标签:带来 sha 种类型 file 特殊 name 属性 版本号 磁盘
ELF格式文档详解
一,ELF格式综述
ELF(Executable and Linkable Format)是Linux下的一种格式标准,Linux中的ELF格式文件一共有四种:
●可重定位文件(Relocatable File):这类文件包含了代码和数据,可被用来链接成可执行文件或者共享目录文件,扩展名为.o
●可执行文件(Executable File):这类文件包含了可以直接执行的程序,一般没有扩展名
●共享目录文件(Shared Object File):这类文件包含了代码和数据,扩展名为.so。
共享目录文件一般可以在以下两种情况下使用:
①链接器可以使用这类文件,与其他的共享目录文件和可重定位文件进行链接,生成新的目标文件;
②动态链接器可以将几个这种共享目录文件与可执行文件结合,作为进程映像的一部分来运行。
●核心转储文件(Core Dump File):当进程意外终止时,系统可以将该进程的地址空间的内容以及终止时的一些其他信息转储在核心转储文件中。
一个ELF格式的文件一般包括四个部分:ELF头表(Head Table),程序头表(Program Head Table),节头表(Section Head Table),节(Section)。也就是说:ELF文件中有三个“表“,其他的都是一个一个叫做”节“的东西。
实际上一个ELF文件中我们最终要用的东西都是存在各个节里边的,三个表的存在都是为了让我们能够快速的找到我们需要用的节,然后从节里边读取我们需要的数据。那这三个表各自都有什么作用呢?
首先说ELF头表。在ELF文件中,只有ELF头表的位置是固定的,它一定在文件开头位置的,其他三个部分的位置都由ELF头表中的信息给出。我们一进到ELF文件中,立马就能看到ELF头表,所以ELF头表的作用就很显而易见了,它就是要告诉来客:我这个文件是ELF格式的,我能干啥(可执行文件,链接库还是可重定位文件),我需要用多少多少位的操作系统,你得用什么样的CPU架构来运行我,我是按什么字节序来存数据的等等。对了,你要找谁,我认识的人不多,我只认识俩哥们,他俩认识的人多,我给你喊他们去!
到这里ELF头表就可以告诉来客:程序头表在哪,节头表在哪,你要找谁去问他俩吧。
记住:我们的目的是找到最终的某一个节,现在我们知道“程序头表“和”节头表“在哪了,而他俩知道”节“们在那,于是我们就去问这俩头表。
”程序头表“说:”我知道他们宿舍都在哪,但是我不知道他们每个人住几号床。“
“节头表”说:“你找谁问我吧,我知道他们每个人住几号床。“
也就是说,程序头表只可以找到同类的节的聚集地,但是节头表可以细致的找到每一个节的位置。
那有节头表就够了嘛,能找到每一个节的位置不就行了,要程序头表有啥用?
这就跟ELF文件的两个阶段有关系了,其实节头表和程序头表分别是在不同阶段起作用的:链接时用到节头表,执行时用到程序头表。
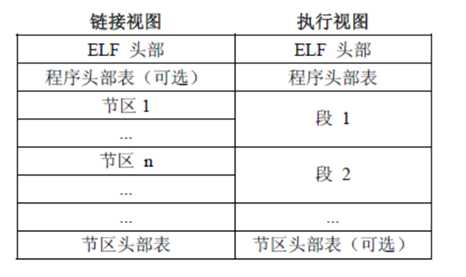
(Note:虽然这张图中程序头表和节头表的位置画在确定的位置,但是实际上除了ELF头表的位置固定以外 其他部分的位置都是可以变动的,具体位置要看ELF头表中给出的信息。)
在链接的时候,需要用到节头表,执行的时候,需要用到程序头表。
Linux中保存节的时候是以“页”为单位的(物理内存也同样是分页的,他们一一对应,一页一般是4096字节,也就是4k),不够一页的也要占用一页的空间,由于节的数量有很多,如果每个节都单独存的话,就会有很多不够一页而占了一页的情况发生,这样会浪费很多空间。
当我们站在操作系统装载可执行文件的角度看问题时,可以发现它实际上并不关心可执行文件各个节所包含的实际内容,操作系统只关心一些跟装载相关的问题,最主要的是节的权限(可读、可写、可执行)。在ELF格式文件中,权限的组合种类主要分为下面的这三种:
①可读可执行(如代码)
②可读可写(如数据)
③只读
所以有一个很好的解决办法就是把性质相同的节(Section)“捆绑”到一起变成一个“段(Segment)”,段在保存的时候按页为单位(一个段里有若干个”节“,具体个数不一定),段内的各个节是首尾相接依次排放好的,这样做可以明显减少页面内部的碎片,起到节省内存空间的作用。
Note:英文“Section”和“Segment”都可以翻译为“段”,但由于一般很少对“Segment”进行分析,所以有的书中就把“Section”称作“段”,而对于“Segment”就不做翻译,直接用英文进行描述。鉴于这篇文章对“Section“和”Segment“都有比较多的描述,所以按照网上的一些帖子的习惯,把”Section“翻译为”节“,而把”Segment“翻译为”段“。
举个例子:
假如现在有两个节,分别占4097字节和255字节,那么在保存他们两个节的时候就需要用三页。如果他们的权限是一样的,那我们就可以把这两个节捆绑到一块作为一个段来进行映射,这个段共占4352字节,这样就只需要用两页就足够了。这样就节省了一页,也就是4096字节的空间。当文件中有很多节的时候,这样做就能节省十分可观的内存空间了。
这时就不能再用节头表来记录这些内容的信息了,而需要用程序头表(Program Head Table)来记录这些段的信息。程序头表中列出了一系列段的信息,在创建进程映像的时候,有这些段的信息就足够了(相当于查宿舍的时候不用找到每一个人,找到宿舍就够了)。
所以我们拿到的不同的ELF格式文件中:
可执行文件一定有程序头表,但是不一定有节头表,因为可执行文件只需要进行执行操作,而执行时用到的是程序头表。
可重定位文件一定有节头表,但是不一定有程序头表,因为可重定位文件只需要进行链接操作,而链接时用到的是节头表。
二,ELF格式内部结构详细分析
(Note:ELF格式的定义在/usr/include目录下的“elf.h”头文件中。)
一.ELF文件头表
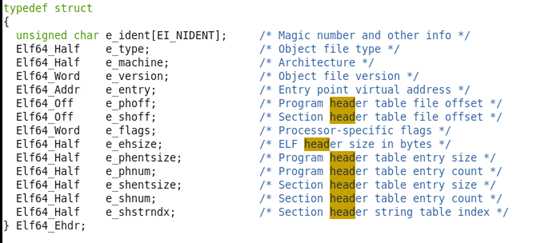
ELF头表是一个这样的结构体:
其中:
●E_ ident[EI_NIDENT]是一个数组,它有16个字节,这16个字节被分为好几个部分,分别代表不同的涵义:
⑴e_ ident[0]-e_ ident[3]:这四个字节被称为“魔数“(Magic),它们分别是“0x7F“,”E“,”L“,”F“的ASCII码,对所有ELF格式的文件来说,这四个字节是固定的,也就是说,只有当这四个字节是这些值的时候,才代表这个文件是ELF格式的文件。相当于ELF文件的身份证。
(2)e_ ident[4]:这个字节给出了这个ELF文件是多少位的:当取“0x1”时,代表这个ELF文件是32位的;当取”0x2”时,代表这个ELF文件是64位的。
(3)e_ ident[5]:这个字节给出了这个ELF文件使用的字节顺序:当取”0x1”时,代表小端序,当取”0x2”时,代表大端序。
(4)e_ ident[6]:这个字节给出了这个ELF文件头的版本,当前只有一个版本,所以这个字节目前只能取”0x1”
(5)e_ ident[7]到e_ ident[15]:这九个字节目前还没有实际意义,一般为0,也有的文件会用它们做一些特殊的标记。
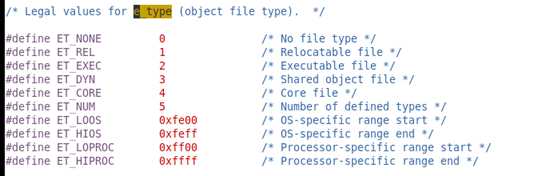
“ET_REL“代表此ELF文件为可重定位文件
”ET_EXEC“代表ELF文件为可执行文件
”ET_DYN“代表此ELF文件为动态链接库
ET_CORE”代表此ELF文件是核心转储文件
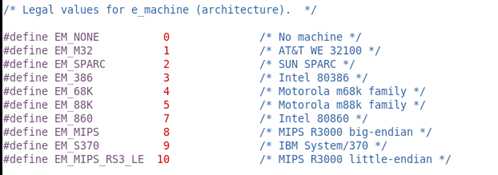
(上图只截取了一部分)
ELF 文件格式被设计成可以在多个平台下使用。这并不表示同一个ELF文件可以在不同的平台下使用,而是表示不同平台下的ELF文件都遵循同一套ELF标准。e_ machine 成员就表示该ELF文件的平台属性,比如3表示该ELF文件只能在Intel x86 机器下使用,这也是我们最常见的情况。
实例:
下面是读取了“/bin“目录下的“ls“文件的结果:
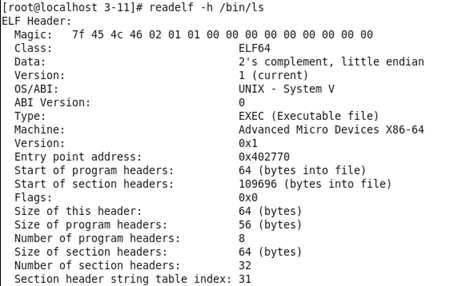
我们可以看到Magic(魔数)的前四位是“7f“,”E“,”L“,”F“的ASCII码,代表这个文件是ELF文件;第五位是”02“,代表这个ELF文件是64位的;第六位是”01“,代表这个ELF文件是小端序保存的(因为我生成这个文件时用的cpu是x86架构的);第七位是“01”,代表这个ELF文件的版本。(这些信息在下边的Class,Data和Version中也有体现)
OS/ABI给出了创建这个ELF文件的系统是UNIX-System V
Type给出了这个ELF文件是一个可执行文件
Machine给出了这个ELF文件需要的系统结构是X86-64位
Entry point address给出这个ELF文件在虚拟内存中的入口地址
Start of program headers给出了这个ELF文件的程序头表的偏移量
Strat of section headers给出了这个ELF文件的节头表的偏移量
Size of program header给出了这个ELF文件的程序头表的大小,以字节为单位
Number of program headers给出了这个ELF文件的程序头表中有几条信息(有几个段)
Size of section headers给出了这个ELF文件的节头表的大小,以字节为单位
Number of section headers给出了这个ELF文件的节头表中有几条信息(有几个节)
二.节头表
节头表是一个结构体数组(一个数组,这个数组的每个元素都是一个结构体),数组中每一个元素的结构体是这样的:

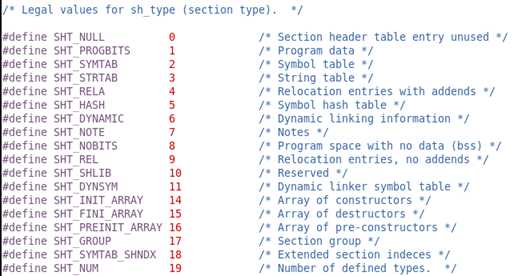
(1) SHT_NULL代表该节为空
(2) SHT_PROGBITS类型的节中具体存的是什么东西,需要程序给出具体的解释(保存程序,代码,数据的节都是这种类型)。
(3) SHT_SYMTAB类型的节是一个符号表,里边保存了一系列例如“int a;“语句中的”a”这样的符号。
(4) SHT_STRTAB类型的节是一个字符串表,其中保存了一系列的字符串
(5) SHT_RELA类型的节中保存了重定位信息
(6) SHT_HASH类型的节中保存了一个散列表,用于实现符号的快速访问
(7) SHT_DYNAMIC类型的节中保存了一个结构数组,该结构数组中包含了大量的动态链接相关信息,后面会着重分析
(8) SHT_NOTE类型的节中保存了一些提示性的信息。
(9) SHT_NOBITS类型的节在文件中没有内容,比如.bss节。
(10) SHT_REL类型的节保存了重定位信息
(11) SHT_DYNSYM类型的节保存了动态链接的符号表
●sh_ flags:给出了节在虚拟进程空间的属性,如是否可写,是否可执行等等:

●sh_ addr:这个成员给出了节的虚拟地址。如果该节可以被加载,则这个数值代表该节被加载后在进程地址空间中的虚拟地址;否则为0。
●sh_ offset:这个成员给出了节在ELF文件中的偏移量。如果该节存在于ELF文件中,则这个数值代表节在ELF文件中的偏移量;否则无意义。比如.bss节的sh_ offset成员就没有意义。
●sh_ link 和sh_ info:这两个成员是节的链接信息,如果节的类型是与链接相关的(不论是动态链接还是静态链接),比如重定位表,符号表等节,那么这两个成员的意义如下图:(对于其他节,这两个成员没有实际意义)

实例:/bin目录下的ls文件的节头信息太长了,我只截取了一部分。
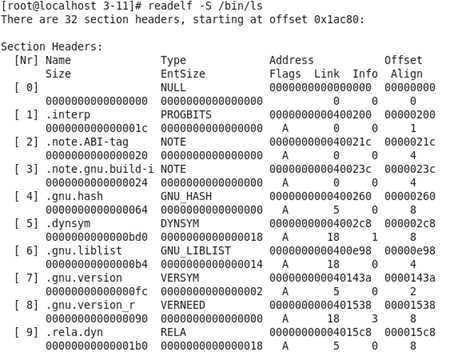
[Nr]一列给出了对应节在节头表数组中的下标;后面每一列都是按上面所讲的给出对应的信息。
三.程序头表
程序头表也一个结构体数组,数组中的每一个元素内的结构体是这样的:

其中:
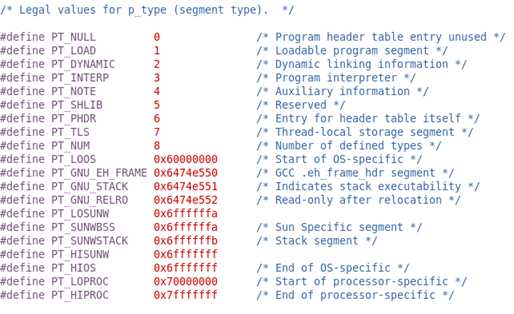
⑴PT_NULL代表空段
(2)PT_LOAD代表这是一个可装载段
(3)PT_DYNAMIC代表这个段中存的是用于动态链接的信息
(4)PT_INTERP代表了这个段中存的是表明链接器绝对路径的字符串
(5)PT_NOTE代表了这个段中存的是专有的编译器信息
(1)PF_R代表可读
(2)PF_W代表可写
(3)PF_X代表可执行
实例:
下面读取“bin”录下的“ls”文件的程序头表:
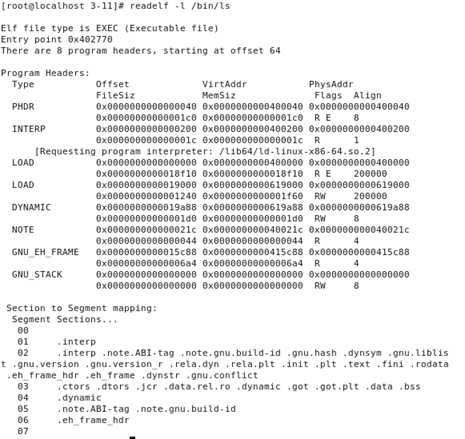
可以看到各个段的偏移量,虚拟地址,段大小,访问权限等信息。在最下面也给出了各个段中包含的节都是哪些,也验证了上面说的“段就是若干个节捆绑在一起形成的”这句话。
其中在动态链接的时候用到的是两个类型为“LOAD”的段,这两个“LOAD”段一个是可读可执行的,另一个是可读可写的,只有他们两个段是要被映射到内存空间的,而其他的段都是在装载时起到辅助作用的段。
四.节
节是ELF文件中有实际内容的东西,前面讲的三个头表都是为了能够快速找到需要的节的一些工具。所以说,节才是我们最终想要读取的。
ELF文件中有很多的节,他们分别保存着不同的信息,比如有的节保存了代码,有的节保存了数据,有的节保存了调试信息等等。这样分开存的好处就是可以分别给他们不同的权限,像代码就是可读可执行的,而数据则是可读可写的,分开存可以防止在不经意之间将代码改掉带来预期之外的错误。
要判断一个节里边具体保存的是什么类型的信息,可以通过节头表来了解到。下面介绍几个常用的节:
●.interp:这个节中保存的是一个字符串,这个字符串描述的是动态链接器的绝对路径(在Linux中一般为/lib64/ld-linux.so.2)。
●.bss:这个节中保存了程序中没有初始化的数据,这个节在程序运行时,在内存中会被清零,该节本身不占用磁盘空间。
●.data和.data1:这两个节中保存的是程序中初始化的数据,主要是已初始化的全局变量和静态变量。
●.rodata:这个节中存的是只读的数据,比如静态变量,字符串常量以及“count“修饰的变量。
●.comment:这个节中保存了注释信息。
●.text:这个节中保存了程序的可执行代码。
●.debug和.stab以及.stabstr:这几个节中保存的是调试信息,对程序的调试有很大帮助。它们占的空间可能比程序本身还要多,一般在程序交付的时候可以用strip命令去掉文件中的debug信息以精简文件大小,这一个动作可能让程序的体积减少一半以上,但是这样也就令这个程序失去了调试的便利性。
●.line:这个节中保存了调试时用的行号信息。
●.dynstr:这个节中保存的是动态链接时的字符串表,主要是动态链接符号的符号名
●.symtab:这个节中是一个符号表,保存了保存变量名,函数名等
●.dynsym:这个节中保存的是动态链接时的符号表,主要用于保存动态链接时的符号表。
Note:.dynsym其实是.symtab的一个子集,.dynsym相当于是从.symtab中取出了与动态链接有关的符号组成的一个表。
●.hash:这个节中保存的是符号表的哈希表,用来加快符号查找速度。
●.init:这个节中保存了程序执行前的初始化代码,这些代码早于main函数被执行。
●.fini:这个节中保存了程序退出时执行的代码,这些代码晚于main函数被执行。
●.shstrtab:这个节中保存了一个字符串,里边全是节的名称。
●.dynamic:这个节中保存的是一个结构体数组,这个数组每一个元素都是一个结构体,其中保存的是一些与动态链接有关的信息,比如:依赖于哪些共享对象,动态链接符号表的位置,动态链接重定位表的位置,共享对象初始化代码的地址等。
结构体如下:(定义在/usr/include目录下的elf.h头文件中)

其中d_ tag是一个标志,它取不同的值的时候,下面的共用体所存内容有不同含义。它的取值有以下几种可能:
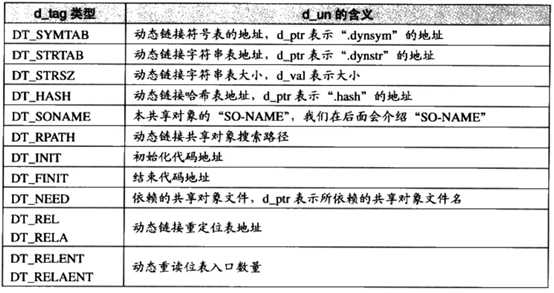
从上面这个表可以看出来“.dynamic”节中保存的全都是有关动态链接的各种细节信息,因此,这个节在动态链接的过程中起到了很重要的作用,这个节相当于有关动态链接的一个“头表”。
●.rel.text和.rel.data:这是一些重定位表。
链接器在处理目标文件的时候,需要对目标文件中的某些部位进行重定位,也就是代码和数据节中对绝对地址的引用的位置。这些重定位的信息都是保存在一系列重定位表中,对于每一个需要重定位的代码节或者数据节,都有一个对应的重定位表。比如这个“.rel.text”就是一个代码相关的重定位表。比如在其他库中定义的函数或者变量,在本文件中引用到的了,编译器在编译的时候不知道他们的真实地址,所以暂时用一个假的地址(记作A)代替,同时生成一个重定位条目(包含P和S,后面会讲到)放到“.rel.text”节中,等到以后链接的时候由链接器根据重定位表中的信息计算出他们的真实地址。(每一个需要被重定位的地方叫做一个“重定位入口”。)
“,rel,”开头的节中有一个这样的结构体:

其中:
1, r_ offset:代表重定位入口的偏移量,对于可重定位文件来说,这个值是该重定位入口所要修正的位置的第一个字节相对于要被重定位的节开始处的偏移。而对于可执行文件和共享对象来说,这个值是该重定位入口要修正的位置的第一个字节的虚拟地址。
2, r_info:重定位入口的类型和符号,在32位系统中,低8位表示重定位入口的类型,而高24位表示重定位入口的符号在符号表中的下标。
重定位类型一般有两种:绝对寻址和相对寻址。这两种类型分别有不同的重定位修正方式,如下图。

Note:S:目标文件符号表中对应的地址,而不是.o文件;
对一个可重定位文件使用 “objdump -r 文件名“ 命令可以查看文件中的重定位表以及重定位入口(下面只截取了一部分)
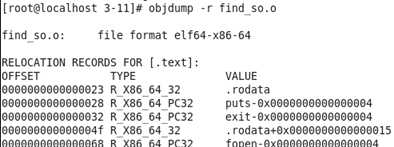
Note:还有一种重定位表的名称是“.rela.xxx”这样的,这种重定位表称为“需要添加常数的重定位表”,它的结构体会多一个成员:“r_addend”(加数),计算重定位时,根据重定位类型,对该值做不同处理。
标签:带来 sha 种类型 file 特殊 name 属性 版本号 磁盘
原文地址:https://www.cnblogs.com/qscfyuk/p/11697816.html