标签:电商 cat 模型训练 技术 ceil 直接 one 随机数 dea
投资机构或电商企业等积累的客户交易数据繁杂。需要根据用户的以往消费记录分析出不同用户群体的特征与价值,再针对不同群体提供不同的营销策略。
用户分析指标
根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有三个神奇的要素,这三个要素构成了数据分析最好的指标
R-最近一次消费(Recency)
F-消费频率(Frequency)
M-消费金额(Monetary)
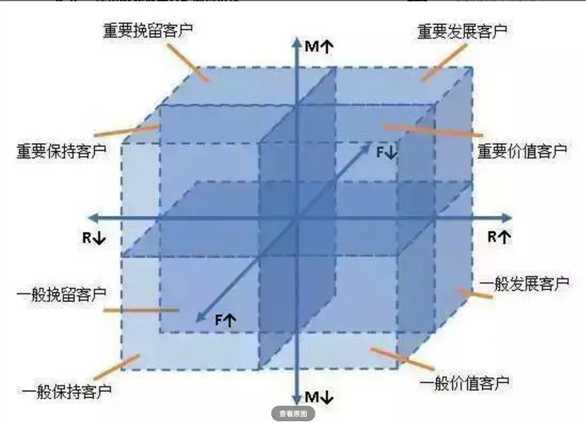
通过该图将用户进行分类:
R、F、M都很高,重要价值客户(VIP客户)
F、M很高,R不高,重要保持客户
R、F、M都很低,流失客户
M很高,R、F不高,重要挽留客户
根据这8个类别的R、F、M指标,对用户进行标注,哪些是重要价值客户,哪些是重要保持客户,哪些是重要发展客户,哪些是流失客户等
流程介绍
以R、F、M这三个核心指标为维度进行聚类分析
利用K-means聚类分析将用户分类
根据R、F、M指标,对用户进行标注
准备工作:
数据:
某电商企业客户近期购买的数据。包含客户注册日期,最后购买日期以及购买消费总金额
参数:
R-求出最近一次投资时间距提数日天数
F-月均投资次数
M-月均投资金额
目标:分析客户交易数据,用户群体的特征与价值,进行精准营销,降低营销成本,提高销售业绩。
1 分析数据获取RFM
R-求出最近一次投资时间距提数日天数
确定一个提现日,减去用户的最新投资日期
F-月均投资次数
总投资次数/总月数
M-月均投资金额
投资总金额/总月数
处理数据获取R-F-M
def dataChange(data):
deadline_time = datetime(2016,7,20)
print(deadline_time)
# 时间相减 得到天数查 timedelta64类型
diff_R = deadline_time - data["最近一次投资时间"]
# 渠道具体天数
# days = diff_R[0].days
R = []
for i in diff_R:
days = i.days
R.append(days)
print(R)
‘‘‘
用户在投时长(月
Python没有直接获取月数差的函数
1、获取用户在投天数
2、月=在投天数/30,向上取整
‘‘‘
diff = deadline_time - data["首次投资时间"]
print(diff)
# 利用向上取整函数
months = []
for i in diff:
month = ceil(i.days/30)
months.append(month)
print(months)
# 月均投资次数
month_ave = data["总计投标总次数"]/months
F = month_ave.values
print(F)
# 月均投资金额
M = (data["总计投资总金额"]/months).values
print(M)
return R, M, F
2 训练KMeans模型
先对数据进行转换,然后通过K—Means模型训练,生产模型
def analy_data(data, R, M, F):
cdata = DataFrame([R, list(F), list(M)]).T
# 指定cdata的index和colums
cdata.index = data.index
cdata.columns = ["R-最近一次投资时间距提数日的天数", "F-月均投资次数", "月均投资金额"]
print("cdata_info:\n", cdata)
print("cdata:\n", cdata.describe())
# K-Means聚类分析
# 01 数据标准化 均值:cdata.mean() 标准差:cdata.std()
# 对应位置分别先相减 再相除
zcdata = (cdata-cdata.mean())/cdata.std()
print("zcdata:\n", zcdata)
# n_clusters:分类种数 n_jobs:计算的分配资源 max_iter:最大迭代次数 random_state:随机数种子,种子相同,参数固定
kModel = KMeans(n_clusters=4, n_jobs=4, max_iter=100, random_state=0)
kModel.fit(zcdata)
print(kModel.labels_)
3 通过模型对用户标注
# 统计每个类别的频率
value_counts = Series(kModel.labels_).value_counts()
print(value_counts)
# 将类别标签赋回原来的数据
cdata_rst = pd.concat([cdata, Series(kModel.labels_, index=cdata.index)], axis=1)
print(cdata_rst)
# 命名最后一列为类别
cdata_rst.columns = list(cdata.columns) + ["类别"]
print(cdata_rst)
# 按照类别分组统计R, F, M的指标均值
user_ret = cdata_rst.groupby(cdata_rst["类别"]).mean()
print(user_ret)
‘‘‘
R-最近一次投资时间距提数日的天数 F-月均投资次数 月均投资金额
类别
0 27.859375 2.820312 21906.754297
1 20.684211 4.552632 115842.105263
2 10.568182 5.579545 26984.313636
3 12.111111 17.277778 107986.000000
结论:
类别3:R、F、M都比较高,属于重要价值客户 或 超级用户
类别0:R、F、M都比较低,属于低价值客户
类别1:R一般、F一般、M很高,也属于重要价值客户
‘‘‘
通过模型对新用户标注
1、获取新用户数据
2、通过和原数据处理获取RFM
3、通过训练模型得出用户类型
def user_classes(cdata, user_info):
‘‘‘
# 模拟一条用户数据
1、获取当前时间表示为截止时间
2.计算出: R F M
‘‘‘
R, M, F = user_info_change(user_info)
user_data_info = DataFrame([[R], [F], [M]]).T
print(user_data_info)
# user_data_info = DataFrame([[12.5], [18.0], [20000.0]]).T
user_data_info.index = ["lily"]
user_data_info.columns = cdata.columns
print("cdata_info:\n", user_data_info)
new_zcdata = (user_data_info-cdata.mean())/cdata.std()
print("new_zcdata", new_zcdata)
kModel = load_model("user_classes.pkl")
ret = kModel.predict(new_zcdata)
print("new_zcdata_ret:", ret)
# new_zcdata_ret: [3]

标签:电商 cat 模型训练 技术 ceil 直接 one 随机数 dea
原文地址:https://www.cnblogs.com/blogs/p/12003145.html