标签:打开 编译器 容器适配器 files 内核 数据排列 示例 功能 strong
一、C++标准库介绍
C++标准库:C++ Standard Library
C++标准库与STL有什么关系:
STL:Standard Template Library
STL包含6大部件,基本占标准库的80%左右内容,而另外20%是一些好用的零碎的东西,所以说C++标准库包含STL。
常用写法:
#include <iostream> #include <string> #include <vector> #include <algorithm> #include <functional> //打开std命名空间 using namespace std;
二、STL六大部件
STL的六大部件分别是:
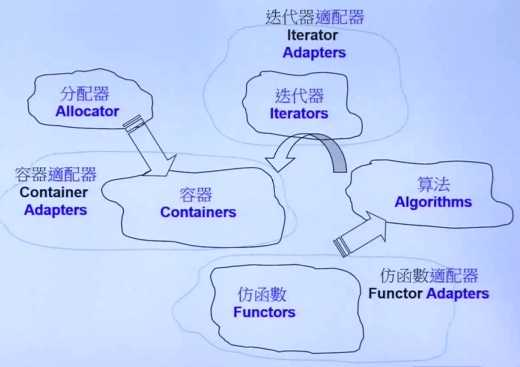
其中容器和算法是最重要的两大部件。以前有句老话叫做“数据结构加算法就等于程序”,在这句话中,容器就是数据结构,是一个优秀的团队将常用的数据结构都在STL中实现了。同样的,常用算法也在STL算法部件中实现。所以掌握了C++标准库的时候,可以避免重复造轮子的问题,而且库中提供的功能都经过无数次的优化,性能有很好的保证。
六大部件简要介绍:
容器:容器是一堆常用数据结构的实现,主要用户存放和读取数据,屏蔽了底层的内存分配和释放的问题,所以能够让用户更方便和高效的使用。
分配器:容器对数据结构的封装,要处理内存分配和释放的问题,就用到了分配器。
算法:既然容器用来存取数据,相当于一个数据的仓库,那么算法就是用来处理这些数据的工具。在STL中,算法和容器是分开设计的,这和面向对象(OO)有点不符,在面向对象中,我们一般将数据和方法封装在一个类中,而在STL中,使用的是模板式编程,是另外一条路线。
迭代器:我们的算法要操作容器中的数据。如何将两者结合起来,就需要一个桥梁,这个桥梁就是迭代器。迭代器可以看成是一种泛化的指针。
仿函数:比较抽象,后面解释。
适配器:用于做一些转换,例如容器适配器、仿函数适配器、迭代器适配器。
三、六大部件示例

上图中程序解释:(其中将六大部件综合在一起展示)
1.在第11行,定义一个容器vector,模板参数为<int, allocator<int>>,其中第一个int代表vector要装的数据类型,后面的allocator<int>是一个内存分配器,用于vector的内存分配。这个分配器是一个可选项,如果不写,标准库源码中有一个默认的分配器给vector,分配器也是一个模板,模板参数必须和容器的第一模板参数匹配,这里是int。
2.定义vector变量vi,构造函数选用的是将数组ia的第一个位置和最后一个位置作为参数。
3.在第13行,选用了一个叫做count_if()的算法来处理容器vi。这个算法的作用是对vi中满足一定条件的元素进行计数。
4.count_if()的参数分别是指向容器开头的迭代器(泛化指针)、指向容器结尾的迭代器以及对元素的过滤条件。vi.begin()返回的是指向开头的迭代器,vi.end()返回的是指向结尾的迭代器。
5.less<int>()是一个仿函数,用于比较大小。
6.bind2nd(less<int>(), 40)是一个适配器,意思是将第二个参数也就是整数40,绑定到less<int>()。意思就是小于40的整数。
7.not1()函数也是一个适配器,意思是取反义,也就是将小于40,变为大于等于40。
8.最后的输出就是vi中大于等于40的元素的个数,结果为4。
四、算法效率介绍
每个人都想用效率最高的东西和方法,那位什么标准库还要提供十个八个容器和一大堆算法呢?
因为每个人的需求不同,例如数据分布、数据排列方式、数据处理需求都不一样。没有一个特定的容器或算法能够适应所有的需求。所以我们必须根据不同的需求来选择不同的容器和算法。
如何评价容器或算法的效率,我们经常会使用复杂度(Complexity)或O()(big-oh)来衡量。
主要的复杂度有以下一些:
1.O(1)或O(c):常数时间(constant time)
2.O(n):线性时间(linear time)
3.O(log2n):以2为底n的对数,次线性时间(sub-linear time)
4.O(n2):n的平方,平方时间(quadratic time)
5.O(n3):n的立方,立方时间(cubic time)
6.O(2n):2的n次方,指数时间(exponential time)
7.O(nlog2n):介于线性与平方的中间模式。
这里面的n必须是一个很大的数(几十万甚至更大)才有实际的意义,因为当n很大时,各个复杂度之间的效率千差万别。而如果n很小,例如一些玩具程序,那对于计算机的计算速度,效率之间差距就没什么意义了。
五、区间表示法
我们对一个范围的表示一般有三种方式:
1.[ ]:闭区间,即包含前后的元素。
2.( ):开区间,即前后元素都不包含。
3.[ ):前闭后开区间,即包含前面的元素,不包含后面的元素。
在C++标准库中,选择第3种作为区间表示,也就是前闭后开。

如上图所示,c是一个容器对象,c.begin()返回一个迭代器(泛化指针),这个迭代器指向容器的第一个元素的地址。c.end()也返回一个迭代器,这个迭代器指向容器最后一个元素后下一个地址,但是那个地址所保存的东西,根本不是这个容器所拥有的。所以,使用*(c.end())所取到的数据是没有意义的(可能导致程序崩溃)。
上图中展示了如何使用迭代器和for循环来遍历容器中的元素。代码如下:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; //定义容器,将数组arr的数据放入容器中 vector<int> vi(arr, arr + 10); //获取容器开头的迭代器 vector<int>::iterator bg = vi.begin(); //当bg不等于vi.end()时,也就是说还有滑到容器的最后,打印bg指向的数据,并滑向下一个位置 for (; bg != vi.end(); bg++) { cout << *bg << endl; }
另一种遍历的做法(C++11新特性):(参照笔记:C++程序设计2里的第十四节 基于range的for循环)
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; //定义容器,将数组arr的数据放入容器中 vector<int> vi(arr, arr + 10); //使用auto可以让编译器自己推导类型,当然也可以写for(int i : vi){} for (auto i : vi) { cout << i << endl; }
标签:打开 编译器 容器适配器 files 内核 数据排列 示例 功能 strong
原文地址:https://www.cnblogs.com/leokale-zz/p/11100566.html