标签:状态 cbo tput 模型 hashset viso exec 一个 编程
JStorm从设计的角度,就是一个典型的调度系统,简单集群的架构如下图所示,其中Nimbus可增加一个备节点,多个Supervisor节点组成任务执行集群。
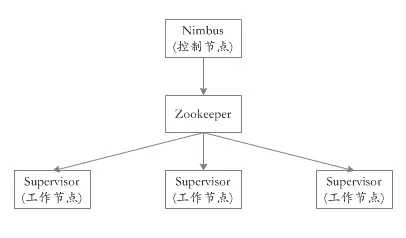
Nimbus是作为整个集群的调度器角色,负责分发topology代码、分配任务,监控集群运行状态等,其主要通过ZK与supervisor交互。可以和Supervisor运行在同一物理机上,JStorm中Nimbus可采用主从备份,支持热切。
Supervisor 是集群中任务的执行者,负责运行具体任务以及关闭任务。其从ZK中监听nimbus的指令,然后接收分发代码和任务并执行、监控反馈任务执行情况。
ZK是整个系统中的协调者,Nimbus的任务调度通过ZK下发至Supervisor来执行。
Topology是一个可以在JStorm中运行的任务的抽象表达,在JStorm的topology中,有两种组件:spout和bolt。下面是一张比较经典的Topology结构图。每一个topology,既可以有多个spout,代表同时从多个数据源接收消息,也可以多个bolt,来执行不同的业务逻辑。一个topology会一直运行直到你手动kill掉,JStorm自动重新分配执行失败的任务。
在JStorm中有对于流stream的抽象,流是一个不间断的无界的连续tuple,注意JStorm在建模事件流时,把流中的事件抽象为tuple即元组。
我们可以认为spout就是一个一个的水龙头,并且每个水龙头里流出的水是不同的tuple,我们想拿到哪种水tuple就拧开哪个水龙头,然后使用管道将水龙头的水tuple导向到一个水处理器(bolt),水处理器bolt处理后再使用管道导向另一个处理器或者存入容器中。
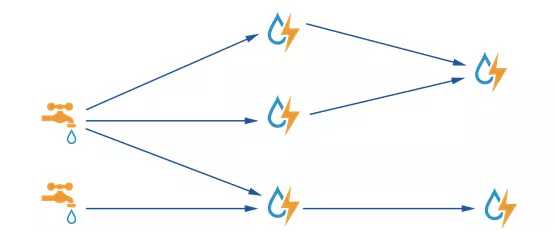
JStorm将上图抽象为Topology即拓扑,拓扑结构是有向无环的,拓扑是Jstorm中最高层次的一个抽象概念,它可以被提交到Jstorm集群执行,一个拓扑就是一个数据流转换图,图中每个节点是一个spout或者bolt,图中的边表示bolt订阅了哪些流,当spout或者bolt发送元组到流时,它就发送元组到每个订阅了该流的bolt。
JStorm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头抽象为spout,spout可能是连接消息中间件(如MetaQ, Kafka, TBNotify等),并不断发出消息,也可能是从某个队列中不断读取队列元素并装配为tuple发射。
JStorm框架对spout组件定义了一个主要方法:nextTuple,顾名思义,就是获取下一条消息。执行时,可以理解成JStorm框架会不停地调这个接口,以从数据源拉取数据并往bolt发送数据。
Tuple是一次消息传递的基本单元,tuple里的每个字段一个名字,并且不同tuple的对应字段的类型必须一样。tuple的字段类型可以是: integer, long, short, byte, string, double, float, boolean和byte array。还可以自定义类型,只要实现对应的序列化器。
JStorm中与spout相关的接口主要是ISpout和IRichSpout、IBatchSpout,后两接口实现了对ISpout接口的上层封装。
ISpout接口主要方法:
open:在worker中初始化该ISpout时调用,一般用来设置一些属性:比如从spring容器中获取对应的Bean。
close:和open相对应(在要关闭的时候调用)。
activate:从非活动状态变为活动状态时调用。
deactivate:和activate相对应(从活动状态变为非活动状态时调用)。
nextTuple:JStorm希望在每次调用该方法的时候,它会通过collector.emit发射一个tuple。
ack:jstorm发现msgId对应的tuple被成功地完整消费会调用该方法。
fail:和ack相对应(jstorm发现某个tuple在某个环节失败了)。和ack一起保证tuple一定被处理。
JStorm将tuple的中间处理过程抽象为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout(管口)再将spout中流出的tuple导向特定的bolt,然后bolt对导入的流做处理后再导向其他bolt或者目的地。
bolt代表处理逻辑,bolt收到消息之后,对消息做处理(即执行用户的业务逻辑),处理完以后,既可以将处理后的消息继续发送到下游的bolt,这样会形成一个处理流水线(不过更复杂的情况应该是个有向图);也可以直接结束。
bolt组件主要方法:execute,这个接口就是用户用来处理业务逻辑的地方。
通常一个流水线的最后一个bolt,会做一些数据的存储工作,比如将实时计算出来的数据写入DB、HBase等,以供前台业务进行查询和展现。Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
在保证不丢消息的场景中,在bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知JStorm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。 一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知JStorm自己已经处理过这个tuple了。JStorm提供了一个IBasicBolt会自动调用ack。
JStorm中与Bolt相关的接口主要是IBolt,IRichBolt,IBasicBolt和IBatchBolt,后面接口实现了对IBolt接口的上层封装。
IBolt接口的主要方法:
prepare:在worker中初始化该IBolt时调用,一般用来设置一些属性:比如从spring容器中获取对应的Bean。
cleanup:和prepare相对应(在显示关闭topology的时候调用)
execute:处理jstorm发送过来的tuple。
JStorm将流中数据抽象为tuple,一个tuple就是一个值列表value list,list中的每个value都有一个name,tuple可以由任意类型组合而成,因为storm是分布式的,所以它需要知道在task间如何序列化和反序列化数据的。storm使用Kryo进行序列化,Kryo是java开发中一个快速灵活序列器。默认情况下,storm可以序列化基础类型,比如字符串,字节,数组,ArrayList, HashMap, HashSet和 Clojure 集合类型,如果需要使用其他类型,需要自定义序列器。拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
在spout和Bolt组件中,使用declareOutputFields方法定义发射出的tuple的字段名。
本文主要讲述了JStorm中集群的架构以及Topology编程模型方面的概念知识。
https://www.jianshu.com/p/36394f897d36
https://yq.aliyun.com/articles/709401
标签:状态 cbo tput 模型 hashset viso exec 一个 编程
原文地址:https://www.cnblogs.com/zhangww/p/11665546.html