标签:buffer 代码 ons pen robot read urllib soup txt
urllib是python内置的HTTP请求库
包括以下模块
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
关于urllib.request.urlopen参数的介绍:
urllib.request.urlopen(url, data=None, [timeout ])
import requests import urllib.request response = urllib.request.urlopen(‘http://www.baidu.com‘) html = response.read(); html.decode(‘utf-8‘); print(html)
#打印输出百度
在某些网络情况不好或者服务器端异常的情况会出现请求慢的情况,或者请求异常,所以这个时候我们需要给
请求设置一个超时时间,而不是让程序一直在等待结果。例子如下:
import urllib.request response = urllib.request.urlopen(‘http://httpbin.org/get‘, timeout=1) print(response.read())
#如果时间超出,则停止
下面来进行小练习
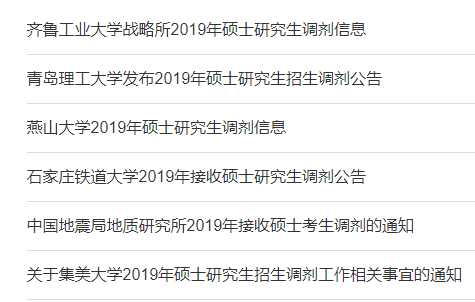
爬取研招网所需信息
分析该页面的HTML结构,找到所需信息的位置
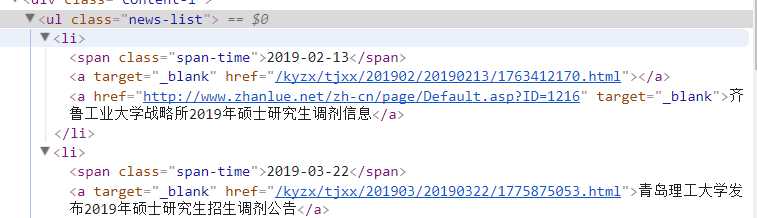
编写代码
import requests
from bs4 import BeautifulSoup
import urllib.request;
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘UTF-8‘)
requesturl=‘https://yz.chsi.com.cn/kyzx/tjxx/‘;
response=urllib.request.urlopen(requesturl);
html=response.read();#read进行乱码处理
doc=BeautifulSoup(html,"xml");
for item in range(51):
pcxt = doc.find(‘ul‘,{‘class‘:‘news-list‘}).findAll(‘a‘)[item].text;
print(pcxt);
#打印输出
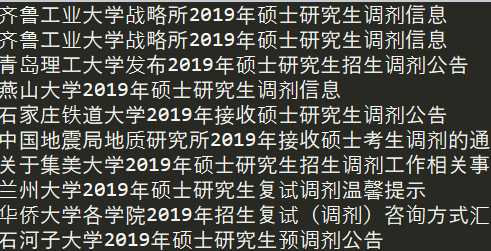
优化代码将加载页面进行封装
import requests from bs4 import BeautifulSoup import urllib.request; import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘UTF-8‘) def open_url(url): requesturl = url; response = urllib.request.urlopen(requesturl); html = response.read();#read进行乱码处理 doc = BeautifulSoup(html,"xml"); return doc doc = open_url(‘https://yz.chsi.com.cn/kyzx/tjxx/‘); for item in range(51): print(doc.find(‘ul‘,{‘class‘:‘news-list‘}).findAll(‘a‘)[item].text);
输出与上图一致
标签:buffer 代码 ons pen robot read urllib soup txt
原文地址:https://www.cnblogs.com/Crush999/p/11877064.html