标签:div master rac file object size 一个 rri gty
准备数据:
Michael,3000
Andy,4500
Justin,3500
Betral,4000
一、定义自定义无类型聚合函数
想要自定义无类型聚合函数,那必须得继承org.spark.sql.expressions.UserDefinedAggregateFunction,然后重写父类得抽象变量和成员方法。
package com.cjs
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
object UDFMyAverage extends UserDefinedAggregateFunction{
//定义输入参数的数据类型
override def inputSchema: StructType = StructType(StructField("inputColumn", LongType)::Nil)
//定义缓冲器的数据结构类型,缓冲器用于计算,这里定义了两个数据变量:sum和count
override def bufferSchema: StructType = StructType(StructField("sum",LongType)::StructField("count",LongType)::Nil)
//聚合函数返回的数据类型
override def dataType: DataType = DoubleType
override def deterministic: Boolean = true
//初始化缓冲器
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//buffer本质上也是一个Row对象,所以也可以使用下标的方式获取它的元素
buffer(0) = 0L //这里第一个元素是上面定义的sum
buffer(1) = 0L //这里第二个元素是上面定义的sount
}
//update方法用于将输入数据跟缓冲器数据进行计算,这里是一个累加的作用
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
//buffer1是主缓冲器,储存的是目前各个节点的部分计算结果;buffer2是分布式中执行任务的各个节点的“主”缓冲器;
// merge方法作用是将各个节点的计算结果做一个聚合,其实可以理解为分布式的update的方法,buffer2相当于input:Row
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
//计算最终结果
override def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble/buffer.getLong(1)
}
}
二、使用自定义无类型聚合函数
package com.cjs
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
object TestMyAverage {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf()
.set("spark.some.config.option","some-value")
.set("spark.sql.warehouse.dir","file:///e:/tmp/spark-warehouse")
val ss = SparkSession
.builder()
.config(conf)
.appName("test-myAverage")
.master("local[2]")
.getOrCreate()
import ss.implicits._
val sc = ss.sparkContext
val schemaString = "name,salary"
val fileds = schemaString.split(",").map(filedName => StructField(filedName,StringType, nullable = true))
val schemaStruct = StructType(fileds)
val path = "E:\\IntelliJ Idea\\sparkSql_practice\\src\\main\\scala\\com\\cjs\\employee.txt"
val empRDD = sc.textFile(path).map(_.split(",")).map(row=>Row(row(0),row(1)))
val empDF = ss.createDataFrame(empRDD,schemaStruct)
empDF.createOrReplaceTempView("emp")
// ss.sql("select name, salary from emp limit 5").show()
//想要在spark sql里使用无类型自定义聚合函数,那么就要先注册给自定义函数
ss.udf.register("myAverage",UDFMyAverage)
// empDF.show()
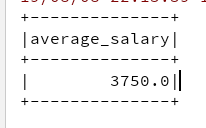
ss.sql("select myAverage(salary) as average_salary from emp").show()
}
}
输出结果:
标签:div master rac file object size 一个 rri gty
原文地址:https://www.cnblogs.com/SysoCjs/p/11466149.html