标签:sof 自己 决定 localhost 垂直 desc red 排序 操作符
Sakila 数据库是 MySQL 官方提供的示例数据库,常用来做测试。https://dev.mysql.com/doc/sakila/en/sakila-installation.html
1、下载 sakila database :https://dev.mysql.com/doc/index-other.html
2、解压后会得到三个文件:
sakila-schema.sql:用于创建表结构和数据库sakila-data.sql:用于插入数据sakila.mwb3、进入 MySQL 中,创建数据库、数据表以及插入数据:
# 将路径替换成你自己的路径
mysql -u root -p
# 创建表结构
source C:/Users/hj/Desktop/sakila-db/sakila-db/sakila-schema.sql
# 插入数据
source C:/Users/hj/Desktop/sakila-db/sakila-db/sakila-data.sql如何发现有问题的 SQL?使用 mysql 慢查询日志对有效率问题的 SQL 进行监控:
# 查看慢查询日志是否开启,off 为关闭
show variables like 'slow_query_log';
# 查看 log_queries_not_using_indexes 是否开启
show variables like '%log%';
# 开启 log_queries_not_using_indexes
set global log_queries_not_using_indexes=on;
# 开启慢查询日志
set global slow_query_log=on;
# 查看慢查日志记录时间,0 表示时刻都会记录,生产环境中不能为 0
show variables like 'long_query_time';
# 设置查询记录的时间(即查询超过 0s 的SQL语句都会被记录在慢查日志中)
set global long_query_time=0;
# 查看慢查询日志存储位置
show variables like 'slow_query_log_file';
# 指定慢查询日志存储位置
set global show_query_log_file='/var/lib/mysql/homestead-slow.log';
# 记录没有使用索引的sql
set global log_queries_not_using_indexes=on;设置慢查日志记录大致流程如下:
查看慢查询日志是否开启 --> 查看 log_queries_not_using_indexes 是否开启 --> 开启慢查询日志 --> 开启 log_queries_not_using_indexes --> 设置慢查记录时间(查询时间)--> 执行 SQL 语句检查 --> 查看慢查日志所在位置 -->查看慢查日志内容慢查日志内容
TCP Port: 3306, Named Pipe: MySQL
Time Id Command Argument
# Time: 2019-07-01T03:03:13.305562Z
# User@Host: root[root] @ localhost [::1] Id: 8
# Query_time: 0.000434 Lock_time: 0.000135 Rows_sent: 10 Rows_examined: 10
use sakila;
SET timestamp=1561950193;
select * from film limit 10;mysqldumpslow(官方)
MySQL 官方提供的慢查日志分析工具,安装 MySQL 后就自带的。
# 查看参数列表,用的比较多的参数有 -s、-t 等
mysqldumpslow -h;
# 分析慢查询日志中前三条比较慢的sql
mysqldumpslow -t 3 /var/lib/mysql/homestead-slow.log | more ;
# 输出样式效果(次数、时间、锁、行、操作用户以及查询命令)
Count:1 Time:0.00s Lock=0.00s Rows=10.0
root[rppt]@localhost
select * from storept-query-digest 工具 比 mysqldumpslow 更详细全面。https://www.percona.com/doc/percona-toolkit/2.2/pt-query-digest.html
安装
yum install perl-DBI
rpm -ivh MySQL-shared-compat-5.6.31-1.el6.x86_64.rpm
yum install perl-DBD-MySQL
yum install perl-IO-Socket-SSL
yum install perl-Time-HiRes
rpm -ivh perl-TermReadKey-2.30-3.el6.rfx.x86_64.rpm
rpm -ivh percona-toolkit-2.2.19-1.noarch.rpm
# 需要的rpm包可以从这里下载:http://rpm.pbone.net/# 输出到文件
pt-query-digest slow-log > slow_log.report
# 输出到数据库
pt-query-digest slow.log -review h=127.0.0.1.D=test, p=root, P=3306,u=root,t=query_review --cretae-reviewtable --review-history t=hostname_slow基本使用:
# 查看参数列表
pt-query-digest --help
# 分析慢查询日志中前三条比较慢的sql
pt-query-digest /var/lib/mysql/homestead-slow.log | more
# 输出分为三部分
1.显示除了日志的时间范围,以及总的sql数量和不同的sql数量
2.Response Time:响应时间占比 Calls:sql执行次数
3.sql的具体日志剖析报告
报告中包括一共有 9.10k 个操作,1.17K 个语句,列举出语句执行时间,锁时间,剖析报告覆盖的时间等。
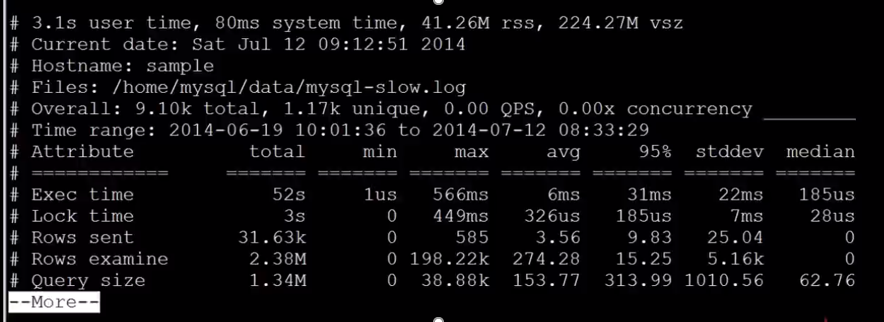
如何通过慢查询日志发现有问题的SQL?
# 查询次数多且每次查询占用时间长的SQL
通常为pt-query-digest分析的前几个查询
# IO大的SQL(数据库主要瓶颈出现在IO层次)
注意pt-query-digest分析中的Rows examine项
# 未命中索引的SQL
注意pt-query-digest分析中的Rows examine和Rows Send的对比Tips:pt-query-digest 只支持 Linux
参考文章:

explain 返回的每列的含义
1、Using filesort
使用文件排序的方式排序,当返回值是这个时,查询就需要优化了。表示 MySQL 需要进行额外的步骤来发现如何对返回的行排序,它根据连接类型以及存储排序键值和匹配条件的全部的行指针来排序全部行。
2、Using temporary
使用 临时表方式,当返回值为这个时,查询就需要优化了。MySQL 需要创建一个临时表来存储结果,通常发在对不同的列集进行 order by 上,而不是 group by 上。
Max()
Max() 优化查询,通常用 添加索引 的方式来解决:
未添加优化之前:
mysql> explain select max(payment_date) from payment \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: payment
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 16086 # MySQL 扫描的行数
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)添加索引:
mysql> create index ind_paydate on payment(payment_date); # 给 payment_date 列添加索引
Query OK, 0 rows affected (2.99 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select max(payment_date) from payment \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL # 扫描行数为 NULl,速度明显提升
filtered: NULL
Extra: Select tables optimized away
1 row in set, 1 warning (0.04 sec)
Count()
用来统计表中记录的一个函数,返回匹配条件的行数。
如何在一条 SQ L中同时查出 2006 年和 2007 年电影的数量--优化Count()函数
# 错误
select count(release_year='2006' or release_year='2007') from film;
# 正确
select count(release_year='2006' or NULL) as '2006年电影数量', count(release_year='2007' or NULL) as '2007年电影数
量' from film;
+---------------------+---------------------+
| 2006年电影数量 | 2007年电影数量 |
+---------------------+---------------------+
| 1000 | 0 |
+---------------------+---------------------+
1 row in set (0.00 sec)**Tips:count(*) 和 count(某列) 结果是不一样的**
count()语法:
**count(*)&count(1)&count(列名)执行效率比较:**
参考文章:https://blog.csdn.net/wendychiang1991/article/details/70909958/
通常情况下,需要把子查询优化为连接 join 查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据。(distinct去重)
内层查询结果作为外层查询的查询条件
mysql> select * from t;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
+----+
3 rows in set (0.00 sec)
mysql> select * from t1;
+------+
| tid |
+------+
| 1 |
| 1 |
+------+
2 rows in set (0.00 sec)
子查询:
# in 成员操作符,表示在xx里面,内层查询结果为 1 、1 ,外层查询 where t.id in (1, 1),返回 1,即只有一条
mysql> select * from t where t.id in (select t1.tid from t1);
+----+
| id |
+----+
| 1 |
+----+
1 row in set (0.00 sec)
连接查询:
mysql> select t.id from t join t1 on t.id=t1.tid;
+----+
| id |
+----+
| 1 |
| 1 |
+----+
2 rows in set (0.00 sec)连接查询要注意重复元素:
mysql> select distinct t.id from t join t1 on t.id=t1.tid; # 去重
+----+
| id |
+----+
| 1 |
+----+
1 row in set (0.00 sec)group by 分组查询,应避免使用临时表
使用临时表:
mysql> explain select actor.first_name, actor.last_name, count(*) from sakila.film_actor inner join sakila.actor using(actor_id) group by film_actor.actor_id \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200 # 扫描行数
filtered: 100.00
Extra: Using temporary # 使用临时表
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.05 sec)结合子查询和索引:
mysql> explain select actor.first_name, actor.last_name, c.cnt from sakila.actor inner join (select actor_id, count(*) as cnt from sakila.film_actor group by actor_id) as c using (actor_id) \G;
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
partitions: NULL
type: ref
possible_keys: <auto_key0>
key: <auto_key0>
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: film_actor
partitions: NULL
type: index
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 4
ref: NULL
rows: 5462
filtered: 100.00
Extra: Using index
3 rows in set, 1 warning (0.05 sec)
limit 常用于分页处理,时常会伴随 order by 从句使用,大多数时候回使用 Filesorts,这样就容易造成大量的 IO 问题。
# 查 5 条,51-55
explain select film_id, description from sakila.film order by title limit 50, 5 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: ALL # 使用哪种类型连接,index 要优于 all
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
filtered: 100.00
Extra: Using filesort # 使用文件排序
1 row in set, 1 warning (0.00 sec)
方法一:使用有索引的列或逐渐进行 order by 操作
mysql> explain select film_id, description from sakila.film order by film_id limit 50, 5 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 2
ref: NULL
rows: 55
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
方法二:记录上次返回的主键,在下次查询时使用主机过滤
此方法可以避免数据量大时扫描过多的记录,页数越大,IO越大
mysql> explain select film_id, description from sakila.film where film_id > 55 and film_id<=60 order by film_id limit 1, 5 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: range # 最好到最差 const、eq_reg、ref、range、index 和 ALL
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: NULL
rows: 5
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
select * from payment where staff_id = 2 and customer_id = 584;
# 是 index(staff_id, customer_id) 好?还是 index(customer_id, staff_id) 好?
# 由于 customer_id 离散度更大,所以应该使用 index(customer_id, staff_id)
# 查离散度
mysql> select count(distinct customer_id), count(distinct staff_id) from payment;
+-----------------------------+--------------------------+
| count(distinct customer_id) | count(distinct staff_id) |
+-----------------------------+--------------------------+
| 599 | 2 |
+-----------------------------+--------------------------+
1 row in set (1.04 sec)重复索引
指相同的列以相同的顺序建立的同类型的索引,如下面中的主键和 ID 列上的唯一索引就是重复索引:
create table test(
id int not null primary key,
name varchar(10) not null,
title varchar(50) not null,
unique(id)
)engine=innodb;冗余索引
指多个索引的前缀列相同,或是在联合索引中包含了主键的索引。如下:key(name,id)就是一个冗余索引
# 可以删除冗余索引,达到优化效果。
create table test(
id int not null primary key,
name varchar(10) not null,
key(name, id) # 联合索引中包含了主键的索引,ID 含有主键索引
)engine=innodb;mysql> use information_schema;
mysql> select a.table_schema as '数据名', a.table_name as '表名', a.index_name as '索引1', b.index_name as '索引2', a.colu
mn_name as '重复列名' from statistics a join statistics b on a.table_schema=b.table_schema and a.table_name=b.table_name a
nd a.seq_in_index = b.seq_in_index and a.column_name = b.column_name where a.seq_in_index = 1 and a.index_name <> b.index_name \G;
使用 pt-duplicate-key-checker 工具
# 使用 pt-duplicate-key-checker工具检查重复及冗余索引
pt-duplicate-key-checker -uroot -p '' -h 127.0.0.1
删除不用索引
目前mysql中还没有记录索引的使用情况,但是在PerconMySQL和MariaDB中可通过INDEX_STATISTICS表来查看哪些索引未使用,但在mysql中目前只能通过慢查日志配合pt-index-usage工具来进行索引使用情况分析。
使用 int 存储日期时间
利用 FROM_UNIXTIME()、UNIX_TIMESTAMP() 这两个函数来进行转换:
create table test(
id int auto_increment not null,
timestr int,
primary key(id)
);
insert into test(timestr) values(UNIX_TIMESTAMP('2019-07-13 13:12:00'));
select FROM_UNIXTIME(timestr) from test;
使用 bigint 存储 IP 地址
利用 INET_ATON()、INET_NTOA() 这两个函数来进行转换:
create table sessions(
id int auto_increment not null,
ipaddress bigint,
primary key(id)
);
insert into sessions(ipaddress) values(INET_ATON('192.168.0.1'));
select INET_NTOA(ipaddress) from sessions;
范式化是指数据库设计的规范,目前说到范式化一般是指第三设计范式,也就是要求数据表中不存在非关键字段对任意候选关键字段的传递函数依赖则符合第三范式。
下表存在一些传递函数依赖关系:商品名称 -> 分类 -> 分类描述,所有下表是一个非范式化
| 商品名称 | 价格 | 重量 | 有效期 | 分类 | 分类描述 |
|---|---|---|---|---|---|
| 可乐 | 3.00 | 250 ml | 2019.7.1 | 饮料 | 碳酸饮料 |
| 北冰洋 | 3.00 | 250 ml | 2019.8.1 | 饮料 | 碳酸饮料 |
不符合第三范式要求的表存在下列问题:
对于反范式化的数据表来说,最好的优化方法是将其拆分为多个表,但也不是拆分的越多越好,表越多连接查询越困难。上表中我们可以将分类单独拆分一个独立的表,然后与商品多对多连接。
反范式化是指为了查询效率的考虑把原本符合第三范式的表适当的增加冗余,以达到优化查询的目的,反范式化是一种以空间来换取时间的操作。
所谓的垂直拆分,就是把原来一个有很多列的表拆分成多个表,这解决了表的宽度问题。通常垂直拆分可以按以下原则进行:
表的水平拆分是为了解决单表的数据量过大的问题,水平拆分的表每一个表的结构都是完全一致的。
常用的水平拆分方法为:
数据库是基于操作系统的,目前大多数mysql都是安装在Linux系统之上,所以对于操作系统的一些参数配置也会影响到MYSQL的性能。
网络方面的配置,要修改/etc/stysctl.conf文件
#增加tcp支持的队列数
net.ipv4.tcp_max_syn_backlog = 65535
#减少断开链接是,资源回收
net.ipv4.tcp_max_tw_buckets = 8000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 10
打开文件数的限制,可以使用ulimit -a 查看目录的各位限制,可以修改/etcsecurity/limitsconf文件,增加一下内容以修改打开文件数量的限制
*soft nofile 65535
*hard nofile 65535
除此之外最好在mysql服务器上关闭iptables,selinux等防火墙软件。mysql可以通过启动时指定配置参数和使用配置文件两种方法进行配置,在大数情况下配置文件位于/etc/my.cnf或是/etc/mysql/my.cnf在windows系统配置文件可以是位于C:/windows/my.ini文件,mysql查找配置文件的顺序可以通过一下方法获得
/usr/sbin/mysqld --verbose --help | grep -A 1 ‘ Default options ‘
Tips:如果多个位置存储配置文件,则后面的会覆盖前面的
MySQL 配置文件常用参数
1、innodb_buffer_pool_size >= total MB
非常重要的一个参数,用于配置innodb的缓冲池,如果数据库中只有innodb表,则推荐配置量为总内存的75%
2、innodb_buffer_pool__instances
MySQL5.5中新增加参数,可以控制缓冲池的个数,默认情况下只有一个缓冲池。
3、innodb_log_buffer_size
innodb log缓冲的大小,由于日志最长每秒钟就会刷新所以一般不用太大。
4、innodb_flush_log_at_trx_commit
关键参数,对innodb的IO效率影响很大。默认值为1,可取0,1,2三个值,一般建议为2,但如果数据安全性要求比较高则使用默认值1.
5、innodb_read_io_threads innodb_write_io_threads
以上两个参数决定了Innodb读写的IO进程数,默认为4.
6、innodb_file_per_table
关键参数,控制innodb每一个表使用独立的表空间,默认为off,也就是所有表都会建立在共享表空间中。
7、innodb_stats_on_metadata
决定了mysql在什么情况下会刷新innodb表的统计信息。
我们也可以使用第三方工具类配置 MySQL 的配置文件:Percon Configuration Wizard:https://tools.percona.com/wizard
进入网站后需要回答一些问题,选择合适你的 MySQL 版本以及版本信息,然后注册登录即可。
如何选择cpu?
磁盘IO优化
常用RAID级别简介
SNA和NAT是否适合数据库?
参考文章:
标签:sof 自己 决定 localhost 垂直 desc red 排序 操作符
原文地址:https://www.cnblogs.com/midworld/p/11380231.html