标签:准备 org inf 启动 term 问题 默认 file jdbc

Spark on Hive • Hive只是作为了存储的角色 • SparkSQL作为计算的角色 – Hive on Spark • Hive承担了一部分计算(解析SQL,优化SQL...)的和存储 • Spark作为了执行引擎的角色
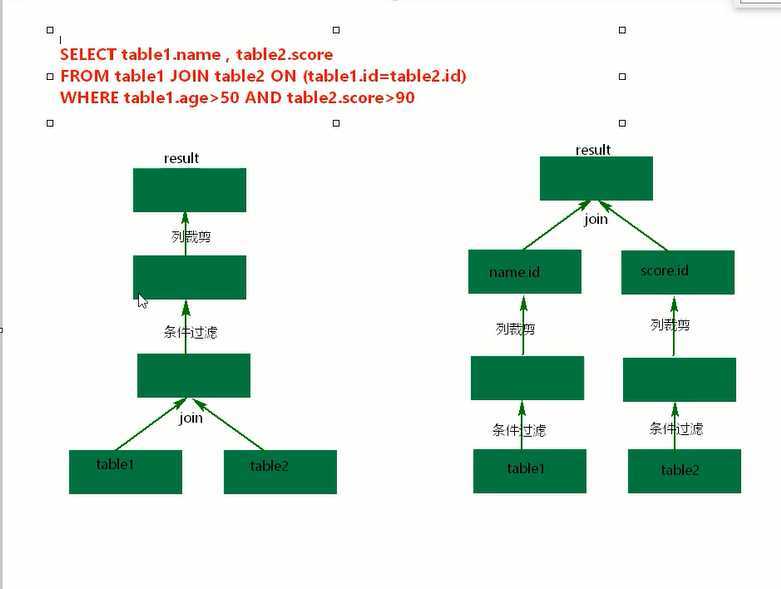
Predicate n. 谓语,述语 adj. 谓语的,述语的 v. 使……基于;断言;暗示 谓词下推 (条件往下压了,)
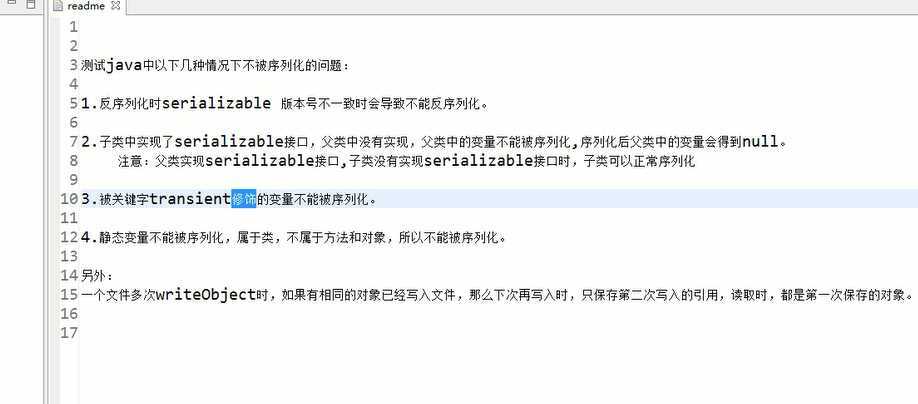
transient
英 [?trænzi?nt] 美 [?trænsi?nt; ?træn??nt; ?træn??nt]
adj. 短暂的;路过的
n. 瞬变现象;过往旅客;候鸟
HBase 与 ES整合
https://blog.csdn.net/weixin_42257250/article/details/88953967
spark1.6 官网文档
http://spark.apache.org/docs/1.6.0/
Spark on hive
spark配置使用hive
node1 spark client
node3 hive server node4 hive client;
[root@node1 conf]# pwd
/opt/sxt/spark-1.6.0/conf
## 复制node4的hive-site.xml 到node1 spark/conf下并且配置如下
[root@node1 conf]# cat hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
</configuration>
## 启动zk ,hdfs,yarn.
## 启动node3 的hive server
[root@node3 ~]# hive --service metastore & ## 后台启动
## 比较查询效果如下:
## 启动node4 hive 客户端
[root@node4 ~]# hive
hive> show tables;
hive> select coun(*) from psn;
## 启动node1 spark-shell
[root@node1 bin]# ./spark-shell --master spark://node2:7077,node3:7077
scala> val hiveContext = new HiveContext(sc)
<console>:27: error: not found: type HiveContext
val hiveContext = new HiveContext(sc)
^
scala> import org.apache.spark.sql.hive.HiveContext
scala> hiveContext.sql("show tables").show()
scala> hiveContext.sql("select count(*) from psn").show()
## 使用 node1 spark 提交文件保存到hive
node4 hive 中创建表
hive> create database spark;
## 准备用spark执行如下操作hive数据的jar包
package com.bjsxt.sparksql.dataframe;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.hive.HiveContext;
/**
* 如果读取hive中数据,要使用HiveContext
* HiveContext.sql(sql)可以操作hive表,还可以操作虚拟的表
*
*/
public class CreateDFFromHive {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("hive");
JavaSparkContext sc = new JavaSparkContext(conf);
//HiveContext是SQLContext的子类。
HiveContext hiveContext = new HiveContext(sc);
hiveContext.sql("USE spark");
hiveContext.sql("DROP TABLE IF EXISTS student_infos");
//在hive中创建student_infos表
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING,age INT) row format delimited fields terminated by ‘\t‘ ");
hiveContext.sql("load data local inpath ‘/root/test/student_infos‘ into table student_infos");
hiveContext.sql("DROP TABLE IF EXISTS student_scores");
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_scores (name STRING, score INT) row format delimited fields terminated by ‘\t‘");
hiveContext.sql("LOAD DATA "
+ "LOCAL INPATH ‘/root/test/student_scores‘"
+ "INTO TABLE student_scores");
/**
* 查询表生成DataFrame
*/
// DataFrame df = hiveContext.table("student_infos");//第二种读取Hive表加载DF方式
DataFrame goodStudentsDF = hiveContext.sql("SELECT si.name, si.age, ss.score "
+ "FROM student_infos si "
+ "JOIN student_scores ss "
+ "ON si.name=ss.name "
+ "WHERE ss.score>=80");
goodStudentsDF.registerTempTable("goodstudent");
DataFrame result = hiveContext.sql("select * from goodstudent");
result.show();
/**
* 将结果保存到hive表 good_student_infos
*/
hiveContext.sql("DROP TABLE IF EXISTS good_student_infos");
goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos");
DataFrame table = hiveContext.table("good_student_infos");
Row[] goodStudentRows = table.collect();
for(Row goodStudentRow : goodStudentRows) {
System.out.println(goodStudentRow);
}
sc.stop();
}
}
如上代码打包为 Test.jar 上传到spark lib/下
上传文件student_infos student_scores 到node1 /root/test下
student_infos
zhangsan 18
lisi 19
wangwu 20
student_scores
zhangsan 100
lisi 200
wangwu 300
## 执行spark导入
./spark-submit --master spark://node2:7077,node3:7077 ../lib/Test.jar
## 查看到数据日志。
## 在node4 hive中查看表内容
hive> use spark;
hive> select * from good_student_infos;
zhangsan 18 100
lisi 19 200
wangwu 20 300
Time taken: 0.113 seconds, Fetched: 3 row(s)
sparksql/json
{"name":"zhangsan","age":20}
{"name":"lisi"}
{"name":"wangwu","age":18}
{"name":"wangwu","age":18}
sparksql/person.txt
1,zhangsan,18
2,lisi,19
3,wangwu,20
package com.bjsxt.sparksql.dataframe;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
/**
* 读取json格式的文件创建DataFrame
*
* 注意 :json文件中不能嵌套json格式的内容
*
* 1.读取json格式两种方式
* 2.df.show默认显示前20行,使用df.show(行数)显示多行
* 3.df.javaRDD/(scala df.rdd) 将DataFrame转换成RDD
* 4.df.printSchema()显示DataFrame中的Schema信息
* 5.dataFram自带的API 操作DataFrame ,用的少
* 6.想使用sql查询,首先要将DataFrame注册成临时表:df.registerTempTable("jtable"),再使用sql,怎么使用sql?sqlContext.sql("sql语句")
* 7.不能读取嵌套的json文件
* 8.df加载过来之后将列按照ascii排序了
* @author root
*
*/
public class CreateDFFromJosonFile {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("jsonfile");
SparkContext sc = new SparkContext(conf);
//创建sqlContext
SQLContext sqlContext = new SQLContext(sc);
/**
* DataFrame的底层是一个一个的RDD RDD的泛型是Row类型。
* 以下两种方式都可以读取json格式的文件
*/
DataFrame df = sqlContext.read().format("json").load("./sparksql/json");
// DataFrame df2 = sqlContext.read().json("sparksql/json");
// df2.show();
/**
* 显示 DataFrame中的内容,默认显示前20行。如果现实多行要指定多少行show(行数)
* 注意:当有多个列时,显示的列先后顺序是按列的ascii码先后显示。
*/
df.show(100);
/**
* DataFrame转换成RDD
*/
// JavaRDD<Row> javaRDD = df.javaRDD();
/**
* 树形的形式显示schema信息
*/
// df.printSchema();
/**
* dataFram自带的API 操作DataFrame
*/
//select name from table
// df.select("name").show();
//select name ,age+10 as addage from table
// df.select(df.col("name"),df.col("age").plus(10).alias("addage")).show();
//select name ,age from table where age>19
// df.select(df.col("name"),df.col("age")).where(df.col("age").gt(19)).show();
//select age,count(*) from table group by age
// df.groupBy(df.col("age")).count().show();
/**
* 将DataFrame注册成临时的一张表,这张表相当于临时注册到内存中,是逻辑上的表,不会雾化到磁盘
*/
// df.registerTempTable("jtable");
// DataFrame sql = sqlContext.sql("select age,count(*) as gg from jtable group by age");
// sql.show();
// DataFrame sql2 = sqlContext.sql("select name,age from jtable");
// sql2.show();
sc.stop();
}
}
package com.bjsxt.sparksql.dataframe;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
/**
* 读取json格式的RDD创建DF
* @author root
*
*/
public class CreateDFFromJsonRDD {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("jsonRDD");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList(
"{‘name‘:‘zhangsan‘,‘age‘:\"18\"}",
"{\"name\":\"lisi\",\"age\":\"19\"}",
"{\"name\":\"wangwu\",\"age\":\"20\"}"
));
JavaRDD<String> scoreRDD = sc.parallelize(Arrays.asList(
"{\"name\":\"zhangsan\",\"score\":\"100\"}",
"{\"name\":\"lisi\",\"score\":\"200\"}",
"{\"name\":\"wangwu\",\"score\":\"300\"}"
));
DataFrame namedf = sqlContext.read().json(nameRDD);
namedf.show();
DataFrame scoredf = sqlContext.read().json(scoreRDD);
scoredf.show();
//SELECT t1.name,t1.age,t2.score from t1, t2 where t1.name = t2.name
//daframe原生api使用
// namedf.join(scoredf, namedf.col("name").$eq$eq$eq(scoredf.col("name")))
// .select(namedf.col("name"),namedf.col("age"),scoredf.col("score")).show();
//注册成临时表使用
namedf.registerTempTable("name");
scoredf.registerTempTable("score");
/**
* 如果自己写的sql查询得到的DataFrame结果中的列会按照 查询的字段顺序返回
*/
DataFrame result =
sqlContext.sql("select name.name,name.age,score.score "
+ "from name join score "
+ "on name.name = score.name");
result.show();
sc.stop();
}
}
package com.bjsxt.sparksql.dataframe;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.DataFrameReader;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SaveMode;
public class CreateDFFromMysql {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("mysql");
/**
* 配置join或者聚合操作shuffle数据时分区的数量
*/
conf.set("spark.sql.shuffle.partitions", "1"); // 默认200个分区
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
/**
* 第一种方式读取MySql数据库表,加载为DataFrame
*/
Map<String, String> options = new HashMap<String,String>();
options.put("url", "jdbc:mysql://192.168.112.101:3306/spark");
options.put("driver", "com.mysql.jdbc.Driver");
options.put("user", "root");
options.put("password", "123456");
options.put("dbtable", "person");
DataFrame person = sqlContext.read().format("jdbc").options(options).load();
person.show();
person.registerTempTable("person1");
options.put("dbtable", "score");
DataFrame score = sqlContext.read().format("jdbc").options(options).load();
score.registerTempTable("score1");
score.show();
/**
* 第二种方式读取MySql数据表加载为DataFrame
*/
// DataFrameReader reader = sqlContext.read().format("jdbc");
// reader.option("url", "jdbc:mysql://192.168.112.101:3306/spark");
// reader.option("driver", "com.mysql.jdbc.Driver");
// reader.option("user", "root");
// reader.option("password", "123456");
// reader.option("dbtable", "score");
// DataFrame score = reader.load();
// score.show();
// score.registerTempTable("score1");
DataFrame result =
sqlContext.sql("select person1.id,person1.name,person1.age,score1.score "
+ "from person1,score1 "
+ "where person1.name = score1.name");
result.show();
/**
* 将DataFrame结果保存到Mysql中
*/
Properties properties = new Properties();
properties.setProperty("user", "root");
properties.setProperty("password", "123456");
/**
* SaveMode:
* Overwrite:覆盖
* Append:追加
* ErrorIfExists:如果存在就报错
* Ignore:如果存在就忽略
*
*/
result.write().mode(SaveMode.Overwrite).jdbc("jdbc:mysql://192.168.112.101:3306/spark", "result", properties);
System.out.println("----Finish----");
sc.stop();
}
}
// CreateDFFromParquet 生成Parquet压缩数据,在读取
package com.bjsxt.sparksql.dataframe;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SaveMode;
public class CreateDFFromParquet {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("parquet");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> jsonRDD = sc.textFile("sparksql/json");
DataFrame df = sqlContext.read().json(jsonRDD);
// sqlContext.read().format("json").load("./spark/json");
// df.show();
/**
* 将DataFrame保存成parquet文件,
* SaveMode指定存储文件时的保存模式:
* Overwrite:覆盖
* Append:追加
* ErrorIfExists:如果存在就报错
* Ignore:如果存在就忽略
* 保存成parquet文件有以下两种方式:
*/
df.write().mode(SaveMode.Overwrite).format("parquet").save("./sparksql/parquet");
// df.write().mode(SaveMode.Ignore).parquet("./sparksql/parquet");
/**
* 加载parquet文件成DataFrame
* 加载parquet文件有以下两种方式:
*/
DataFrame load = sqlContext.read().format("parquet").load("./sparksql/parquet");
// load = sqlContext.read().parquet("./sparksql/parquet");
load.show();
sc.stop();
}
}
package com.bjsxt.sparksql.dataframe;
import java.io.Serializable;
public class Person implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1L;
private String id ;
private String name;
private Integer age;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", age=" + age + "]";
}
}
package com.bjsxt.sparksql.dataframe;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
/**
* 通过反射的方式将非json格式的RDD转换成DataFrame
* 注意:这种方式不推荐使用
* @author root
*
*/
public class CreateDFFromRDDWithReflect {
public static void main(String[] args) {
/**
* 注意:
* 1.自定义类要实现序列化接口
* 2.自定义类访问级别必须是Public
* 3.RDD转成DataFrame会把自定义类中字段的名称按assci码排序
*/
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("RDD");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lineRDD = sc.textFile("sparksql/person.txt");
// final Person p = new Person(); // 需要序列化 implements Serializable
JavaRDD<Person> personRDD = lineRDD.map(new Function<String, Person>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Person call(String line) throws Exception {
final Person p = new Person();
p.setId(line.split(",")[0]);
p.setName(line.split(",")[1]);
p.setAge(Integer.valueOf(line.split(",")[2]));
return p;
}
});
/**
* 传入进去Person.class的时候,sqlContext是通过反射的方式创建DataFrame
* 在底层通过反射的方式获得Person的所有field,结合RDD本身,就生成了DataFrame
*/
DataFrame df = sqlContext.createDataFrame(personRDD, Person.class);
df.show();
df.printSchema();
df.registerTempTable("person");
DataFrame sql = sqlContext.sql("select name,id,age from person where id = 2");
sql.show();
/**
* 将DataFrame转成JavaRDD
* 注意:
* 1.可以使用row.getInt(0),row.getString(1)...通过下标获取返回Row类型的数据,但是要注意列顺序问题---不常用
* 2.可以使用row.getAs("列名")来获取对应的列值。
*
*/
JavaRDD<Row> javaRDD = df.javaRDD();
JavaRDD<Person> map = javaRDD.map(new Function<Row, Person>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Person call(Row row) throws Exception {
Person p = new Person();
// p.setId(row.getString(0));
// p.setName(row.getString(1));
// p.setAge(row.getInt(2));
//
// p.setId(row.getString(1));
// p.setName(row.getString(2));
// p.setAge(row.getInt(0));
//
p.setId(row.getAs("id")+"");
p.setName((String)row.getAs("name"));
p.setAge((Integer)row.getAs("age"));
return p;
}
});
map.foreach(new VoidFunction<Person>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(Person person) throws Exception {
System.out.println(person);
}
});
sc.stop();
}
}
/**
*
*/
package com.bjsxt.sparksql.dataframe;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
/**
* 动态创建Schema将非json格式RDD转换成DataFrame
* @author root
*
*/
public class CreateDFFromRDDWithStruct {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("rddStruct");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lineRDD = sc.textFile("./sparksql/person.txt");
/**
* 转换成Row类型的RDD
*/
JavaRDD<Row> rowRDD = lineRDD.map(new Function<String, Row>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Row call(String s) throws Exception {
return RowFactory.create(
s.split(",")[0],
s.split(",")[1],
Integer.valueOf(s.split(",")[2]
));
}
});
/**
* 动态构建DataFrame中的元数据,一般来说这里的字段可以来源自字符串,也可以来源于外部数据库
*/
List<StructField> asList =Arrays.asList(
DataTypes.createStructField("id", DataTypes.StringType, true),
DataTypes.createStructField("name", DataTypes.StringType, true),
DataTypes.createStructField("age", DataTypes.IntegerType, true)
);
StructType schema = DataTypes.createStructType(asList);
DataFrame df = sqlContext.createDataFrame(rowRDD, schema);
df.show();
// JavaRDD<Row> javaRDD = df.javaRDD();
// javaRDD.foreach(new VoidFunction<Row>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Row row) throws Exception {
// System.out.println(row.getString(0));
// }
// });
sc.stop();
}
}
package com.bjsxt.sparksql.dataframe;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.rdd.RDD;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import scala.Function1;
import scala.runtime.BoxedUnit;
public class DataFrameTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("RDD");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lineRDD = sc.textFile("sparksql/person.txt");
JavaRDD<Person> personRDD = lineRDD.map(new Function<String, Person>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Person call(String line) throws Exception {
Person p = new Person();
p.setId(line.split(",")[0]);
p.setName(line.split(",")[1]);
p.setAge(Integer.valueOf(line.split(",")[2]));
return p;
}
});
/**
* 传入进去Person.class的时候,sqlContext是通过反射的方式创建DataFrame
* 在底层通过反射的方式获得Person的所有field,结合RDD本身,就生成了DataFrame
*/
DataFrame df = sqlContext.createDataFrame(personRDD, Person.class);
df.show();
df.printSchema();
df.registerTempTable("person");
DataFrame resultDataFrame = sqlContext.sql("select name,age,id from person where id = 2");
JavaRDD<Row> javaRDD = resultDataFrame.javaRDD();
/**
* 自己写的sql语句查询出来的DataFrame显示表的时候会安装查询的字段来显示,字段不会按照Ascii码来排序
*/
javaRDD.foreach(new VoidFunction<Row>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(Row row) throws Exception {
System.out.println("name = "+ row.getAs(0));
System.out.println("name = "+ row.getAs("name"));
System.out.println("name = "+ row.getString(0));
System.out.println("age = "+ row.getAs(1));
System.out.println("age = "+ row.getAs("age"));
System.out.println("age = "+ row.getInt(1));
System.out.println("id = "+ row.getAs(2));
System.out.println("id = "+ row.getAs("id"));
System.out.println("id = "+ row.getString(2));
}
});
// /**
// * 将DataFrame转成JavaRDD
// * 注意:
// * 1.可以使用row.getInt(0),row.getString(1)...通过下标获取返回Row类型的数据,但是要注意列顺序问题---不常用
// * 2.可以使用row.getAs("列名")来获取对应的列值。
// *
// */
// JavaRDD<Row> javaRDD = df.javaRDD();
// JavaRDD<Person> map = javaRDD.map(new Function<Row, Person>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Person call(Row row) throws Exception {
// Person p = new Person();
//
//
//// p.setId(row.getString(0));
//// p.setName(row.getString(1));
//// p.setAge(row.getInt(2));
//
//// p.setId(row.getString(1));
//// p.setName(row.getString(2));
//// p.setAge(row.getInt(0));
//
// p.setId((String)row.getAs("id"));
// p.setName((String)row.getAs("name"));
// p.setAge((Integer)row.getAs("age"));
// return p;
// }
// });
// map.foreach(new VoidFunction<Person>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Person t) throws Exception {
// System.out.println(t);
// }
// });
sc.stop();
}
}
您好
标签:准备 org inf 启动 term 问题 默认 file jdbc
原文地址:https://www.cnblogs.com/xhzd/p/11588565.html