入 dtd 约束
(2)properties标签:url引入网络或者磁盘的资源;resource引入 classpath 下的资源;
(3)settings标签:设置一些mybatis运行时的重要参数
(4)typeAliases标签:就是给 java 类起别名用的
(5)typeHandlers标签:
(6)plugins标签:作用就是拦截四大对象,改变他们的默认行为
(7)environments标签:
(8)databaseIdProvider标签:
(9)mappers标签:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <properties resource="conf/dbconfig.properties"></properties> <!-- <settings> <setting name="" value="" /> </settings> <typeAliases> 单独起别名 <typeAlias type="" alias="" /> 批量起别名 <package name="" /> </typeAliases> <typeHandlers> <typeHandler handler="" /> </typeHandlers> <plugins> <plugin interceptor=""></plugin> </plugins> --> <environments default="development"> <!-- <environment id="test"> <transactionManager type=""></transactionManager> <dataSource type=""></dataSource> </environment> --> <environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}" /> <property name="url" value="${jdbc.url}" /> <property name="username" value="${jdbc.username}" /> <property name="password" value="${jdbc.password}" /> </dataSource> </environment> </environments> <databaseIdProvider type="DB_VENDOR"> <property name="Oracle" value="oracle" /> <property name="MySQL" value="mysql" /> </databaseIdProvider> <mappers> <mapper resource="conf/TuserMapper.xml" /> </mappers> </configuration>
(1)增删改测试
(2)数据插入获得自增主键
(1)单个参数
(2)多个参数
(3)参数处理源码分析
(4)关于 #{} 和 ${}两种取值的方法:
(1)resultType
(2)resultMap(关联查询 | 分步查询 | 延迟加载 | 集合属性封装)
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.wc.mapper.TuserMapper"> <!-- <resultMap type="tuser" id="map1"> <id property="uid" column="tid"/> <result property="uname" column="uname"/> <result property="age" column="age"/> 关联查询 <association property="dept" javaType="department"> <id property="did" column="did"/> <result property="dname" column="dname"/> </association> </resultMap> --> <resultMap type="tuser" id="map2"> <id property="uid" column="tid"/> <result property="uname" column="uname"/> <result property="age" column="age"/> <result property="did" column="did"/> <!-- select step by step --> <association property="dept" select="com.wc.mapper.DepartmentMapper.getDeptById" column="did"> <id property="did" column="did"/> <result property="dname" column="dname"/> </association> </resultMap> <select id="getById" resultMap="map2"> select * from tuser where tid = #{id} </select> </mapper>
(1)OGNL(对象图导航语言)
(2)if 判断
(1)语法:choose----when----when----otherwise-----choose
(2)理解:类似于 java 中带break 的 switch语句,只匹配一个条件;
(1)遍历集合拼接 where 条件(如:in 集合)
(2)实现数据的批量插入
(1)内置参数:
(2)bind 标签:作用就是将传入的参数赋值给一个变量方便以后的调用,连个属性name 和 value;
(3)sql 片段:
(1)作用:就是提升查询的效率;
(2)分类:
(1)一级缓存失效的四种情况
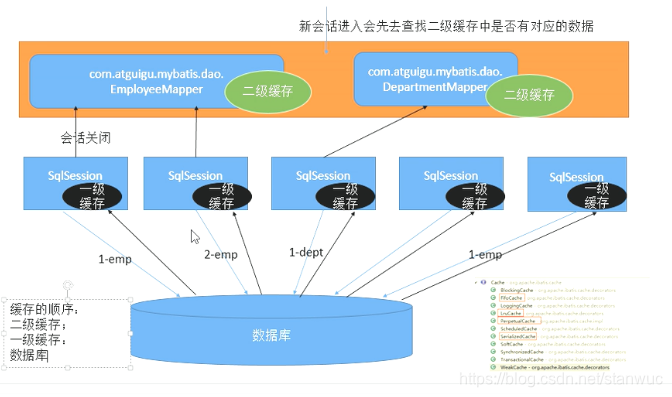
(1)作用:可以实现不同的 session 之间的数据共享,一个 namespace(一个接口)对应一个map(二级缓存);
(2)原理:
(3)使用:总开关(主配文件里的 setting)和分开关(sql映射文件里用 cache标签来开启)都要打开;
(1)缓存相关设置
(2)原理图示
![]() ?
?
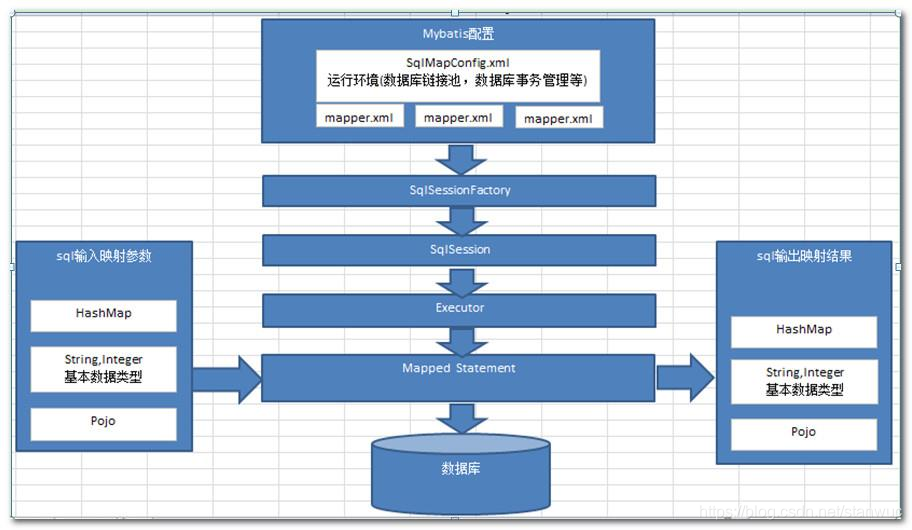
(1)步骤:
(1)核心包:spring包、springmvc包、mybatis包、spring-mybatis整合包
(2)其他包:日志包、连接池包
(1)主要就是配全局 settings 等;
(1)controller 扫描;
(2)视图解析器;
(3)注解驱动;
(4)默认servlet 处理;
(1)包扫描;
(2)数据源的配置;
(3)事务管理(基于注解的事务);
(4)sqlSessionFactory配置;
(5)配置可以批量执行的 sqlSession;
(6)配置Mapper 接口的扫描(不可少);
(1)全局参数配置 spring配置文件的路径;
(2)配置spring 监听;
(3)配置 springmvc 的DispatcherServlet;
(4)spring框架会自动加载 web-inf 下的配置文件,classpath 路径下的配置文件需要配置路径;
(5)所有配置文件的示例;
(1)导包
(2)配置文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd"> <generatorConfiguration> <!-- targetRuntime="MyBatis3Simple":生成简单版的CRUD MyBatis3:豪华版 --> <context id="DB2Tables" targetRuntime="MyBatis3"> <!-- jdbcConnection:指定如何连接到目标数据库 --> <jdbcConnection driverClass="com.mysql.jdbc.Driver" connectionURL="jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true" userId="root" password="123456"> </jdbcConnection> <!-- --> <javaTypeResolver > <property name="forceBigDecimals" value="false" /> </javaTypeResolver> <!-- javaModelGenerator:指定javaBean的生成策略 targetPackage="test.model":目标包名 targetProject="\MBGTestProject\src":目标工程 --> <javaModelGenerator targetPackage="com.atguigu.mybatis.bean" targetProject=".\src"> <property name="enableSubPackages" value="true" /> <property name="trimStrings" value="true" /> </javaModelGenerator> <!-- sqlMapGenerator:sql映射生成策略: --> <sqlMapGenerator targetPackage="com.atguigu.mybatis.dao" targetProject=".\conf"> <property name="enableSubPackages" value="true" /> </sqlMapGenerator> <!-- javaClientGenerator:指定mapper接口所在的位置 --> <javaClientGenerator type="XMLMAPPER" targetPackage="com.atguigu.mybatis.dao" targetProject=".\src"> <property name="enableSubPackages" value="true" /> </javaClientGenerator> <!-- 指定要逆向分析哪些表:根据表要创建javaBean --> <table tableName="tbl_dept" domainObjectName="Department"></table> <table tableName="tbl_employee" domainObjectName="Employee"></table> </context> </generatorConfiguration>
(3)运行生成器 java 代码
public void testMbg() throws Exception { List<String> warnings = new ArrayList<String>(); boolean overwrite = true; File configFile = new File("mbg.xml"); ConfigurationParser cp = new ConfigurationParser(warnings); Configuration config = cp.parseConfiguration(configFile); DefaultShellCallback callback = new DefaultShellCallback(overwrite); MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config, callback, warnings); myBatisGenerator.generate(null); }
EmployeeExample example = new EmployeeExample(); Criteria criteria = example.createCriteria(); criteria.andLastNameLike("%e%"); criteria.andGenderEqualTo("1"); Criteria criteria2 = example.createCriteria(); criteria2.andEmailLike("%e%"); example.or(criteria2);
![]() ?
?

![]() ?
?
注意:在四大对象的创建过程中都会有插件的介入;
(1)原理
(2)简单实现--单个插件
(3)多个插件:拦截同一个对象同一个方法
(4)开发示例:

![]() ?
?
(5)PageHelper 插件
(1)批量执行sql语句
(2)mybatis 调用存储过程
(3)自定义类型处理器处理枚举类型
标签:rom ber 应该 传递 patch 相关 返回 ast 共享数据
原文地址:https://www.cnblogs.com/stanwuc/p/10523932.html