标签:try arm 实现 pvs sch 节点 周期性 图片 swa
写在前面的话
docker 先告一段落骂我们现在进入 Kubernets(K8S) 的学习阶段,在学习过程中,可以结合之前学习的 docker swarm,比对着来理解。
啥是 K8S
先来看一下两个 logo:

之前说过,docker 是 “码头工人”,而 K8S 则是 “舵手”,从这两个名字可以大致猜出他们的关系。
那 K8S 到底算是啥?这得从编排工具说起,之前学过了一个编排工具,swarm。
总而言之,编排工具就是能够扩展管理容器,能实现多跨多主机通信,能够指定容器中的运行关系,从而实现让复杂的程序运行变得简单的一个工具。
就目前而言,有几款比较出名的:
1. docker 本身的:docker machine + swarm + compose。
2. mesos + marathon:系统资源调度,能够调度 hadoop 或者容器,多以他并不算专业的容器编排工具。
3. Kubernets(K8S):将容器归类,以 Pod 管理。属于业界标准。
和 docker 一样,K8S 也是 Go 语言开发的,由谷歌根据自己内部容器调度系统 Borg 重写。由此可以看出 Go 在未来的地位。
为啥选择 K8S:
1. 自动装箱,自动部署,保证服务可用性。
2. 自我修复,在某个容器 down 掉以后会自动启动新的。
3. 自动水平扩展,服务发现,负载均衡。
4. 自动发布,回滚。
5. 支持密钥和配置管理,能够将服务的配置通过服务来加载,而不用本地配置,保证了配置的一致性。
6. 存储编排和任务批处理。
其实这些说出来,很干涩,也很懵逼,后面慢慢通过实践来理解。
K8S 集群
在 K8S 集群中,由两种角色:Master 和 Node,这和 docker swarm 类似,Master 和 Worker,也可以将 Worker 叫做 Node。
Master 作为集群的总控制,这就意味着不能是单节点,得让他高可用,但现在是测试,我们还是将其部署为单节点。
Node 就是干活的节点,这个就是没啥数量限制了,大于 1 就行了。用于运行 Pod。
那啥是 Pod?Pod 是 K8S 能够调度的最小单位,而不是 docker 容器。Pod 是将一个或多个关系非常密切的容器打包在一起的集合。
而管理 Pod 怎么运行,运行多少个,使用多少资源,这些都是 Master 的活。
以搭建 LAMP 环境为例,这几个看似有很大的关系,但是他们关系又不是非常紧密,所以对于这种服务,一般将其拆开运行为 3 个 Pod。
K8S 内部通信一共需要 5 套证书:
1. etcd 内部通信需要 CA 和对应证书。
2. etcd 与外部通信需要 CA 和对应证书。
3. APIServer 间通讯需要一套证书。
4. APIServer 与 Node 通信需要一套证书。
5. Node 与 Node 间通信需要一套证书。
而这些证书,可以选择手动创建,也可以自动生成。
这里得说明一件事情:
K8S 真香,但这并不意味着我们的所有服务都适合在上面运行,为了便于维护,建议有状态的应用都单独运行,类似数据库这种。
看下一个通用的集群架构:
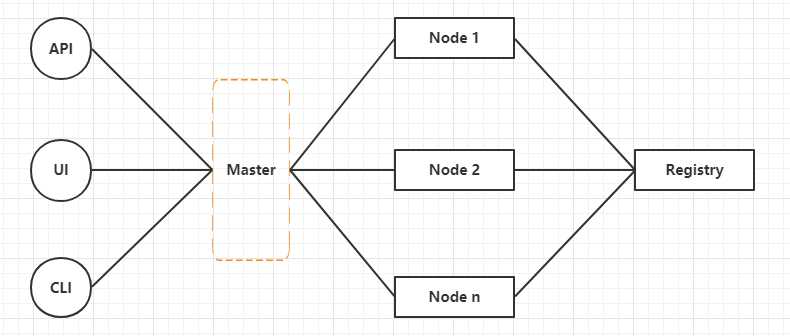
简单来说,Master 通过 API 来管理 Node 节点,Node 节点运行服务从 Registry 中拉取镜像。
然后再将 Master 和 Node 进行细化:
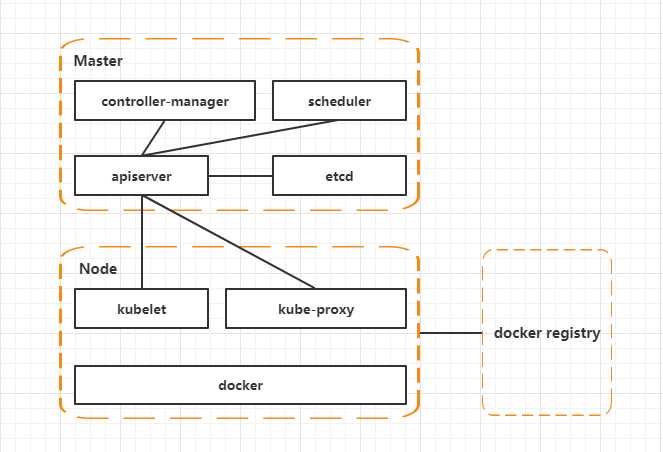
Master 有三个重要组件:
1. APIServer:请求入口,负责解析,处理请求,即网关。
2. Scheduler:调度器,请求到达后,计算 Node 的资源情况,将服务调度到适合的 Node,然后该节点的 Kubelet 启动和操作 Pod。
3. Controller-manager:控制管理器,统一管控资源,监控 Master 节点的健康状态,给 Master 节点做高可用。
Controller:控制器,用于创建启动 Pod。通过标签选择器(Label Selector)来关联 Pod,管理 Pod 的健康性,以确保 Pod 的运行数量为用户定义的。
每一组 Pod 都需要独立的控制器来运行,实现跨节点的自愈。
在 K8S 中,控制器一般有以下几种:
1. ReplicationController:严格控制 Pod 数量和更新的 Pod,在更新过程中会临时超出预定的 Pod 数量,支持回滚。
2. RelicaSet:声明更新控制器。
3. Deployment:负责无状态应用 Pod 控制,支持二级控制器。
4. StatefulSet:负责有状态 Pod 控制。
5. DeamonSet:守护进程集,在集群的每个 Node 上启动一个 Pod,如果 Pod 挂掉,会重新起一个,如果新增 Pod,会自动添加。
6. Job/Cronjob:周期性 Pod 控制,如定时任务。
Master 节点其他组件:
Label Selector:标签选择器,根据标签选择符合条件的资源对象机制,不仅用于 Pod 资源,所有对象都可以打标签,K/V 格式数据。Controller 可以根据这个标签识别 Pod 资源。
etcd:分布式高性能键值存储数据库,保存集群对象状态信息。apiserver 的所有操作都保存在这里,这意味着,这个服务挂了整个集群就瘫痪了。前面 docker 中用它来跨主机通信。
Node 节点有三个重要组件:
1. Kubelet:相当于 K8S 的 agent,有点像 Zabbix 的 agent。检测当前节点的健康状态,和 apiserver 交互。
2. Kube-proxy:为当前节点的 Pod 生成 iptables 或者 ipvs 规则将请求调度到 Pod。和 apiserver 进行通信,当自身改变或者 apiserver 发生改变都能做到及时更新规则。包含 3 个模型:userspace/iptables/ipvs。
3. Container engine:这里没有说 docker,是因为 K8S 不只是编排 docker。
标签:try arm 实现 pvs sch 节点 周期性 图片 swa
原文地址:https://www.cnblogs.com/Dy1an/p/10796903.html