标签:深搜 ati 转移 核心 技术 bit ima 标题 png
▎前言
看到这个标题,你是不是倍感疑惑,为什么会是搜索+,而不是搜索,会不会是小编打错的,其实本篇博客将会让你看到搜索的各种玩法。
▎前置技能
?『基础知识』
?『dfs和bfs的异同点』
相同点:dfs和bfs都用于搜索,都是来寻找点的。
不同点:dfs以深度为优先,不撞南墙不回头,一鼓作气搜遍一条路,所以比较不靠谱,但是代码量少,也好写,大部分人都喜欢用。而bfs则是以广度为优先,逐层遍历,相比dfs来说更加理性,但是当状态不好存储时,就只能用dfs了。
▎dfs+bfs:传说中的bdfs
?『迭代加深搜索』
其实没有bdfs,人家的真名叫迭代加深搜索。
如果你搜一下百度,那么度娘会告诉你:在计算机科学中,迭代深化搜索(iterative deepening search)或者更确切地说迭代深化深度优先搜索 (iterative deepening depth-first search (IDS or IDDFS)) 是一个状态空间(状态图)搜索策略。在这个搜索策略中,一个具有深度限制的深度优先搜索算法会不断重复地运行,并且同时放宽对于搜索深度的限制,直到找到目标状态。IDDFS 与广度优先算法是等价的,但对内存的使用会少很多;在每一步迭代中,它会按深度优先算法中的顺序,遍历搜索树中的节点,但第一次访问节点的累积顺序实际上是广度优先的。(copy自百度)
说了半天也什么也不懂,那么就来看一看引例吧。
?『引例』
例 – 埃及分数

这道题先来想bfs,如何存储状态,这显然是不好存储的。
用dfs呢?又表示很无力,因为不知道由几个分数组成,也不知道每个分母上限是是多大,dfs可能会一直搜下去,一条路走到黑。
怎么办呢?两种搜索都遇到了瓶颈,那么我们不妨结合一下两种搜索方式。
?『算法核心』
我们以dfs为主体,而dfs的缺点是越走越远,那么我们可以注入bfs的特性:逐层展开,我们不妨设置一个变量,用于存储层数,限制好dfs到达这一层就不允许继续搜索了。
这样不仅思路简单,还结合了两种搜索的方式。
?『算法模板』
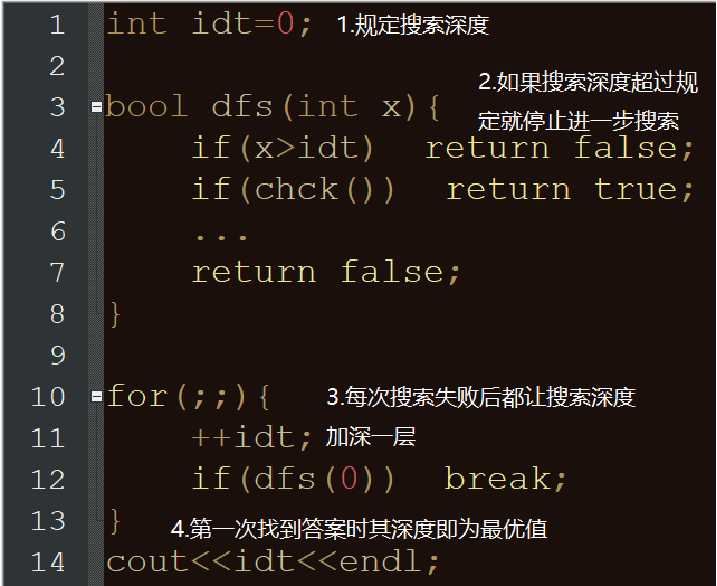
(copy自cdcq的ppt)
▎搜索+剪枝
如果将搜索的各状态间依据转移顺序连接好边,那么就会形成搜索树,而剪枝正是将无用的枝条剪去以增加效率。
▎搜索+状态压缩
?『状态压缩』
有时可能一张图不能用二维数组存下,原因是数据规模太大。
也可能是想优化一下算法的时间复杂度。
我们就可以用状态压缩,将图转化成二进制,一维数组即可存下整张图,或者使用lowbit也是优化算法的好办法。
?『引例』
?『状态压缩应用』
▎搜索+搜索
没错,这就是双向搜索。
双向BFS,就是在起点和终点都很清楚的情况下,把起点和终点同时入队,或者进两个队,共同进行bfs,当二者第一次相遇时为最优解。
目的是为了解决搜索访问状态太多的问题,时间复杂度比单向的搜索优化了不少。
标签:深搜 ati 转移 核心 技术 bit ima 标题 png
原文地址:https://www.cnblogs.com/TFLS-gzr/p/11248509.html