标签:死锁 对象 快速 方案 数据库架构 估算 sql优化 with data
一、现象 /pinter/case/slow?userName=xxx
tps很低,响应时间很长,数据库服务器cpu很高(接近100%),应用服务器负载比较低
索引
索引是对数据库表中一列或多列的值进行排序的一种结构,存储了表中的关键字段,使用索引可快速访问数据库表中的特定信息。类似于书籍中的目录。
二、分析
数据库服务器CPU高,一般都是因为SQL执行效率低导致的,可能有三方面原因
1、数据库表缺少必要的索引;
2、索引不生效
3、SQL不够优化
三、慢查询
在MySQL中,可以监控SQL语句的执行效率,并分析SQL使用索引的情况,从而协助定位性能问题,慢SQL的配置和抓取配置方法如下:
1 、 开启 开启慢 慢 SQL 的配置
1.1 LIUNX 系统 在 mysql 配置文件 my.cnf 中增加
slow_query_log
slow_query_log_file=/usr/local/mysql/data/zhoucentos-slow.log
long_query_time=0.1
? Slow_query_log 这是一个布尔型变量,默认为真。没有这变量,数据库不会打印慢查询的日志。
? log-slow-log_file=/export/servers/mysql/bin/mysql_slow.log (指定日志文件存放位置,可以为空,系统会给一个缺省的文件 host_name-slow.log)
? long_query_time=0.1(记录超过的时间,默认为 10s),与 DBA 沟通,性能测试分析问题时可以将该值设为 0.1 即 100 毫秒,这样分析的粒度更详细。
备选 :log-queries-not-using-indexes (log 下来没有使用索引的 query,可以根据情况决定是否开启)。log-long-format (如果设置了,所有没有使用索引的查询也将被记录)
1.2 Windows 下配置: 在 my.ini 的[mysqld]添加如下语句:
log-slow-queries = E:\web\mysql\log\mysqlslowquery.log
long_query_time = 0.1(其他参数如上)
注: 配置完成后,重新 mysql 服务配置才能生效。
2 、 慢查询开启与关闭
2.1 配置完成,连接数据库检查慢查询日志是否开启:
命令如下:mysql> show variables like ‘%slow_query_log%‘;
2.2 如果没有打开,请开启,slow_query_log
开启命令:mysql> set @@global.slow_query_log = on;
关闭命令:mysql> set @@global.slow_query_log = off;
2.3 再次检查是否开启成功: mysql> show variables like ‘%slow_query_log%‘;
2.4 检查目录中是否生成文件:/mysql 目录下是否存在 mysql_slow.log
[root@localhost mysql]# ls -l mysql_slow.log
3 、 慢查询日志分析
3.1 Linux 系统:
SQL 语句的执行信息
常用命令,通过 mysqldumpslow –help 查看
? -s,是 order 的排序,主要有 c,t,l,r 和 ac,at,al,ar,分别是按照 query 次数,时间,lock 的时间和返回的记录数来排序
? -a,倒序排列
? -t,是 top n 的意思,即为返回前面多少条的数据
? -g,后边可以写一个正则匹配模式,大小写不敏感的
例如: mysqldumpslow -s c -t 20 host-slow.log
mysqldumpslow -s r -t 20 host-slow.log
上述命令分别可以看出访问次数最多的 20 个 sql 语句和返回记录集最多的 20 个 sql。
mysqldumpslow -t 10 -s t -g “left join” host-slow.log 这个是按照时间返回前 10条里面含有左连接的 sql 语句。
使用 mysql 自带命令 mysqldumpslow ,在mysql/bin目录下执行 mysqldumpslow –s at -t 50 host-slow.log 显示出耗时最长的 50 个,注意慢查询日志log路径带全
以 Count: 32 Time=0.26s (8s) Lock=0.00s (0s) Rows=10.0 (320),
wos_20120719[wos_20120719]@2host 为例:
Count: 32 该 SQL 总共执行 32 次
Time = 0.26s (8s) 平均每次执行该 SQL 耗时 0.26 秒,总共耗时 32(次)*0.26(秒)=8 秒。
Lock=0.00s(0s) lock 时间 0 秒
Rows =10.0(320) 每次执行 SQL 影响数据库表中的 10 行记录,总共影响 10(行)*32(次)=320 行记录
3.2 Windows 系统:
当你是第一次开启 mysql 的慢查询,会在你指定的目录下创建这个记录文件,本文就是mysqlslowquery.log,这个文件的内容大致如下(第一次开启 MYSQL 慢查询的情况下)
E:\web\mysql\bin\mysqld, Version: 5.4.3-beta-community-log (MySQLCommunity Server (GPL)). started with:TCP Port: 3306, Named Pipe: (null) Time Id Command Argument
可以通过如下的命令来查看慢查询的记录数:
mysql> show global status like ‘%slow%’;
+———————+——-+
| Variable_name | Value |
+———————+——-+
| Slow_launch_threads | 0 |
| Slow_queries | 0 |
+———————+——-+
四、执行计划
执行计划
在sql语句前加上explain,可以分析这条sql语句的执行情况
explain select * from teacher where
Type列可能的值
Const:表中只有一个匹配行,用到primary key或unique key
Eq_ref:唯一性索引扫描,key的所有部分被连接联接查询使用,且key是unique或primary key
ref:非唯一性索引扫描,或只使用了联合索引的最左前缀
Range:索引范围扫描,在索引列上进行给定范围内的检索,如between,in(1,100)
Index:遍历索引...
All:全表扫描
Prossible key:使用哪个索引能找到行
Keys:sql语句使用的索引
rows:mysql 根据索引选择情况,估算查找数据所需读取的行数
五、联合索引
联合索引,比单个索引性能更好
一个索引同时作用于多个字段,一个索引建议不超过4个字段
联合索引的最左前缀
联合索引检索数据时,会从最左边开始匹配(忽略sql字段顺序),如果匹配不到,就不使用索引
如:User表有联合索引my_index(A字段,B字段,C字段)
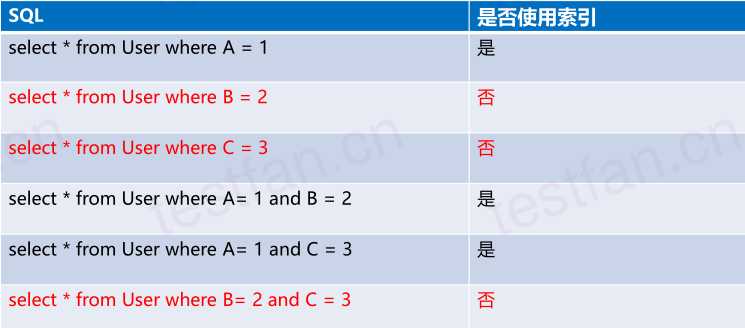
六、连接数
连接数监控命令
show variables like ‘%connections%‘
show status like ‘%thread%
其中:
Threads_connected 当前打开的连接的数量
Threads_cached 线程缓存内的线程的数量
Threads_created 创建的线程数
Threads_running 激活的(非睡眠状态)线程数
show status like ‘%connection%‘
Connections 试图连接MySQL服务器的次数
七、数据库架构优化
架构优化
读写分离,主从配置
分库分表,根据一个固定的算法来路由库名和表名,如id%10,1202922292
user_1
user_2
user_3
...
user_10
硬件调优
使用更好的物理磁盘介质,如SSD、fusionIO卡等
八、SQL优化
常见的一些sql优化方案
1、在 where 及 order by 涉及的列上建立索引,避免全表扫描,索引不要太多,一个表一般不要
超过4个索引
2、避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
3、查询语句中不要使用 *,减少内存使用
4、尽量减少子查询,使用关联查询(left join,right join,inner join)替代
5、减少使用IN或者NOT IN ,使用exists,not exists或者关联查询语句替代
6、or 的查询尽量用 union或者union all 代替(在确认没有重复数据或者不用剔除重复数据时,
union all会更好)
7、合理的增加冗余的字段(减少表的联接查询)
8、建表的时候能使用数字类型的字段就使用数字类型(type,status...),数字类型的字段作为条
件查询比字符串的快
九、代码优化
代码优化原则
1、使用对象池减少对重复对象的创建;
2、调整对后端的连接
3、增加本地缓存
4、如果不涉及事务的情况下,考虑使用Nosql进行存储
5、一次请求合并多次操作
6、由串行修改为并行操作
7、同步修改为异步
十、性能瓶颈定位思路(面试必问)
整体思路:从前到后,从表象到内部
1、首先排除压力机自身的问题,如CPU、内存,网络,脚本编写等
2、监控中间件的访问日志,观察响应时间,大体确定耗时处于哪一段
3、排查网络问题,监控压力机到后端服务器的网络,以及各服务器间的网络,是否达到网络上限
4、监控服务端所有机器的操作系统负载,如CPU、内存、磁盘、网络是否达到瓶颈
5、监控应用服务器的日志,查看是否存在ERROR日志,比如TimeOut或其他类型报错
6、监控各中间件的连接数,如nginx、tomcat、mysql等,是否达到上限
7、监控应用程序线程状态,使用jstack或jvisualvm查看是否有死锁、阻塞等情况
8、监控应用程序的jvm,使用jstat或者jmap查看GC情况,是否内存泄漏等
9、使用jprofiler监控应用程序,可以查看耗时比较长的代码方法
10、监控数据库,是否存在慢查询,一般数据库CPU高都是因为SQL语句效率低造成的
11、检查数据库执行计划,是否有全表扫描,以及索引不生效的情况
12、检查系统外部依赖情况,如果外部依赖系统性能差,也会造成本系统性能低
13、对于不好定位的问题,可以考虑采用模块隔离法来确定问题
标签:死锁 对象 快速 方案 数据库架构 估算 sql优化 with data
原文地址:https://www.cnblogs.com/qingyuu/p/11603939.html