标签:request import width list forum html 一个 python库 http
爬取目标: 收集网站帖子里发帖人用户名,发帖人ID;帖子的ID,发帖内容;网站title
提前需要准备的python库
pip3 install requests //用于获得网站的源码
pip3 install bs4 //解析遍历网站标签
pip3 install urllib //解析网站的url
首先导入包
import requests
from bs4 import BeautifulSoup
from urllib.parse import parse_qs,urlparse
import json //导出文件的时候用json输出
第一部: 获取网站的源码
def get_Web_content(url):
response = requests.get(url)
if response.status_code == 200:
if ‘抱歉,指定的主题不存在或已被删除或正在被审核‘ in response.text:
return False
else:
return response.text
else:
return False
第二部: 获取网站的源码并且解析
def get_Web_Info(Content):
soup = BeautifulSoup(Content,"html.parser") //转化为BS对象
title = soup.title.string
url = soup.link[‘href‘]
parsed_url = urlparse(url) //parsed_url讲URL解析,最后返回字典对象(协议、位置、路径、参数、查询、片段).返回的查询query之后会用到
posted_url = parse_qs(parsed_url.query) //parse_qs解析 parse_qs函数范围的对象中的query查询
tid = posted_url[‘tid‘][0] //posted_url(字典类型) //将字典第一个元素取出
userlist = get_post_userlist(soup) // 调用get_post_userlist方法 - 获取发帖用户信息
contentlist = get_contentlist(soup) // 调用get_conentlist方法,获得内容的信息
for i in range(len(contentlist)):
contentlist[i][‘user_list‘] = userlist[i] // 将userlist中的信息 添加进contentlist中
post_content_info = {
‘title‘:title,
‘url‘:url,
‘tid‘:tid,
‘author‘:userlist[0],
‘content‘:contentlist[0][‘content‘],
‘comment‘:contentlist[1:]
}
return post_content_info
def get_post_userlist(post_soup_object):
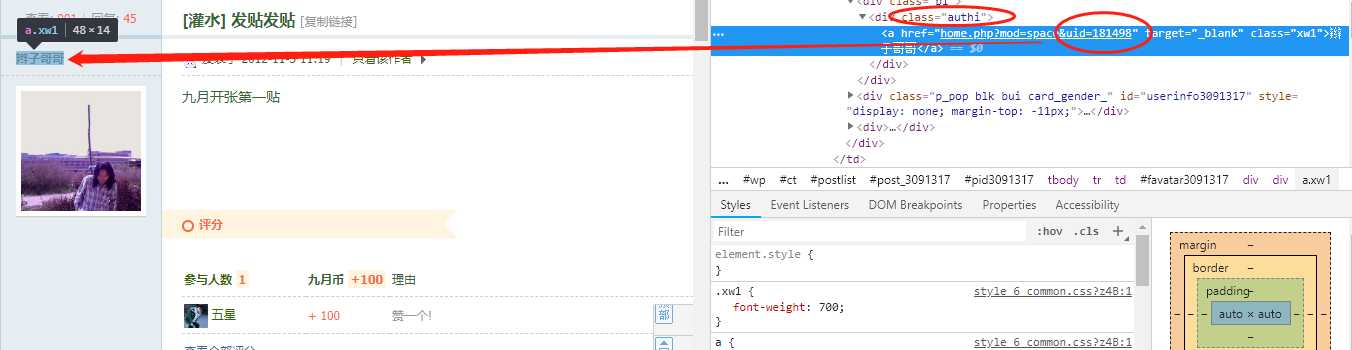
user_info_doms = post_soup_object.select(".authi")
# 选择器,可以获得多条也可以获得单条数据
user_list = []
# 定义一个用户空列表
for i in range(len(user_info_doms)):
if i%2 == 0: // 第二条数据无用
user_name = user_info_doms[i].a.string //选择将a标签里的字段取出
# 将下角标为i的数据转换成string类型
uid = parse_qs(user_info_doms[i].a[‘href‘])[‘uid‘][0] //获取链接中的uid
user_list.append({"user_name":user_name,"uid":uid})
# 向列表中添加元素
return user_list //返回一个列表
# 返回发帖者的数组
def get_contentlist(Soup):
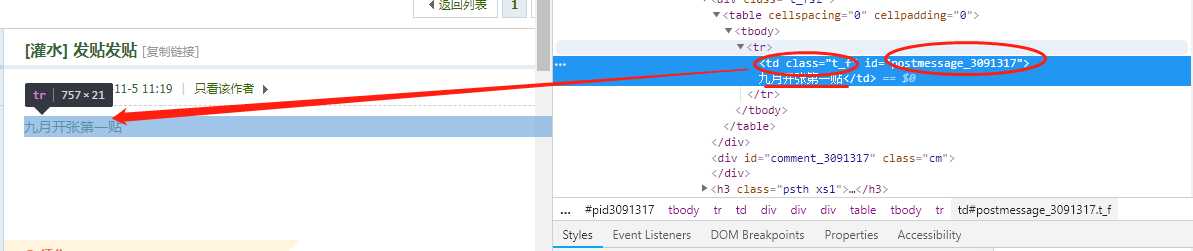
object = Soup.select(‘.t_f‘)
content_list = []
for i in range(len(object)):
content = object[i].string
postmessage = object[i][‘id‘]
tid = postmessage.split("_")[1] //split 以‘_‘分割 取之后的第一个元素
content_list.append({"tid":tid,"content":content})
return content_list
//将爬取的数据写入txt文件
def writeTofile(content):
with open("test4.text",‘a‘,encoding=‘utf-8‘) as f:
f.write(content[‘url‘]+‘\t‘) ‘\t 后面追加一个tab空格‘
f.write(content[‘tid‘]+‘\t‘)
f.write(content[‘author‘][‘user_name‘]+‘\t‘)
f.write(content[‘author‘][‘uid‘]+‘\t‘)
f.write(json.dumps(content[‘comment‘],ensure_ascii=False)+‘\t‘)
f.write(‘{0:<30}‘.format(content[‘title‘]).split("-")[0] +‘\t‘)
f.write(‘\n‘)
f.close()
url = ‘http://www.9yfeng.com/forum.php?mod=viewthread&tid=‘
for i in range(1,1000):
content = get_Web_content(url+str(i))
if(content!=False):
web_info = get_Web_Info(content)
writeTofile(web_info)
标签:request import width list forum html 一个 python库 http
原文地址:https://www.cnblogs.com/kevin162726/p/10714382.html