标签:隔离级别 singleton 生成 使用 creat post 包含 tor 实例
https://blog.csdn.net/a745233700/article/details/80959716
https://blog.csdn.net/qq_36520235/article/details/88257749
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
(1)BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能:
①继承MessageSource,因此支持国际化。
②统一的资源文件访问方式。
③提供在监听器中注册bean的事件。
④同时加载多个配置文件。
⑤载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层。
(2)①BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
②ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
③相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
(3)BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
(4)BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
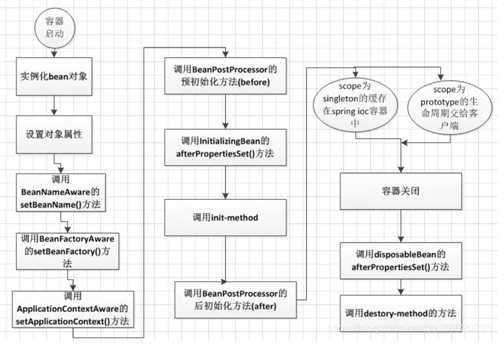
首先说一下Servlet的生命周期:实例化,初始init,接收请求service,销毁destroy;
Spring上下文中的Bean生命周期也类似,如下:
(1)实例化Bean:
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。
对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
(2)设置对象属性(依赖注入):
实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息 以及 通过BeanWrapper提供的设置属性的接口完成依赖注入。
(3)处理Aware接口:
接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean:
①如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的就是Spring配置文件中Bean的id值;
②如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory()方法,传递的是Spring工厂自身。
③如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文;
(4)BeanPostProcessor:
如果想对Bean进行一些自定义的处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
(5)InitializingBean 与 init-method:
如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
(6)如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了。
(7)DisposableBean:
当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用其实现的destroy()方法;
(8)destroy-method:
最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
首先从大的几个核心步骤来去说明,因为Spring中的具体加载过程和用到的类实在是太多了。
(1)、首先是先从AbstractBeanFactory中去调用doGetBean(name, requiredType, final Object[] args, boolean typeCheckOnly【这个是判断进行创建bean还是仅仅用来做类型检查】)方法,然后第一步要做的就是先去对传入的参数name进行做转换,因为有可能传进来的name=“&XXX”之类,需要去除&符号
(2)、然后接着是去调用getSingleton()方法,其实在上一个面试题中已经提到了这个方法,这个方法就是利用“三级缓存” 来去避免循环依赖问题的出现的。【这里补充一下,只有在是单例的情况下才会去解决循环依赖问题】
(3)、对从缓存中拿到的bean其实是最原始的bean,还未长大,所以这里还需要调用getObjectForBeanInstance(Object beanInstance, String name, String beanName, RootBeanDefinition mbd)方法去进行实例化。
(4)、然后会解决单例情况下尝试去解决循环依赖,如果isPrototypeCurrentlyInCreation(beanName)返回为true的话,会继续下一步,否则throw new BeanCurrentlyInCreationException(beanName);
(5)、因为第三步中缓存中如果没有数据的话,就直接去parentBeanFactory中去获取bean,然后判断containsBeanDefinition(beanName)中去检查已加载的XML文件中是否包含有这样的bean存在,不存在的话递归去getBean()获取,如果没有继续下一步
(6)、这一步是吧存储在XML配置文件中的GernericBeanDifinition转换为RootBeanDifinition对象。这里主要进行一个转换,如果父类的bean不为空的话,会一并合并父类的属性
(7)、这一步核心就是需要跟这个Bean有关的所有依赖的bean都要被加载进来,通过刚刚的那个RootBeanDifinition对象去拿到所有的beanName,然后通过registerDependentBean(dependsOnBean, beanName)注册bean的依赖
(8)、然后这一步就是会根据我们在定义bean的作用域的时候定义的作用域是什么,然后进行判断在进行不同的策略进行创建(比如isSingleton、isPrototype)
(9)、这个是最后一步的类型装换,会去检查根据需要的类型是否符合bean的实际类型去做一个类型转换。Spring中提供了许多的类型转换器。
(1)工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
(2)单例模式:Bean默认为单例模式。
(3)代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
(4)模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
(5)观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现--ApplicationListener。
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。真正的数据库层的事务提交和回滚是通过binlog或者redolog实现的。
(1)Spring事务的种类:
spring支持编程式事务管理和声明式事务管理两种方式:
①编程式事务管理使用TransactionTemplate。
②声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
声明式事务最大的优点就是不需要在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明或通过@Transactional注解的方式,便可以将事务规则应用到业务逻辑中。
声明式事务管理要优于编程式事务管理,这正是spring倡导的非侵入式的开发方式,使业务代码不受污染,只要加上注解就可以获得完全的事务支持。唯一不足地方是,最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。
(2)spring的事务传播行为:
spring事务的传播行为说的是,当多个事务同时存在的时候,spring如何处理这些事务的行为。
① PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
② PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。‘
③ PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
④ PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
⑤ PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
⑥ PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
⑦ PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
(3)Spring中的隔离级别:
① ISOLATION_DEFAULT:这是个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别。
② ISOLATION_READ_UNCOMMITTED:读未提交,允许另外一个事务可以看到这个事务未提交的数据。
③ ISOLATION_READ_COMMITTED:读已提交,保证一个事务修改的数据提交后才能被另一事务读取,而且能看到该事务对已有记录的更新。
④ ISOLATION_REPEATABLE_READ:可重复读,保证一个事务修改的数据提交后才能被另一事务读取,但是不能看到该事务对已有记录的更新。
⑤ ISOLATION_SERIALIZABLE:一个事务在执行的过程中完全看不到其他事务对数据库所做的更新。
标签:隔离级别 singleton 生成 使用 creat post 包含 tor 实例
原文地址:https://www.cnblogs.com/dingpeng9055/p/11361349.html