标签:设置 acm 算法优化 相对 order namespace 连续 dia 邻接
图:G = (V,E),集合V中的元素被称为顶点,集合E中的元素是集合V中的某一对顶点(u,v)之间的边。
约定集合V和集合E均为有限集,其规模分别记为n = | V |,e = | E |。
边:顶点之间存在的某种关系就是边。可分为有向边和无向边。若边(u,v)中的顶点u和v的次序无所谓,即(u,v) = (v,u),边(u,v)即为无向边,反之即为有向边。
有向图和无向图:当一个图中的所有边都是无向边时,该图为无向图。而只要一个图中存在有向边,该图就是有向图。
度:与某顶点关联的边数就是该顶点的度。特别地,对于有向边e = (u,v),e为u的出边,v的入边。出边和入边的数目分别为出度和入度。
环:连接同一个顶点的边称为环。即该边由一个顶点出发,然后回到该顶点。
简单图:没有环的图称为简单图。
路径:路径是一个顶点序列w1,w2,... ...,wn,使得(wi,wi+1)∈E,1 <= i < n
一条不包含边的路径长度为0。
简单路径:除了第一个和最后一个顶点,各顶点互异的路径。
基础图:有向图去掉边的方向得到的无向图即为该图的基础图。
连通性:如果一个无向图中的每一个顶点到每个其他顶点都存在一条路径,称该无向图是连通的。
一个有向图具有此性质时,称其为强连通的。如果虽然有向图本身不具有强连通性,但其基础图具有连通性,则称该有向图是弱连通的。
完全图:每一个顶点间都存在一条边的图。
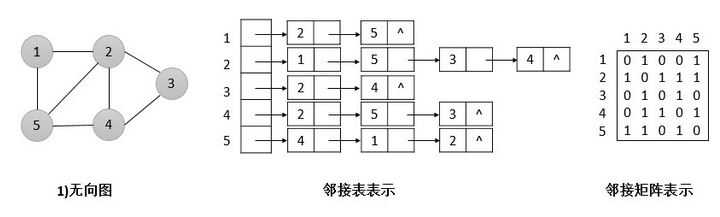
1)邻接矩阵:借助二维数组/向量存储边的权值。
对于每条边(u,v),置A[u][v] = 该边的权值。如果顶点u和v之间不存在边,可以置A[u][v] = ∞。
这种思路十分简单,操作也很容易。
实现思路:分别声明一个顶点对象,边对象和图对象。
顶点对象中的数据成员应该包括:该顶点的出度和入度。
边对象中的数据成员应该包括:边的权值。
图对象中的数据成员应该包括:顶点集(图论相关算法题的输入常常是顶点集)和边集(二维数组/向量,即该图对应的邻接矩阵)。
复杂度分析:其更为底层的数据结构是向量。得益于向量的特性,邻接矩阵实现的图ADT中,所有的静态接口时间复杂度均为O(1)。
而涉及到图中顶点的动态操作(插入,删除)时,需要对向量进行扩容,由均摊分析可知其时间复杂度至多为O(n)。
空间复杂度为O(| V |2)。
其缺陷也很明显,若图是稠密的,邻接矩阵的效率将很高,因为此时邻接矩阵中几乎所有的元素都非0。
而当图是稀疏的,就会出现邻接矩阵中大量元素置0的情况,这样的空间利用率无疑是很差的。
2)邻接表:借助链表和散列表实现。
以图中的每个顶点为索引建立链表,将与其邻接的顶点链接到对应的顶点上。
实际应用中,顶点名常常不是数字,需要建立字符到数字编号的映射,此时采用散列表是很合适的。
映射完成后,此后执行的操作都是根据内部的编号来进行的。
输入一个图G(V,E),对于任意两个顶点vi,vj,穿越其边(vi,vj)所需要的代价为ci,j(也就是权值)。对于赋权图,一条路径的长就是其中所有边权值的总和(称为赋权路径长),而对于无权图,一条路径的长就是其经过的边数(称为无权路径长)。
单源最短路问题:给定一个赋权图和其中的一个顶点s,找出s到图中其他所有顶点的最短赋权路径。
无权最短路径:先从单源最短路的特殊情况——无权图开始考虑。无权图意味着,我们只需关注路径中的边数而无需在意其权值(默认所有边权值为1)。
广度优先搜索(BFS,breath-first search):广度搜索优先的思路类似于树的层序遍历,分阶段进行。
实现思路:首先设置一个标记数组vis[n],所有值初始化为0,n为图中的顶点总数,记录每一个顶点是否已经被访问过,访问过后则置其值为1。
然后声明一个路径长度数组dp,所有值初始化为∞,记录访问到相应顶点时的路径长度。
开始搜索,从顶点s出发,置vis[1] = 1,dp[1] = 0,寻找其邻接点(距离为1的点),分别将其dp数组值置为dp[1] + 1(dp[1]可以看作上一层搜索得到的最短路径长,代码实现时可以设置一个临时变量跟踪每一层搜索得到的最短路径长),标记数组值置为1,表明已经访问过该顶点。
接着需要搜索距离s距离为2的顶点,毫无疑问,只需找到与s的邻接点的距离为1且没有被访问过的顶点即可,重复相似的过程。
当所有顶点都被访问过(即遍历,此时vis数组中的值均为1),搜索结束。此时存放在dp数组中的值即为出发点s到相应顶点的最短路径长。
复杂度分析:查找邻接点需要嵌套for循环,时间复杂度为O(n2),而整体只需遍历一遍图,复杂度为O(n)
优化(一种算法优化的思想):BFS的缺陷在于无法及时判断是否已经访问过所有的顶点,以至于有时候明明早已遍历了整个图,BFS仍将继续循环。
这时候可以运用另一种思想,将访问过的点和没有访问过的点分成两堆。《数据结构与算法分析(C语言描述)》这本书中形象地将这个策略比喻成两个盒子,盒子1中装着已经访问过的,盒子2中装着还没访问过的,每次从盒子2中选取顶点访问,访问完了就将其置入盒子1,最后当盒子2为空时,也就意味着所有顶点都已经被访问过了。
基础数据结构队列可以很好地胜任盒子的角色,我们甚至不必创建两个队列,队列先进先出的性质,保证了后访问的顶点后被处理,这样一来只需创建一个队列,当该队列为空时,即可结束搜索。
经此优化后我们甚至可以直接抛弃标记数组,因为队列已经实质上起到了标记的作用。
BFS模板:
1 template <typename Tv, typename Te> //广度优先搜索BFS算法(全图) 2 void Graph<Tv, Te>::bfs ( int s ) { //assert: 0 <= s < n 3 reset(); int clock = 0; int v = s; //初始化 4 do //逐一检查所有顶点 5 if ( UNDISCOVERED == status ( v ) ) //一旦遇到尚未发现的顶点 6 BFS ( v, clock ); //即从该顶点出发启动一次BFS 7 while ( s != ( v = ( ++v % n ) ) ); //按序号检查,故不漏不重 8 } 9 10 template <typename Tv, typename Te> //广度优先搜索BFS算法(单个连通域) 11 void Graph<Tv, Te>::BFS ( int v, int& clock ) { //assert: 0 <= v < n 12 Queue<int> Q; //引入辅助队列 13 status ( v ) = DISCOVERED; Q.enqueue ( v ); //初始化起点 14 while ( !Q.empty() ) { //在Q变空之前,不断 15 int v = Q.dequeue(); dTime ( v ) = ++clock; //取出队首顶点v 16 for ( int u = firstNbr ( v ); -1 < u; u = nextNbr ( v, u ) ) //枚举v的所有邻居u 17 if ( UNDISCOVERED == status ( u ) ) { //若u尚未被发现,则 18 status ( u ) = DISCOVERED; Q.enqueue ( u ); //发现该顶点 19 type ( v, u ) = TREE; parent ( u ) = v; //引入树边拓展支撑树 20 } else { //若u已被发现,或者甚至已访问完毕,则 21 type ( v, u ) = CROSS; //将(v, u)归类于跨边 22 } 23 status ( v ) = VISITED; //至此,当前顶点访问完毕 24 } 25 }
BFS例题:HHUOJ 1060
AC代码:

1 #include<iostream> 2 #include<queue> 3 #include<string.h> 4 #include<stdio.h> 5 6 using namespace std; 7 8 char a[105][105]; 9 int dp[105][105]; 10 11 int dir[4][2] = { -1,0,1,0,0,1,0,-1 }; 12 13 struct Point 14 { 15 int x; 16 int y; 17 }; 18 Point temp1, temp2; 19 queue<Point> Q; 20 21 int main() 22 { 23 24 int n,m; 25 cin >> n>>m; 26 int sx, sy; 27 int ex[100], ey[100]; 28 for (int i = 0; i < n; i++) 29 { 30 for (int j = 0; j < m ; j++) 31 dp[i][j] = 0; 32 } 33 for (int i = 0; i < n; i++) 34 { 35 for (int t = 0; t < m; t++) 36 cin >> a[i][t]; 37 } 38 int t = 0; 39 for (int i = 0; i < n; i++) 40 { 41 for (int j = 0; j < m; j++) 42 { 43 if (a[i][j] == ‘K‘) 44 { 45 sx = i; 46 sy = j; 47 } 48 else if (a[i][j] == ‘U‘) 49 { 50 ex[t] = i; 51 ey[t] = j; 52 t++; 53 } 54 } 55 } 56 while (!Q.empty()) 57 Q.pop(); 58 dp[sx][sy] = 1; 59 temp1.x = sx; 60 temp1.y = sy; 61 Q.push(temp1); 62 int flag = 0; 63 int p; 64 while (!Q.empty()) 65 { 66 temp1 = Q.front(); 67 Q.pop(); 68 for (int i = 0; i < 4; i++) 69 { 70 temp2.x = temp1.x + dir[i][0]; 71 temp2.y = temp1.y + dir[i][1]; 72 if (temp2.x >= 0 && temp2.y >= 0 && temp2.x < n && temp2.y < n && !dp[temp2.x][temp2.y] && a[temp2.x][temp2.y] != ‘X‘) 73 { 74 dp[temp2.x][temp2.y] = dp[temp1.x][temp1.y] + 1; 75 Q.push(temp2); 76 } 77 } 78 79 for (p = 0; p < t; p++) 80 { 81 if (dp[ex[p]][ey[p]] != 0) 82 { 83 flag = 1; 84 break; 85 } 86 else 87 continue; 88 } 89 if (flag == 1) 90 break; 91 } 92 if (flag) 93 { 94 cout << "Dangerous" << endl; 95 } 96 else 97 cout << "Safe" << endl; 98 return 0; 99 }
赋权图最短路问题:从无权图转到有权图后问题变得困难了,因为从s到同一个顶点的所有路径中,由于各边的权值不同,经历的边数最少的路径并不一定就是最短的路径。
在BFS算法中,我们很放心地不再去检查已经访问过的顶点,这是因为上一层搜索得到的路径一定短于这次(试想间隔相同的公交站台,坐1站的路程必定要少于坐2站)。而对于有权图,我们并不能放心的得到这个结论(当公交站之间的间隔不同,很有可能坐1站经历的路程就已经比坐3站长了)。因此,对于每一层搜索,我们不仅要查找新的邻接点,还要将已经访问过的顶点到出发点s的路径长拿出来进行比较、更新,这就是Dijkstra算法的大致思路。
Dijkstra算法:Dijkstra是对BFS的扩展,思想与BFS相类似。
以下图为例,选取v1为出发点。
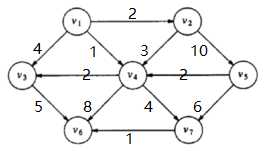
首先设置一个数组dv记录相应顶点当前已经得到的最短路径。
搜索开始时:
| v | v1 | v2 | v3 | v4 | v5 | v6 | v7 |
| 是否已知 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| dv | 0 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ |
从v1出发找到其邻接点,v2,3,4,由于它们现在的dv值均为无穷大,所以此时得到的路径长度一定小于无穷,更新它们的dv值:
| v | v1 | v2 | v3 | v4 | v5 | v6 | v7 |
| 是否已知 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| dv | 0 | ∞->2 | ∞->4 | ∞->1 | ∞ | ∞ | ∞ |
然后从尚未知的顶点中选取dv最小的点,即v4找到其邻接点v3,6,7,将v4置为已知,处理点3,6,7,发现从s到顶点v3经过v4的路径长度3<不经过v4的路径长度4,更新其长度:
| v | v1 | v2 | v3 | v4 | v5 | v6 | v7 |
| 是否已知 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| dv | 0 | 2 | 4->3 | 1 | ∞ | ∞->9 | ∞->5 |
重复这一过程知道所有顶点都为已知:
| v | v1 | v2 | v3 | v4 | v5 | v6 | v7 |
| 是否已知 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| dv | 0 | 2 | 3 | 1 | 12 | 6 | 5 |
Dijkstra算法结束。
复杂度分析:每一层扫描都将花费O(| V |)的时间寻找最小的dv值,因此整体将花费O(| V |2)的时间,对于稠密图,这将是最优解,而对于稀疏图,其效率将比较糟糕。
对于稀疏图的优化将用到配对堆,暂且按下不表。
负边值图:在Dijkstra算法中我们将dv初始化为无穷,以保证其值能得到更新。而当负边值出现,这一办法显然行不通了。
相对应的解决办法就是Floyd算法,此处暂且不表。
生成树(spanning tree):连通图G中覆盖所有顶点的无环连通子图,称为支撑树或生成树。
可以这样理解,把连通图中的某些边去掉,在保持其连通性的前提下使其变成无环图。
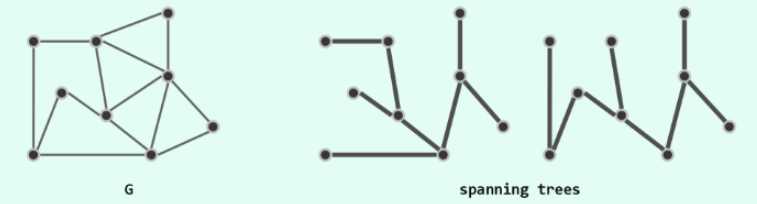
最小生成树(最小权重生成树,minimum spanning tree,MST):所有生成树中权重和最小的树,可能不唯一。
可以与上面同样的思路来理解,尽可能地去掉权重较大的边,在保持其连通性的前提下使其变成无环图。
Prim算法:本质是贪心算法。
从权值最小的边关联的顶点开始,每次都在和已知顶点有关联的顶点中选择权值最小的边关联的顶点,会成环的情况舍去。
例题:POJ 1258
Kruskal算法:Kruskal算法的本质依旧是贪心算法,不过其贪心的策略较Prim算法有所不同。
在Prim算法中,每次在与已知点有关联的点中选取权值最小的边,全过程中只有一棵不断扩展的树。
而Kruskal算法则采用了森林策略,每次都在全局范围内选取权值最小的边,它们不一定连续,因此在局部形成多个生成树,成为所谓的森林,最后合并称为整体的最小生成树。
借助堆操作。按下不表。
正如广度优先搜索对应于树的层序遍历,深度优先搜索则对应于树的前序遍历。
整体思想是选取一个顶点,访问它然后递归地访问与其邻接的点。图形中表现为不断深入,故称其为深度优先搜索。
深度优先搜索由递归实现,类似回溯法,代码非常简洁。
DFS模板(伪代码):
1 void DFS(Vertex V) 2 { 3 Visited[V]=True; 4 for each W adjacent to virtual 5 if(!visited[W]) 6 DFS(W); 7 }
DFS例题:LeetCode 46
标签:设置 acm 算法优化 相对 order namespace 连续 dia 邻接
原文地址:https://www.cnblogs.com/CofJus/p/10547032.html
