标签:data ext 有用 choice scheduler 遇到 set ova 新浪
很多情况下,页面的某些信息需要登录才可以查看。
这里的核心是获取登陆之后的 Cookies 。话不多说,操练起来。
1. 模拟登录并爬取GitHub
1.1 环境准备
1.2 分析登录过程
打开Github的登录页面,https://github.com/login.输入用户名和密码,打开开发者工具,勾选preserve log,这表示显示持续日志。
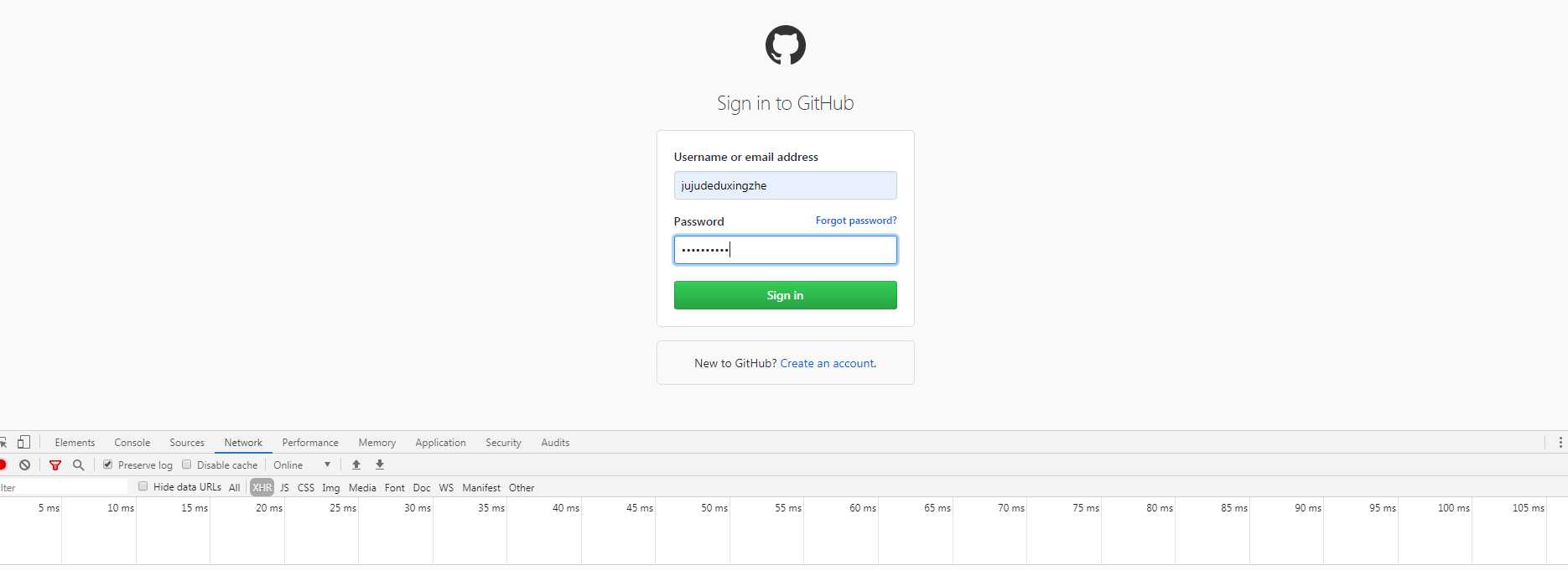
点击登录按钮,可以看到各个请求过程。
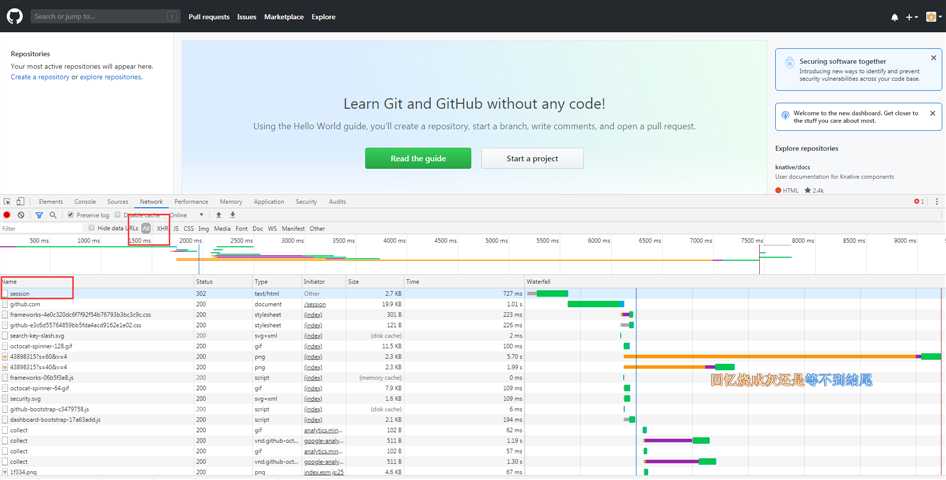
点击第一个请求,进入详细界面:
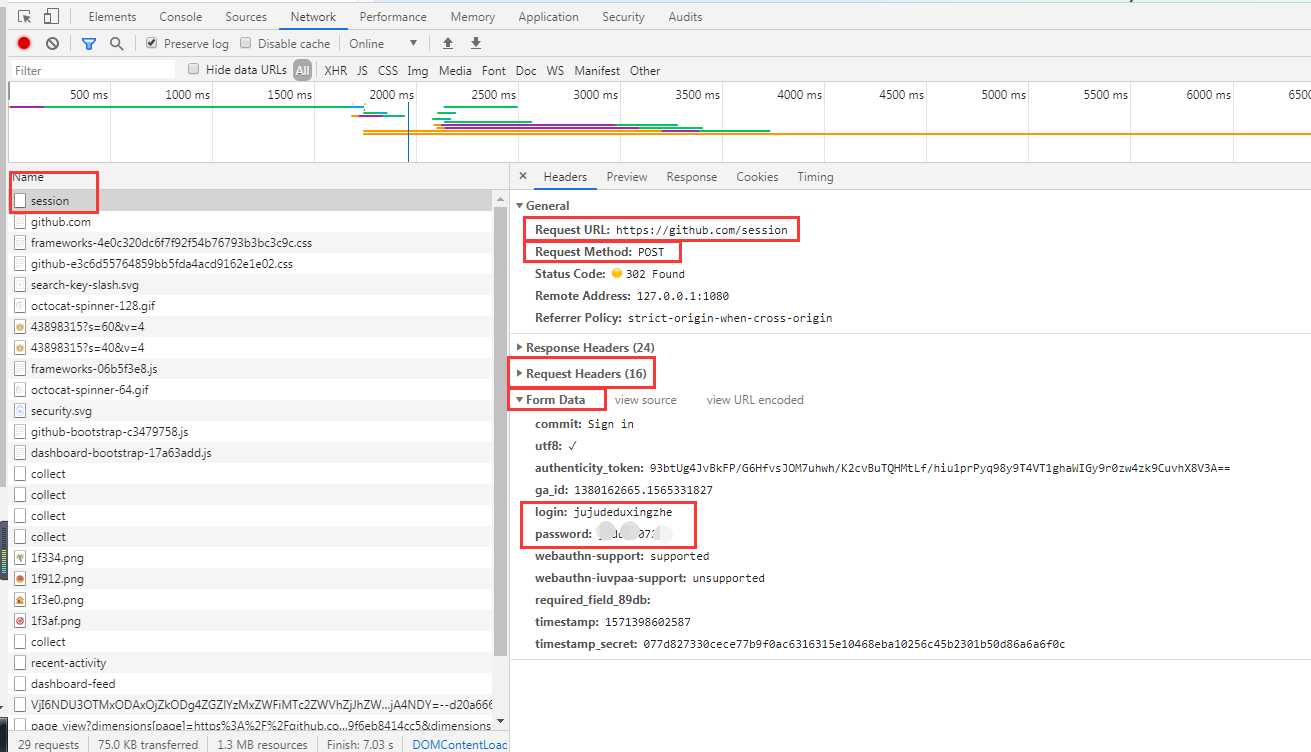
Headers 里面包含了:
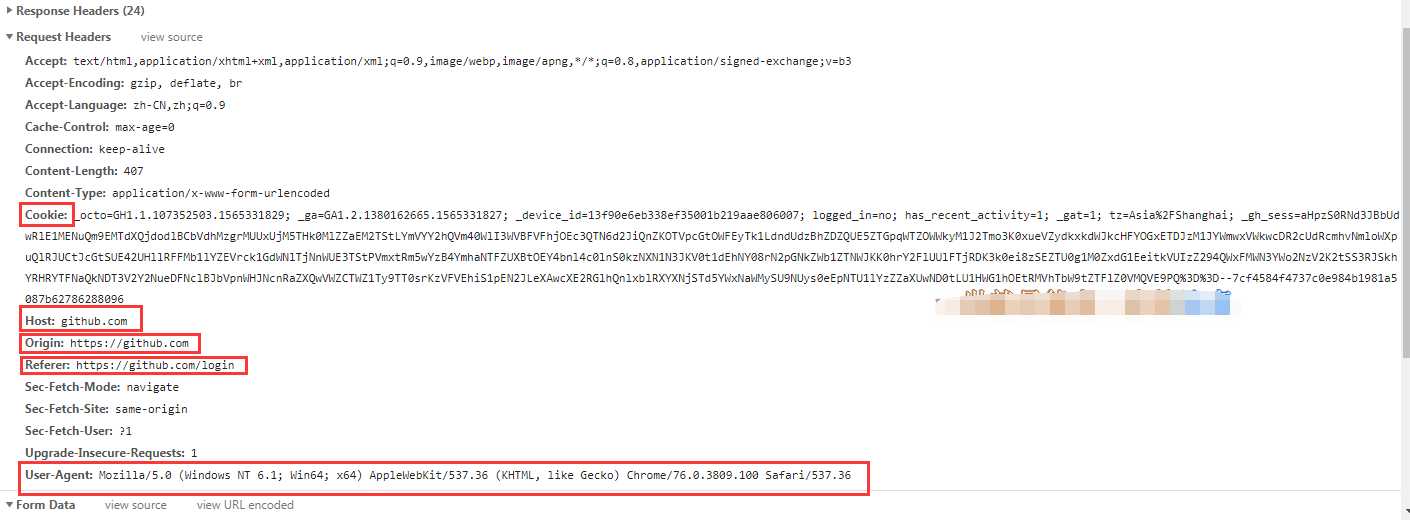
From Data包含了:
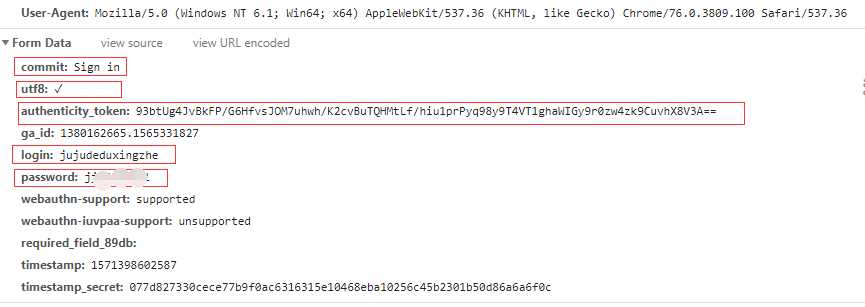
综上,我们无法直接构造的内容包括Cookies和authenticity_token ,下面看一下这两部分怎么获取。
在登录之前我们会访问一个登录页面,此页面是通过Get形式访问的。输入用户名和密码,点击登录按钮,浏览器发送这两部分内容,也就是说Cookies和authenticity_token一定是在访问登录页面时设置的。
我们退出登录,回到登录页,同时清空Cookies ,重新访问登录页,截获发生的请求:
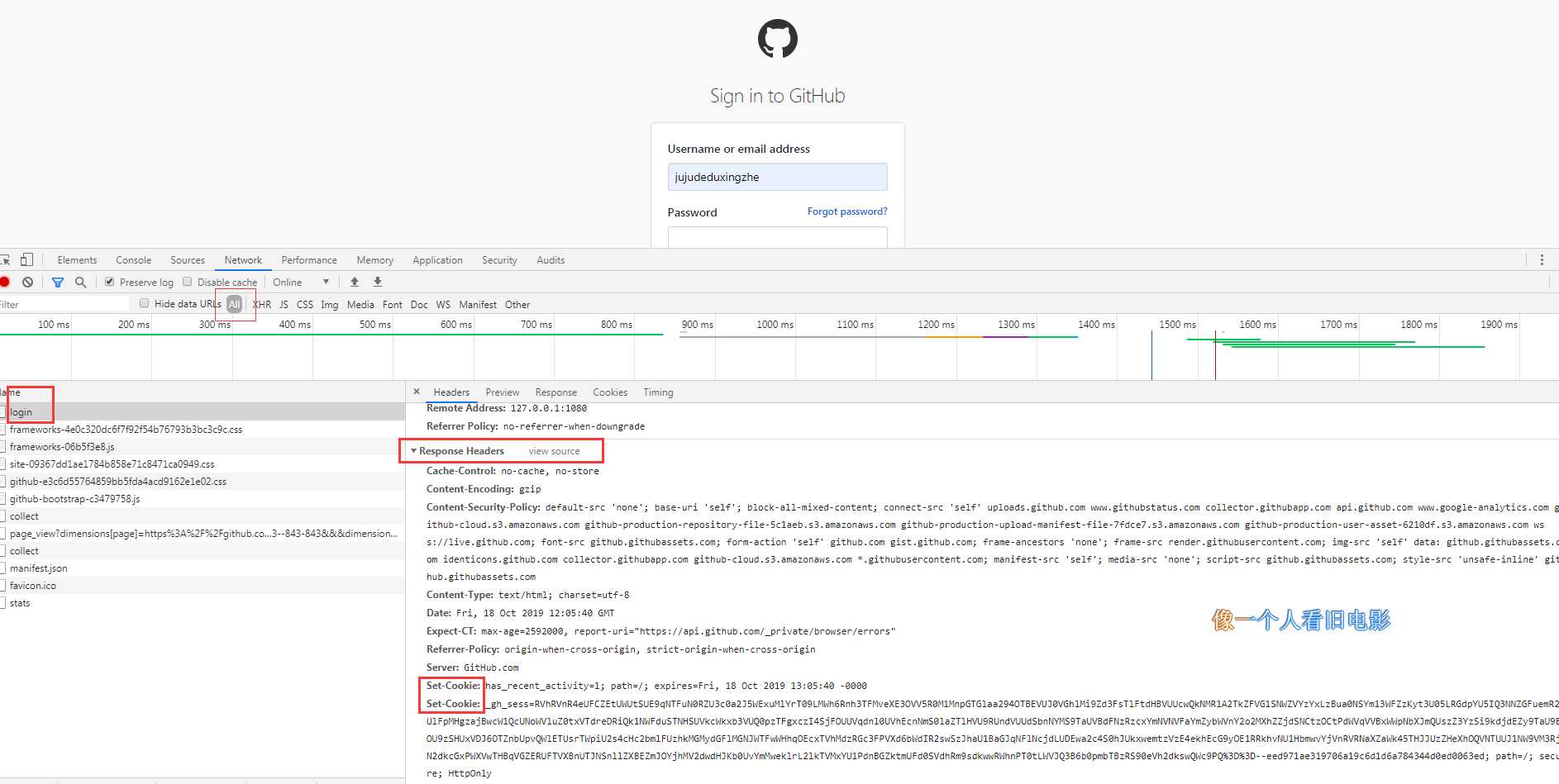
Response Headers有一个Set-Cookie 字段。这就是设置Cookie的过程。
我们发现Response Headers 没有authenticity_token相关的信息,所以authenticity_token可能隐藏在其他的地方或者是计算出来的。从网页的源码查看,搜索相关字段,发现源代码里面隐藏着此信息,他是一个隐藏式表单元素。
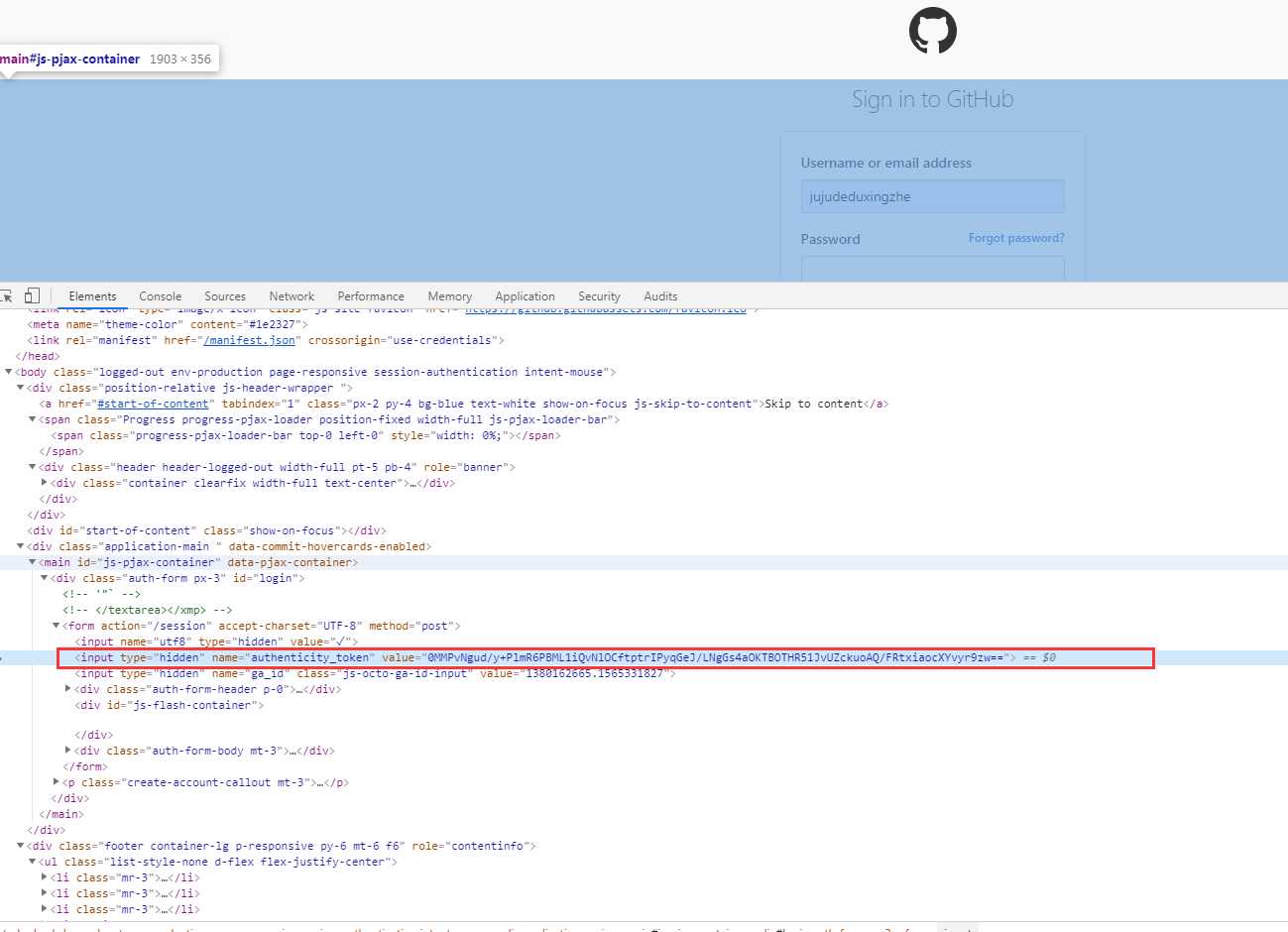
现在我们已经获取到所有信息,接下来实现模拟。
3. 代码实战
首先定义一个Login 类,初始化一些变量:
import requests
class Login(object):
def __init__(self):
self.headers = {
‘Referer‘: ‘https://github.com/‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36‘,
‘Host‘: ‘github.com‘
}
self.login_url = ‘https://github.com/login‘
self.post_url = ‘https://github.com/session‘
self.logined_url = ‘https://github.com/settings/profile‘
self.session = requests.Session() //维持会话,自动处理cookies
接下来,访问登录页面需要完成两件事:
from lxml import etree
def token(self):
response = self.session.get(self.login_url, headers=self.headers) #用Session对象的get()方法访问GitHub的登录页面
selector = etree.HTML(response.text)
token = selector.xpath(‘//div//input[2]/@value‘)[0] #用Xpath解析出登录所需的authenticity_token 信息并返回
return token
开始模拟登录,实现一个login()方法:
def login(self, email, password):
#首先构造一个表单,其中email和password是以变量的形式传递。
post_data = {
‘commit‘: ‘Sign in‘,
‘utf8‘: ‘√‘,
‘authenticity_token‘: self.token(),
‘login‘: email,
‘password‘: password
}
response = self.session.post(self.post_url, data=post_data, headers=self.headers) #用Session对象的post()方法模拟登录
if response.status_code == 200:
self.dynamics(response.text) #得到响应之后用dynamics()对其进行处理
response = self.session.get(self.logined_url, headers=self.headers) #请求个人详情页
if response.status_code == 200:
self.profile(response.text) #用profile处理个人详情页信息
def dynamics(self, html):
selector = etree.HTML(html)
dynamics = selector.xpath(‘//div[contains(@class, "news")]//div[contains(@class, "alert")]‘)
for item in dynamics:
dynamic = ‘ ‘.join(item.xpath(‘.//div[@class="title"]//text()‘)).strip()
print(dynamic)
def profile(self, html):
selector = etree.HTML(html)
name = selector.xpath(‘//input[@id="user_profile_name"]/@value‘)[0]
email = selector.xpath(‘//select[@id="user_profile_email"]/option[@value!=""]/text()‘)
print(name, email)
这样,整个类就编写完成了。
4. 运行
if __name__ == "__main__":
login = Login()
login.login(email=‘jujudeduxingzhe@163.com‘, password=‘password‘)
大家可参照他人文章:http://www.pianshen.com/article/226443350/
2.Cookies 池的搭建
参考来源:https://blog.csdn.net/xmxt668/article/details/92368537
大多数情况下,即使我们没有登录页面,我们也能访问网站的部分页面或者一些请求,因为网站本身要做SEO,不会对所有页面设置登录权限。
百度百科:SEO(Search Engine Optimization):搜索引擎优化,是一种方式:利用搜索引擎的规则提高网站在有关搜索引擎内的自然排名。目的是让其在行业内占据领先地位,获得品牌收益。很大程度上是网站经营者的一种商业行为,将自己或自己公司的排名前移。
但是不登录网站直接爬取有两个弊端:
如果需要做大规模抓取,我们就需要拥有很多账号,每次请求随机选取一个账号,这样就降低了单个账号的访问频率,被封的概率又会大大降低。
维护多个账号的登录信息,这时就需要用到Cookies池了。
2.1 本节内容:
实现一个Cookies池的搭建过程:
2.2 工作准备
2.3 Cookies 池架构
cookies池架构和代理池类似,也包括四个模块:
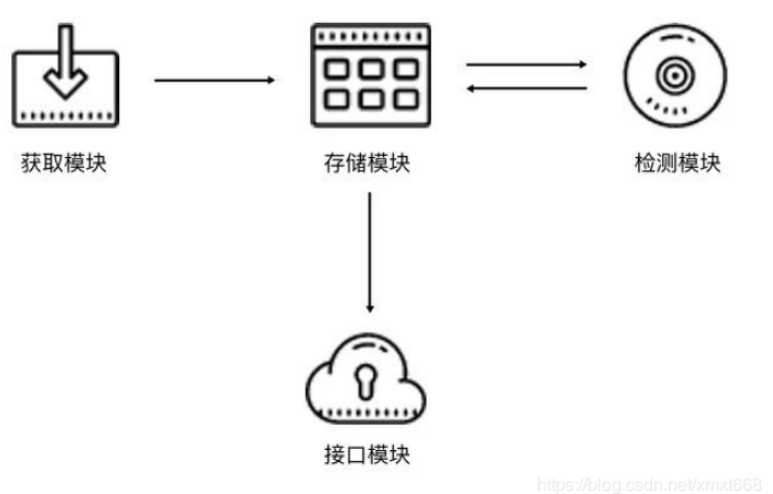
2.4 Cookies 的实现
存储的内容无非就是账号信息和Cookies信息。账号由用户名和密码两部分组成,我们可以存成用户名和密码的映射。Cookies可以存成JSON字符串,但是我们后面得需要根据账号来生成Cookies。生成的时候我们需要知道哪些账号已经生成了Cookies,哪些没有生成,所以需要同时保存该Cookies对应的用户名信息,其实也是用户名和Cookies的映射。这里就是两组映射,我们自然而然想到Redis的Hash,于是就建立两个Hash。
前几节,已经实现了Redis的安装以及可视化管理工具的安装,见:https://www.cnblogs.com/bltstop/p/11686568.html
接下来我们用Redis 可视化管理工具来实现Hash的创建,可参考百度经验(https://jingyan.baidu.com/article/ae97a646ff37f3bbfd461d01.html)
打开RedisDesktopManager,并连接到redis服务器。选择其中一个db数据库,选择"Add new key"新建一个hash数据:
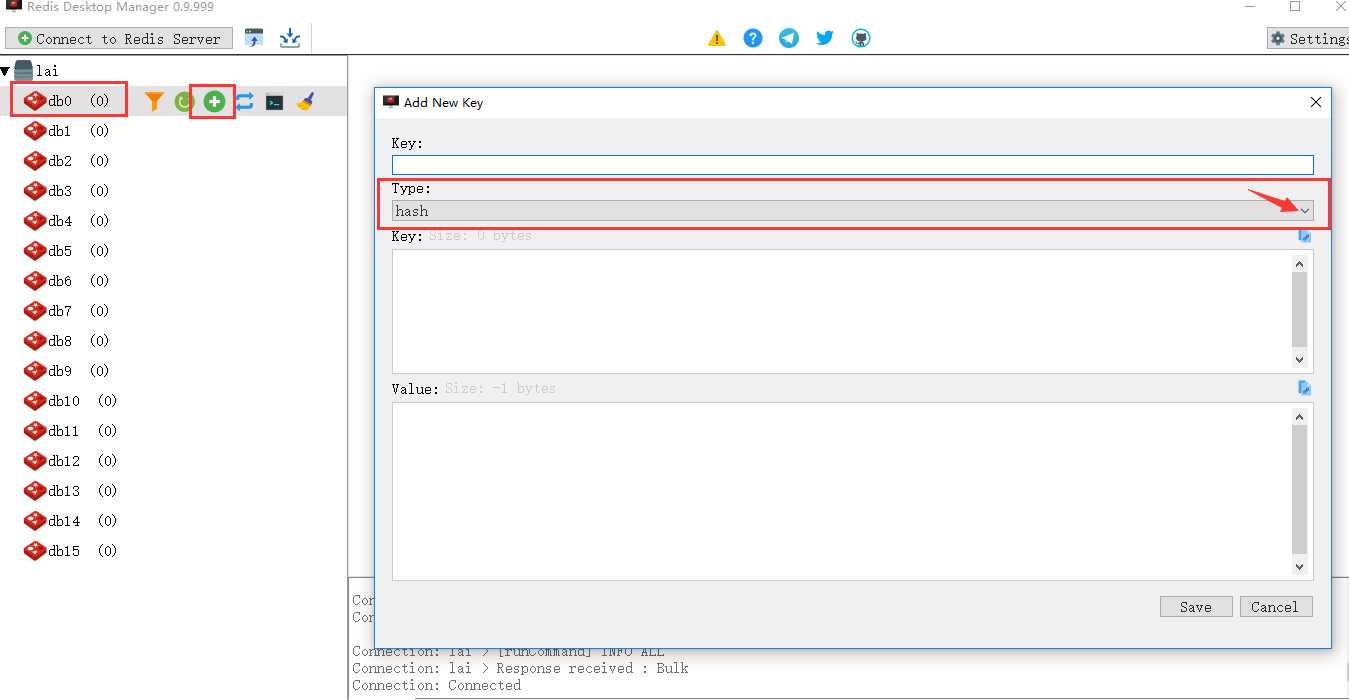
新建对话创建,注意选择"hash"类型,value分成两部分,上面是hash的key,下面填的是hash的value;
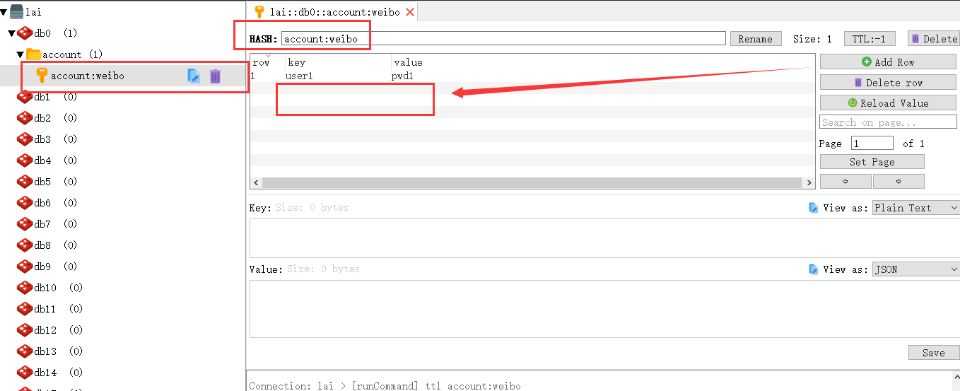
添加完成之后,如果没有立即显示出来,点击刷新重新加载数据,选择新建的key,右侧页面则可以展示详细的信息;
点击Add row,可以添加一个元素,填写key和value:
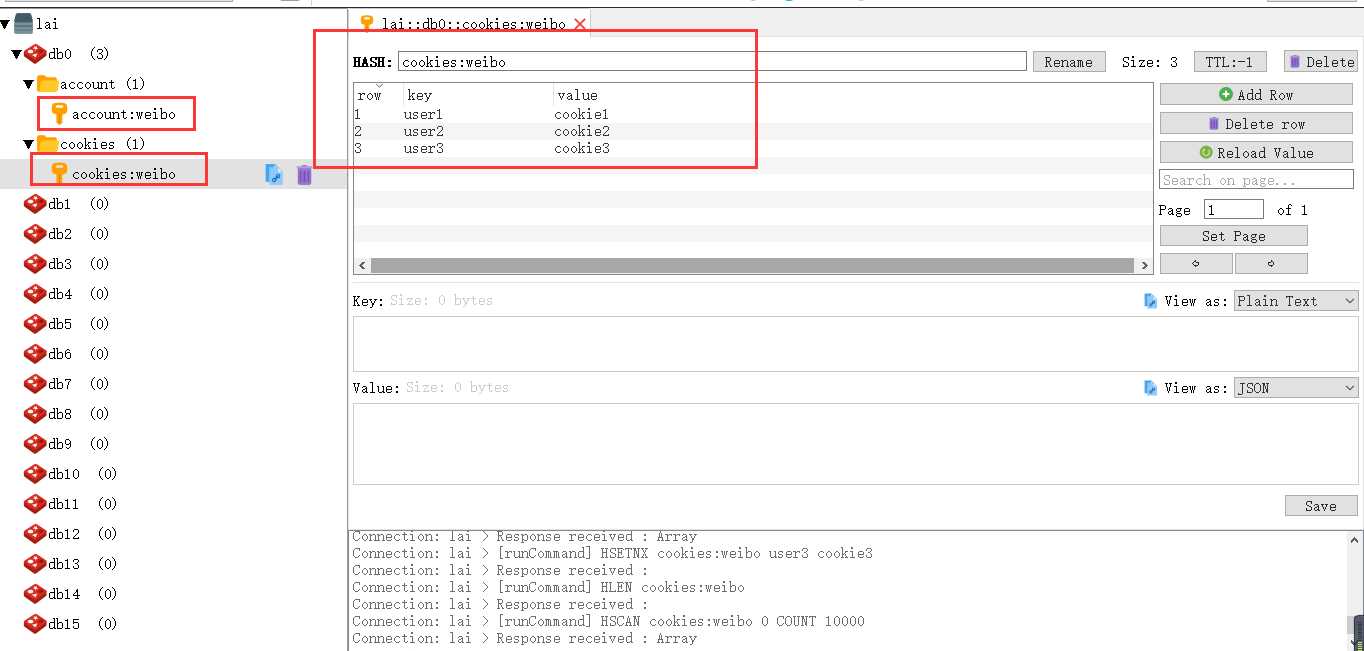
同理,创建Hash:cookies:weibo:
接下来创建一个存储模块类,用以提供一些Hash的基本操作:
import random
import redis
class RedisClient(object):
def __init__(self, type, website, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
"""
初始化Redis连接
:param host: 地址
:param port: 端口
:param password: 密码
"""
self.db = redis.StrictRedis(host=host, port=port, password=password, decode_responses=True)
self.type = type
self.website = website
def name(self):
"""
获取Hash的名称
:return: Hash名称
"""
return "{type}:{website}".format(type=self.type, website=self.website)
def set(self, username, value):
"""
设置键值对
:param username: 用户名
:param value: 密码或Cookies
:return:
"""
return self.db.hset(self.name(), username, value)
def get(self, username):
"""
根据键名获取键值
:param username: 用户名
:return:
"""
return self.db.hget(self.name(), username)
def delete(self, username):
"""
根据键名删除键值对
:param username: 用户名
:return: 删除结果
"""
return self.db.hdel(self.name(), username)
def count(self):
"""
获取数目
:return: 数目
"""
return self.db.hlen(self.name())
def random(self):
"""
随机得到键值,用于随机Cookies获取
:return: 随机Cookies
"""
return random.choice(self.db.hvals(self.name()))
def usernames(self):
"""
获取所有账户信息
:return: 所有用户名
"""
return self.db.hkeys(self.name())
def all(self):
"""
获取所有键值对
:return: 用户名和密码或Cookies的映射表
"""
return self.db.hgetall(self.name())
这里我们新建了一个RedisClient类,初始化__init__()方法有两个关键参数type和website,分别代表类型和站点名称,它们就是用来拼接Hash名称的两个字段。如果这是存储账户的Hash,那么此处的type为accounts、website为weibo,如果是存储Cookies的Hash,那么此处的type为cookies、website为weibo。
接下来还有几个字段代表了Redis的连接信息,初始化时获得这些信息后初始化StrictRedis对象,建立Redis连接。
name()方法拼接了type和website,组成Hash的名称。set()、get()、delete()方法分别代表设置、获取、删除Hash的某一个键值对,count()获取Hash的长度。
比较重要的方法是random(),它主要用于从Hash里随机选取一个Cookies并返回。每调用一次random()方法,就会获得随机的Cookies,此方法与接口模块对接即可实现请求接口获取随机Cookies。
生成模块负责获取各个账号信息并模拟登录,随后生成Cookies并保存。我们首先获取两个Hash的信息,看看账户的Hash比Cookies的Hash多了哪些还没有生成Cookies的账号,然后将剩余的账号遍历,再去生成Cookies即可。
这里主要逻辑就是找出那些还没有对应Cookies的账号,然后再逐个获取Cookies:
for username in accounts_usernames: if not username in cookies_usernames: password = self.accounts_db.get(username) print(‘正在生成Cookies‘, ‘账号‘, username, ‘密码‘, password) result = self.new_cookies(username, password)
我们对接的是新浪微博,前面我们已经破解了新浪微博的四宫格验证码,在这里我们直接对接过来即可,不过现在需要加一个获取Cookies的方法,并针对不同的情况返回不同的结果,逻辑如下所示:
def get_cookies(self): return self.browser.get_cookies() def main(self): self.open() if self.password_error(): return { ‘status‘: 2, ‘content‘: ‘用户名或密码错误‘ } # 如果不需要验证码直接登录成功 if self.login_successfully(): cookies = self.get_cookies() return { ‘status‘: 1, ‘content‘: cookies } # 获取验证码图片 image = self.get_image(‘captcha.png‘) numbers = self.detect_image(image) self.move(numbers) if self.login_successfully(): cookies = self.get_cookies() return { ‘status‘: 1, ‘content‘: cookies } else: return { ‘status‘: 3, ‘content‘: ‘登录失败‘ }
这里返回结果的类型是字典,并且附有状态码status,在生成模块里我们可以根据不同的状态码做不同的处理。例如状态码为1的情况,表示成功获取Cookies,我们只需要将Cookies保存到数据库即可。如状态码为2的情况,代表用户名或密码错误,那么我们就应该把当前数据库中存储的账号信息删除。如状态码为3的情况,则代表登录失败的一些错误,此时不能判断是否用户名或密码错误,也不能成功获取Cookies,那么简单提示再进行下一个处理即可,类似代码实现如下所示:
result = self.new_cookies(username, password) # 成功获取 if result.get(‘status‘) == 1: cookies = self.process_cookies(result.get(‘content‘)) print(‘成功获取到Cookies‘, cookies) if self.cookies_db.set(username, json.dumps(cookies)): print(‘成功保存Cookies‘) # 密码错误,移除账号 elif result.get(‘status‘) == 2: print(result.get(‘content‘)) if self.accounts_db.delete(username): print(‘成功删除账号‘) else: print(result.get(‘content‘))
如果要扩展其他站点,只需要实现new_cookies()方法即可,然后按此处理规则返回对应的模拟登录结果,比如1代表获取成功,2代表用户名或密码错误。
我们现在可以用生成模块来生成Cookies,但还是免不了Cookies失效的问题,例如时间太长导致Cookies失效,或者Cookies使用太频繁导致无法正常请求网页。如果遇到这样的Cookies,我们肯定不能让它继续保存在数据库里。
所以我们还需要增加一个定时检测模块,它负责遍历池中的所有Cookies,同时设置好对应的检测链接,我们用一个个Cookies去请求这个链接。如果请求成功,或者状态码合法,那么该Cookies有效;如果请求失败,或者无法获取正常的数据,比如直接跳回登录页面或者跳到验证页面,那么此Cookies无效,我们需要将该Cookies从数据库中移除。
此Cookies移除之后,刚才所说的生成模块就会检测到Cookies的Hash和账号的Hash相比少了此账号的Cookies,生成模块就会认为这个账号还没生成Cookies,那么就会用此账号重新登录,此账号的Cookies又被重新更新。
检测模块需要做的就是检测Cookies失效,然后将其从数据中移除。
为了实现通用可扩展性,我们首先定义一个检测器的父类,声明一些通用组件,实现如下所示:
class ValidTester(object):
def __init__(self, website=‘default‘):
self.website = website
self.cookies_db = RedisClient(‘cookies‘, self.website)
self.accounts_db = RedisClient(‘accounts‘, self.website)
def test(self, username, cookies):
raise NotImplementedError
def run(self):
cookies_groups = self.cookies_db.all()
for username, cookies in cookies_groups.items():
self.test(username, cookies)
在这里定义了一个父类叫作ValidTester,在__init__()方法里指定好站点的名称website,另外建立两个存储模块连接对象cookies_db和accounts_db,分别负责操作Cookies和账号的Hash,run()方法是入口,在这里是遍历了所有的Cookies,然后调用test()方法进行测试,在这里test()方法是没有实现的,也就是说我们需要写一个子类来重写这个test()方法,每个子类负责各自不同网站的检测,如检测微博的就可以定义为WeiboValidTester,实现其独有的test()方法来检测微博的Cookies是否合法,然后做相应的处理,所以在这里我们还需要再加一个子类来继承这个ValidTester,重写其test()方法,实现如下:
import json
import requests
from requests.exceptions import ConnectionError
class WeiboValidTester(ValidTester):
def __init__(self, website=‘weibo‘):
ValidTester.__init__(self, website)
def test(self, username, cookies):
print(‘正在测试Cookies‘, ‘用户名‘, username)
try:
cookies = json.loads(cookies)
except TypeError:
print(‘Cookies不合法‘, username)
self.cookies_db.delete(username)
print(‘删除Cookies‘, username)
return
try:
test_url = TEST_URL_MAP[self.website]
response = requests.get(test_url, cookies=cookies, timeout=5, allow_redirects=False)
if response.status_code == 200:
print(‘Cookies有效‘, username)
print(‘部分测试结果‘, response.text[0:50])
else:
print(response.status_code, response.headers)
print(‘Cookies失效‘, username)
self.cookies_db.delete(username)
print(‘删除Cookies‘, username)
except ConnectionError as e:
print(‘发生异常‘, e.args)
test()方法首先将Cookies转化为字典,检测Cookies的格式,如果格式不正确,直接将其删除,如果格式没问题,那么就拿此Cookies请求被检测的URL。test()方法在这里检测微博,检测的URL可以是某个Ajax接口,为了实现可配置化,我们将测试URL也定义成字典,如下所示:
TEST_URL_MAP = {
‘weibo‘: ‘https://m.weibo.cn/‘
}
如果要扩展其他站点,我们可以统一在字典里添加。对微博来说,我们用Cookies去请求目标站点,同时禁止重定向和设置超时时间,得到Response之后检测其返回状态码。如果直接返回200状态码,则Cookies有效,否则可能遇到了302跳转等情况,一般会跳转到登录页面,则Cookies已失效。如果Cookies失效,我们将其从Cookies的Hash里移除即可。
生成模块和检测模块如果定时运行就可以完成Cookies实时检测和更新。但是Cookies最终还是需要给爬虫来用,同时一个Cookies池可供多个爬虫使用,所以我们还需要定义一个Web接口,爬虫访问此接口便可以取到随机的Cookies。我们采用Flask来实现接口的搭建,代码如下所示:
import json
from flask import Flask, g
app = Flask(__name__)
# 生成模块的配置字典
GENERATOR_MAP = {
‘weibo‘: ‘WeiboCookiesGenerator‘
}
@app.route(‘/‘)
def index():
return ‘<h2>Welcome to Cookie Pool System</h2>‘
def get_conn():
for website in GENERATOR_MAP:
if not hasattr(g, website):
setattr(g, website + ‘_cookies‘, eval(‘RedisClient‘ + ‘("cookies", "‘ + website + ‘")‘))
return g
@app.route(‘/<website>/random‘)
def random(website):
"""
获取随机的Cookie, 访问地址如 /weibo/random
:return: 随机Cookie
"""
g = get_conn()
cookies = getattr(g, website + ‘_cookies‘).random()
return cookies
们同样需要实现通用的配置来对接不同的站点,所以接口链接的第一个字段定义为站点名称,第二个字段定义为获取的方法,例如,/weibo/random是获取微博的随机Cookies,/zhihu/random是获取知乎的随机Cookies。
最后,我们再加一个调度模块让这几个模块配合运行起来,主要的工作就是驱动几个模块定时运行,同时各个模块需要在不同进程上运行,实现如下所示:
import time
from multiprocessing import Process
from cookiespool.api import app
from cookiespool.config import *
from cookiespool.generator import *
from cookiespool.tester import *
class Scheduler(object):
@staticmethod
def valid_cookie(cycle=CYCLE):
while True:
print(‘Cookies检测进程开始运行‘)
try:
for website, cls in TESTER_MAP.items():
tester = eval(cls + ‘(website="‘ + website + ‘")‘)
tester.run()
print(‘Cookies检测完成‘)
del tester
time.sleep(cycle)
except Exception as e:
print(e.args)
@staticmethod
def generate_cookie(cycle=CYCLE):
while True:
print(‘Cookies生成进程开始运行‘)
try:
for website, cls in GENERATOR_MAP.items():
generator = eval(cls + ‘(website="‘ + website + ‘")‘)
generator.run()
print(‘Cookies生成完成‘)
generator.close()
time.sleep(cycle)
except Exception as e:
print(e.args)
@staticmethod
def api():
print(‘API接口开始运行‘)
app.run(host=API_HOST, port=API_PORT)
def run(self):
if API_PROCESS:
api_process = Process(target=Scheduler.api)
api_process.start()
if GENERATOR_PROCESS:
generate_process = Process(target=Scheduler.generate_cookie)
generate_process.start()
if VALID_PROCESS:
valid_process = Process(target=Scheduler.valid_cookie)
valid_process.start()
这里用到了两个重要的配置,即产生模块类和测试模块类的字典配置,如下所示:
# 产生模块类,如扩展其他站点,请在此配置 GENERATOR_MAP = { ‘weibo‘: ‘WeiboCookiesGenerator‘ } # 测试模块类,如扩展其他站点,请在此配置 TESTER_MAP = { ‘weibo‘: ‘WeiboValidTester‘ }
这样的配置是为了方便动态扩展使用的,键名为站点名称,键值为类名。如需要配置其他站点可以在字典中添加,如扩展知乎站点的产生模块,则可以配置成:
GENERATOR_MAP = { ‘weibo‘: ‘WeiboCookiesGenerator‘, ‘zhihu‘: ‘ZhihuCookiesGenerator‘, }
Scheduler里将字典进行遍历,同时利用eval()动态新建各个类的对象,调用其入口run()方法运行各个模块。同时,各个模块的多进程使用了multiprocessing中的Process类,调用其start()方法即可启动各个进程。
另外,各个模块还设有模块开关,我们可以在配置文件中自由设置开关的开启和关闭,如下所示:
# 产生模块开关
GENERATOR_PROCESS = True
# 验证模块开关
VALID_PROCESS = False
# 接口模块开关
API_PROCESS = True
定义为True即可开启该模块,定义为False即关闭此模块。
至此,我们的Cookies就全部完成了。接下来我们将模块同时开启,启动调度器,控制台类似输出如下所示:
API接口开始运行 * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)Cookies生成进程开始运行Cookies检测进程开始运行正在生成Cookies 账号 14747223314 密码 asdf1129正在测试Cookies 用户名 14747219309Cookies有效 14747219309正在测试Cookies 用户名 14740626332Cookies有效 14740626332正在测试Cookies 用户名 14740691419Cookies有效 14740691419正在测试Cookies 用户名 14740618009Cookies有效 14740618009正在测试Cookies 用户名 14740636046Cookies有效 14740636046正在测试Cookies 用户名 14747222472Cookies有效 14747222472Cookies检测完成验证码位置 420 580 384 544成功匹配拖动顺序 [1, 4, 2, 3]成功获取到Cookies {‘SUHB‘: ‘08J77UIj4w5n_T‘, ‘SCF‘: ‘AimcUCUVvHjswSBmTswKh0g4kNj4K7_U9k57YzxbqFt4SFBhXq3Lx4YSNO9VuBV841BMHFIaH4ipnfqZnK7W6Qs.‘, ‘SSOLoginState‘: ‘1501439488‘, ‘_T_WM‘: ‘99b7d656220aeb9207b5db97743adc02‘, ‘M_WEIBOCN_PARAMS‘: ‘uicode%3D20000174‘, ‘SUB‘: ‘_2A250elZQDeRhGeBM6VAR8ifEzTuIHXVXhXoYrDV6PUJbkdBeLXTxkW17ZoYhhJ92N_RGCjmHpfv9TB8OJQ..‘}成功保存Cookies
申明:本文内容部分转自:https://blog.csdn.net/xmxt668/article/details/92368537
标签:data ext 有用 choice scheduler 遇到 set ova 新浪
原文地址:https://www.cnblogs.com/bltstop/p/11700549.html