标签:因子 app 效果 block text image sqrt 贪婪 play
差分进化是在遗传算法的基础上发展而来的,与遗传算法相似,有变异、交叉、选择等操作,但是实现简单,收敛速度快。差分进化的过程是随机生成一个初始化群体,经过交叉、变异、选择三个操作,反复迭代,保留有用的个体,寻找最优解。
差分进化利用了贪婪的思想,在每一次的迭代中,保留最优解。通过当前种群个体跟经过交叉、变异后的个体以适应度值为标准,进行比较,保留最优的个体。
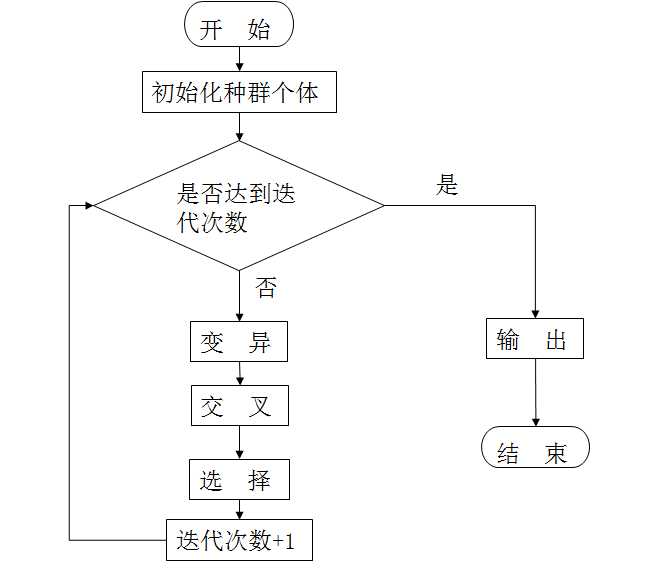
(1)初始化
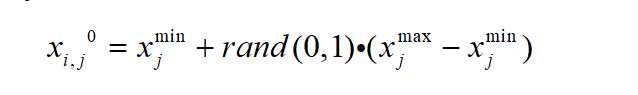
(2)变异
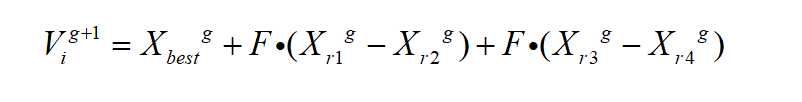
(3)交叉
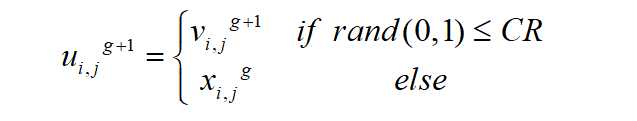
(4)选择
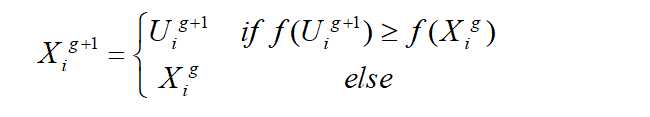
其中,F是变异因子,用来控制两个随机个体差分向量的缩放程度。CR是交叉概率,用来控制进化发生的几率,CR的值越大,则变异个体对试验个体的贡献多,CR的值小,则种群个体对试验个体的贡献多。
差分进化算法描述:

差分进化算法优化参数时,关键是适应度值的计算,初始化、变异、交叉操作,是以种群个体为操作对象,代码实现可以通用,适应度值的计算需要考虑优化的目标。
利用集成学习的方法,选择五种分类器,把每个分类器权重作为差分进化中的种群个体,作为被优化的对象,这样每个个体的维度就是5,一个个体就是一个解向量。
计算适应度值:分别将当代种群个体和经过变异、交叉操作后得到的试验个体的分量作为个体分类器的权重,在数据集上通过加权集成分类结果,得到所有样本的输出,计算分类准确率,将其作为适应度值。
适应度值计算:
def fitness(w): #计算适应度值函数 trainX, Y_train, testX, Y_test = classifier.feature_sec() predict = [] m = classifier.Y_test.shape[0] #for Xi in model.testX: clf1 = classifier.clfLR(trainX, Y_train, testX, Y_test) clf2 = classifier.clfLDA(trainX, Y_train, testX, Y_test) clf3 = classifier.clfNB(trainX, Y_train, testX, Y_test) clf4 = classifier.clfSVM(trainX, Y_train, testX, Y_test) clf5 = classifier.clfPLA(trainX, Y_train, testX, Y_test) f1 = np.array(clf1.predict_proba(testX)) f2 = np.array(clf2.predict_proba(testX)) f3 = np.array(clf3.predict_proba(testX)) f4 = np.array(clf4.predict_proba(testX)) f5 = np.array(clf5._predict_proba_lr(testX)) fit = w[0]*f1 + w[1]*f2 + w[2]*f3 + w[3]*f4 + w[4]*f5 # print("f1",f1) # print("fit:",fit) # s = 0.5 * sum(w) print("w,s:",w) # for i in range(m): # fit = w[0]*f1[i] + w[1]*f2[i] + w[2]*f3[i] + w[3]*f4[i] # if fit >= s: # predict.append(1) # else: # predict.append(0) for fitprob in fit: if fitprob[0]>fitprob[1]: predict.append(0) else: predict.append(1) #print("predict:",predict) #print("Ytest shape:",classifier.Y_test.shape) # TP=TN=FP=FN = 0 # print(m) # for k in range(m): # if Y_test[k]==1 and predict[k]==1:TP += 1 # elif Y_test[k]==0 and predict[k]==0: TN += 1 # elif Y_test[k]==0 and predict[k]==1:FP += 1 # elif Y_test[k]==1 and predict[k]==0:FN += 1 # TP = sum(classifier.Y_test == predict == 1) #将正类预测为正类的样本数 # TN = sum(classifier.Y_test == predict == 0) #将负类预测为负类的样本数 # FP = sum(classifier.Y_test == 0 and predict == 1) #将负类预测为正类的样本数 # FN = sum(classifier.Y_test == 1 and predict == 0) #将正类预测为负类的样本数 # F1 = 2*TP/(2*TP+FN+FP) #F值越大,说明实验效果越好 #Gmean = math.sqrt((TP/(TP+FN))*(TN/(TN+FP))) #用G-mean评价分类器性能 count = sum(predict==Y_test) print("Accuracy,F1 is:",count/m) return count/m
标签:因子 app 效果 block text image sqrt 贪婪 play
原文地址:https://www.cnblogs.com/moonyue/p/11000049.html