标签:单元 war 初始化 启发式 知识 其他 rgb 一个 高斯分布
url: https://arxiv.org/abs/1812.01187
year: 2018
文中介绍了训练网络的一些 tricks, 通过组合训练过程的trick,来提高模型性能和泛化能力,以及迁移学习的性能。总的来说,这篇文章是一篇实用性极强的文章,也是需要亲自调试才能明白其好处的文章。
baseline training:
baseline validation:
文中指出,直接使用大的batch size可能会减缓训练过程的速度,因为对于凸优化问题,收敛的速率会随着batch size增大而降低。与此同时,在训练同样的epoches的前提下,用一个更大的batch size训练会导致模型验证集准确率的降低。
[摘自深度学习花树]
就统计而言, 我们可以将机器学习问题看成利用已有数据去预测数据的真实分布过程的, 我们期望模型学习到的分布接近于数据的真实分布. 在训练模型时候, 我们一般迭代的采样 m 个的样本送入模型来估计数据的真实分布.
就服从高斯分布的样本而言, m 个样本均值的标准差是 \(\frac{\sigma} {m}\),其中 \(\sigma\) 是样本值真实分布的标准差。分母 \(\sqrt{m}\) 表明使用更多样本来估计梯度的方法的回报是低于线性的。 举例如下,一个基于 100 个样本,另一个基于 10000 个样本。 后者需要的计算量是前者的 100 倍,但却只降低了 10 倍的均值标准差。
 ?
?
 ?
?
许多工作用来启发式的解决这个问题。文中介绍了四种方法。
Linear scaling learning rate
梯度下降是一个随机过程,增大batch size没有改变随机梯度的期望,但是减小了它的方差。换句话说,增大学习率减小了梯度中的噪声(noise),所以,我们应该增大学习率来进行调整。例如我们在 batch size=256 的时候使用的lr为0.1,那么 batch size 为 b 的时候,学习率应调整为 \(\frac {0.1 \cdot b}{256}\).
Learning rate warmup.
在训练刚开始的时候,所有的参数都是随机值,离最终的结果偏离比较大,如果直接使用较大的lr会造成数值的不稳定(numerical instability),所以我们可以先用一个较小的lr,当训练过程稳定的时候再调回初始的学习率。假设我们前m个batches是用来warmup的,我们设置的初始lr为 \(\eta\) ,那么当 \(1\leq i\leq m\) 的时候,学习率应该被设置为 \(i\eta /m\)
Zero \(\gamma\)
Resnet每一个block最后一层使用了Batch Normalization(BN)层,BN层首先标准化其输出,记为 \(\widehat{x}\), 然后进行尺度的变换,即 \(\gamma \widehat{x}+\beta\) 。其中, \(\gamma\) 和 \(\beta\) 都是可学习的参数,分别被初始化为1和0。而zero \(\gamma\) 策略指的是,将所有残差块最后的BN层的 \(\gamma\) 参数初始化为0,就相当于减少了层数使得初始阶段更加易于训练。
No bias decay.
一般的是将weight decay应用在所有可学习的参数上,包括weights和bias。然而,更推荐的做法是,只将L2正则化项应用在weights上来避免过拟合。其他参数,包括BN层里的 \(\gamma\) 和 \(\beta\) 都是不经过正则化的。
一般的NN是在32-bit浮点数上(FP32)训练的,但随着硬件中增加了对一个低精度数据类型的处理单元,对处理像FP16这样的数据具有更高的算力(FLOPS),使用这种数据类型的数据进行训练的话,容易出现的问题是结果会超出范围从而影响训练过程。有人就提出用FP16对所有的parameters和activations进行存储和梯度的计算,与此同时使用FP32对参数进行拷贝用于参数的更新。另外,在损失函数上乘以一个标量来将梯度的范围更好的对齐到FP16也是一个实用的做法。
文中第四部分是对Resnet-50模型架构的修改尝试。图1是原始的resnet,图2是经过修改的三种模型。
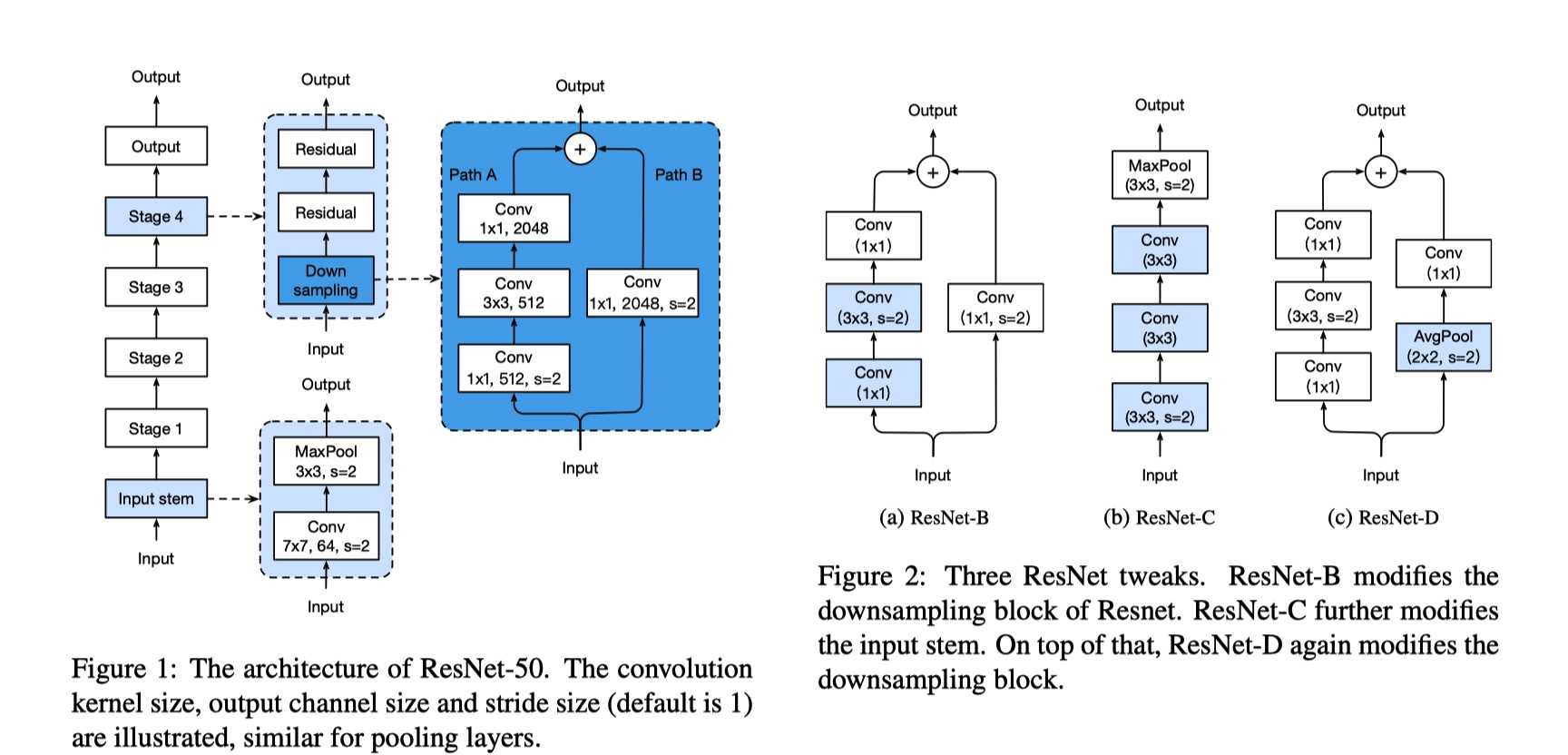 ?
?
如图2所示,其中ResNet-B和ResNet-D模型架构修改的思想是修改特定层的strides参数,目的是为了不让11的卷积层的strides大于1,从而避免了特征的丢失。而ResNet-C的想法是使用多个小的卷积核3 3代替大的 7 * 7 的卷积核。实验结果如表5所示。
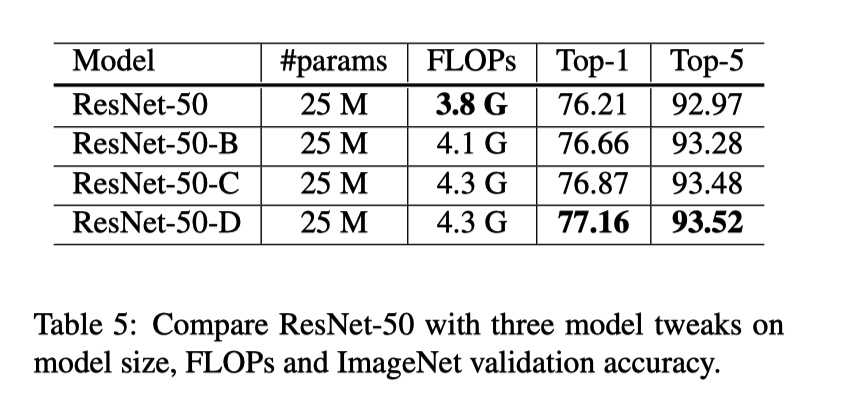 ?
?
文章中第五部分是通过训练过程中的一些策略来进一步提升模型的准确率。
被广泛使用的策略是学习率指数下降,也有的是每30 epoches学习率减为0.1倍的.即Step Decay.还有的是每两个epoches降低为0.94倍的。顾名思义,余弦下降即,
\(\eta _{t} = \frac{1}{2}(1+cos(\frac{t\pi}{T}))\eta\)
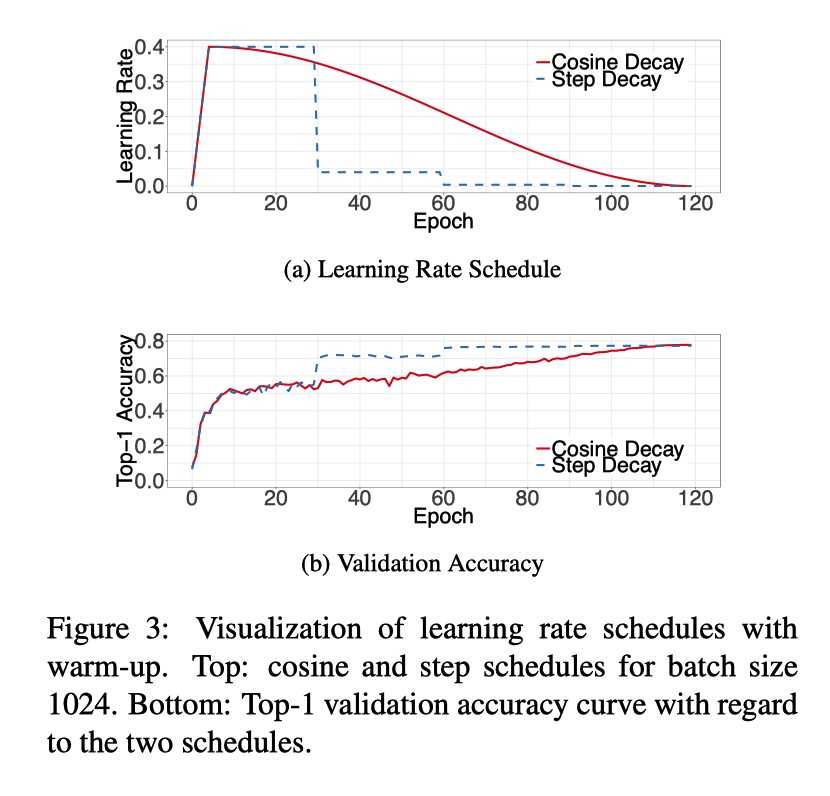 ?
?
分类问题中one-hot标签存在的问题是,encourage输出score极大限度的区分度高容易导致过拟合,无法保证模型的泛化能力。为了是模型less confident,我们对训练标签做label smoothing。
\(new\_onehot\_labels = onehot\_labels * (1 - label\_smoothing) + label\_smoothing / num\_classes\)
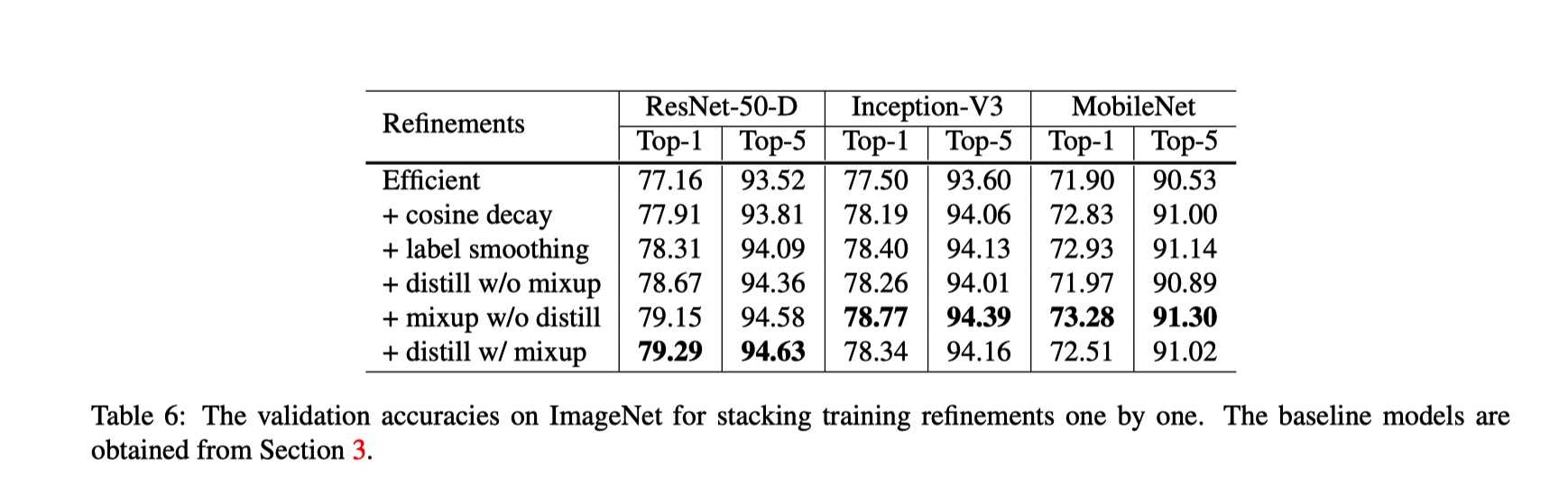 ?
?
知识蒸馏的做法是用一个更复杂的teacher model来监督一个student model,目的是为了压缩一个大的网络结构到一个更为紧凑的网络并把知识保留下来。若z和r分别是student model和teacher model的输出,p是真实标签的分布,那么此时的损失函数为,
\(l(p,softmax(z))+T^{2}l(softmax(r/T),softmax(z/T))\)
其中,T是超参数代表temperature.
混合训练即随即将两个样本 \((x_i,y_i)\) 和 \((x_j,y_j)\) 进行加权线性插值,其结果作为新的样本用于训练。
\[\left\{\begin{matrix} \widehat{x} = \lambda x_i +(1-\lambda )x_j \\ \widehat{y} = \lambda y_i +(1-\lambda )y_j \end{matrix}\right. \]
其中, \(\lambda\in[0, 1]\) 是从 \(Beta(\alpha, \alpha)\) 分布中的随机值。
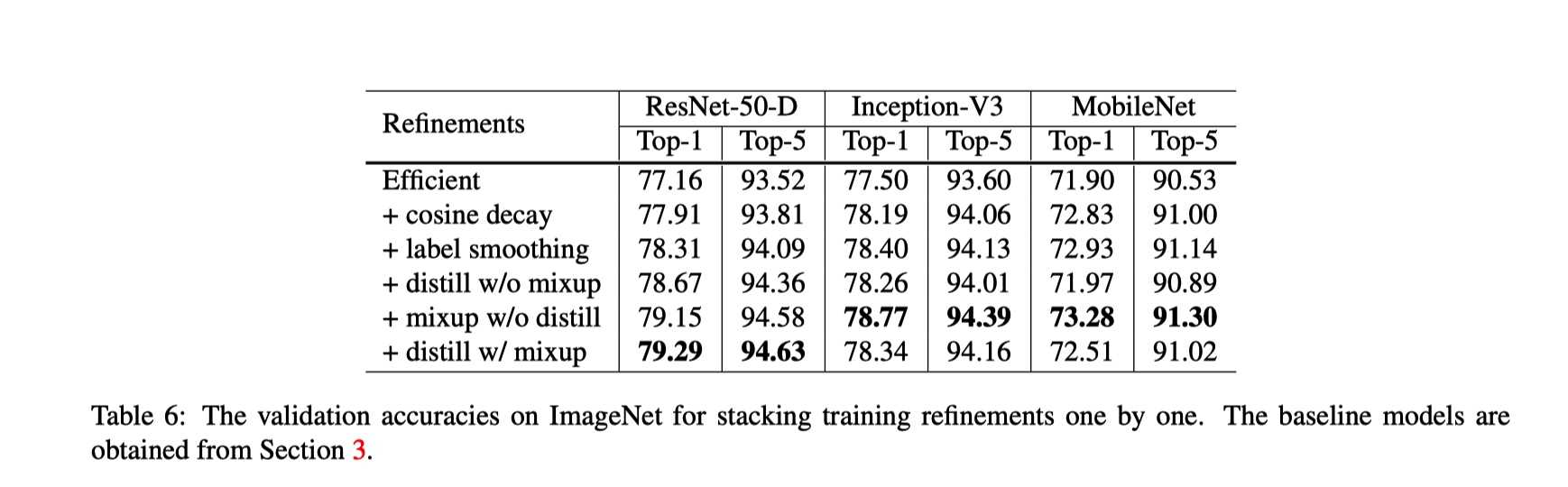 ?
?
之所以称之为Tricks,我们也知道在实际应用中是否有效还得看面向不同数据集的具体的任务,需要我们耐心的尝试,才能找到一个相对最优的方案。
reference:
Bag of Tricks for Image Classi?cation with Convolutional Neural Networks
标签:单元 war 初始化 启发式 知识 其他 rgb 一个 高斯分布
原文地址:https://www.cnblogs.com/nowgood/p/tricksofclassication.html