标签:个数 数据引擎 全表扫描 may 名称 保存 一起 变量 任务
将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来, 那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令,可以类似把他看成java的封装了一个方法,他里面有1W行SQL,之后翻遍
存储过程的优点: 1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。 2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。 3.存储过程可以重复使用,可减少数据库开发人员的工作量 4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权
存储过程的缺点
1.SQL本身是一种结构化查询语言,加上了一些控制(赋值、循环和异常处理等),但不是OO的,本质上还是过程化的,面对复杂的业务逻辑,过程化的处理会很吃力。这一点算致命伤。
2.不便于调试。基本上没有较好的调试器,很多时候是用print来调试,但用这种方法调试长达数百行的存储过程简直是噩梦。好吧,这一点不算啥,C#/java一样能写出噩梦般的代码。
3.没办法应用缓存。虽然有全局临时表之类的方法可以做缓存,但同样加重了数据库的负担。如果缓存并发严重,经常要加锁,那效率实在堪忧。
4.无法适应数据库的切割(水平或垂直切割)。数据库切割之后,存储过程并不清楚数据存储在哪个数据库中。
1.3:SQL存储过程的实际操作
创建一个存储过程
#可以看成一个函数的创建 create procedure user_porced () begin select name from users; end;
调用存储过程
call porcedureName ();
传参的创建一个存储过程
create PROCEDURE user_porcedPa( in a int(10) )
begin
select name from users where age>a;
end;
①使用group by 分组查询是,默认分组后,还会排序,可能会降低速度, 在group by 后面增加 order by null 就可以防止排序. explain select * from emp group by deptno order by null; ②有些情况下,可以使用连接来替代子查询。因为使用join,MySQL不需要在内存中创建临时表。 select * from dept, emp where dept.deptno=emp.deptno; [简单处理方式] select * from dept left join emp on dept.deptno=emp.deptno; [左外连接,更ok!] ③对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 最好不要给数据库留 NULL,尽可能的使用 NOT NULL 填充数据库. 备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用 NULL。 不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL 也包含在内),都是占用 100 个字符的空间的,如果是 varchar 这样的变长字段, null 不占用空间。 可以在 num 上设置默认值 0,确保表中 num 列没有 null 值,然后这样查询: select id from t where num = 0 更多mysql sql语句调优查看http://bbs.itmayiedu.com/article/1511164574773
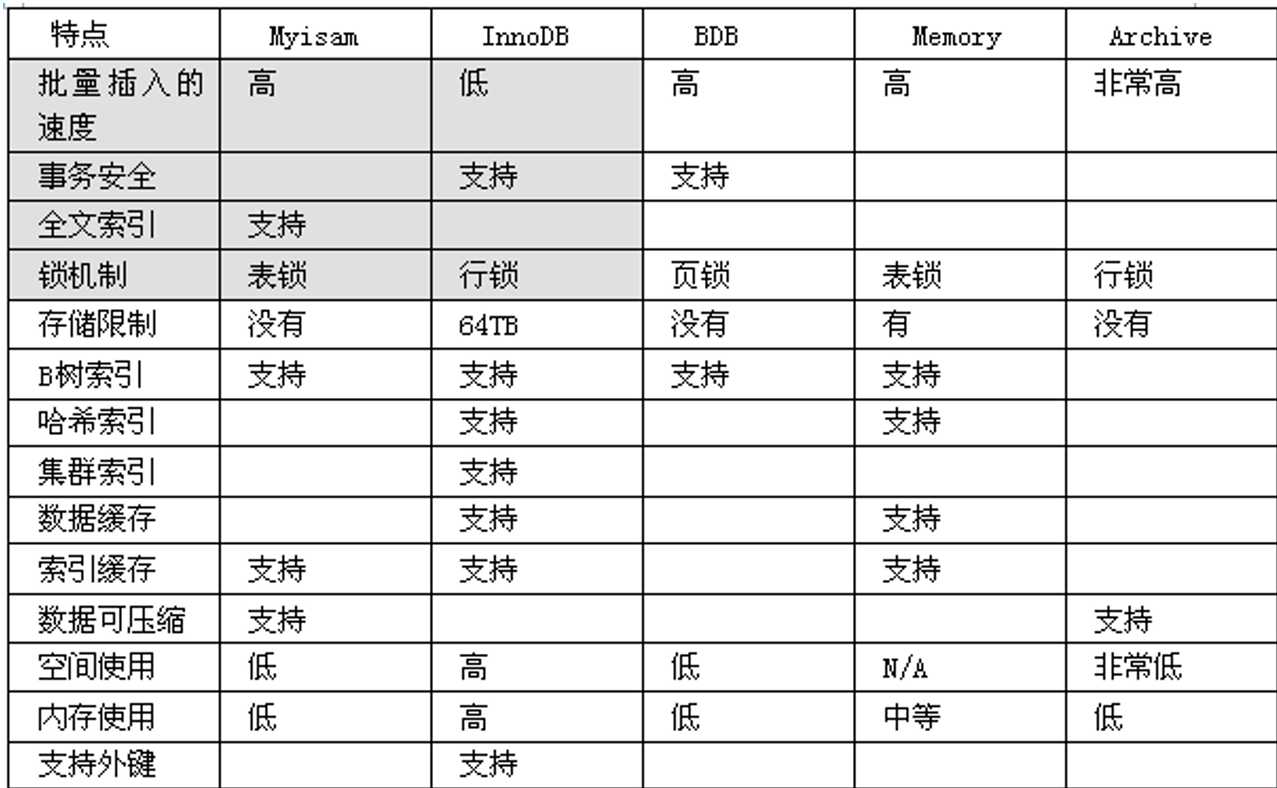
使用的存储引擎 myisam / innodb/ memory
myisam 存储: 如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎. ,比如 bbs 中的 发帖表,回复表.
INNODB 存储: 对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表.
MyISAM 和 INNODB的区别
1. 事务安全(MyISAM不支持事务,INNODB支持事务)
2. 查询和添加速度(MyISAM批量插入速度快)
3. 支持全文索引(MyISAM支持全文索引,INNODB不支持全文索引)
4. 锁机制(MyISAM时表锁,innodb是行锁)
5. 外键 MyISAM 不支持外键, INNODB支持外键. (在PHP开发中,通常不设置外键,通常是在程序中保证数据的一致)
Memory 存储,比如我们数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory, 速度极快. (如果mysql重启的话,数据就不存在了)
如果你的数据库的存储引擎是myisam,请一定记住要定时进行碎片整理
因为在我们进行插入数据的时候,即便删除数据,文件中的碎片其实也并没有删除,我们进行碎片的删除
举例说明:
create table test100(id int unsigned ,name varchar(32))engine=myisam;
insert into test100 values(1,’aaaaa’);
insert into test100 values(2,’bbbb’);
insert into test100 values(3,’ccccc’);
我们应该定义对myisam进行整理
optimize table test100;
cmd控制台:
在环境变量中配置mysql环境变量
mysqldump –u -账号 –密码 数据库 [表名1 表名2..] > 文件路径
案例: mysqldump -u -root root test > d:\temp.sql
如果你希望备份是,数据库的某几张表
mysqldump -u root -proot test(那个数据库) dept(数据库的那个表) > f:\temp.dept.sql(另存为哪里)
如何使用备份文件恢复我们的数据.
mysql控制台
source d:\temp.dept.bak
把备份数据库的指令,写入到 bat文件, 然后通过任务管理器去定时调用 bat文件.
mytask.bat 内容是:
@echo off
F:\path\mysqlanzhuang\bin\mysqldump -u root -proot test dept > f:\temp.dept.sql
创建执行计划任务执行脚本。
标签:个数 数据引擎 全表扫描 may 名称 保存 一起 变量 任务
原文地址:https://www.cnblogs.com/itcastwzp/p/11005501.html