标签:col 事务隔离 排行榜 操作 方法 日期 sql语句 归档 div
0、MySQL数据怎么存储数据?怎么高数查询数据?怎么实现事务的ACID?实际使用涉及哪些数据结构和算法,MySQL和redis的区别是什么?
0、1数据库管理系统(DBMS-Database Management System)使用数据引擎进行创建、查询、更新和删除数据。一个数据库可以使用多个数据引擎以满足各种性能和实际需求。
0、1、1、InnoDB引擎创建一个表,在硬盘上会生成.frm.idb结尾的两个文件。索引和数据在以.db结尾的文件中。InnoDB存储引擎在存储数据的时候,默认按照b+树形结构存储数据。如果以主键作为b+树结构的数据项则为聚集索引!
0、1、2、MyISAM存储引擎创建一个表,在硬盘上生成以.frm.MYD.MYI结尾的三个文件。frm结尾的是表结构(存什么字段什么类型),MYD结尾的是数据文件,MYI结尾的就是索引文件,所以索引也是存在硬盘上的。
0、1、3、MEMORY存储引擎,将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。
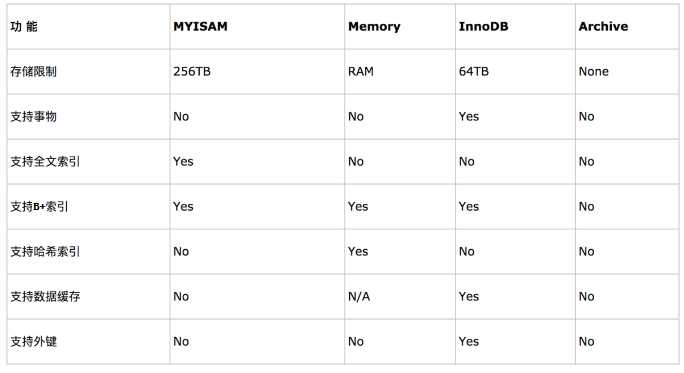
注:如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择;如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率;如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果;如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive;
1、关系型数据库:建立在关系模型(一对一、一对多、多对多等)基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据库
2、非关系型模型比如有:列模型:Hbase; 键值对模型:redis,MemcacheDB;文档类模型:mongoDB
3、关系型数据库通过外键关联来建立表与表之间的关系,非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
4、关系模型包括:数据结构(数据存储的问题,二维表)、操作指令集合(SQL语句)、完整性约束(表内数据约束、表与表之间的约束)
5、数据类型:整型、浮点型、十进制、字符串、日期时间、枚举(ENUM)、集合(SET)
6、数据库应用的开发使用的4个类:connection(连接)、statement(发送数据库操作指令)、resultset(传输在线数据)、dataset(传输离线数据)
7、SQL(Structured Query Language)、结构化查询语言。
8、
1、关系型数据库管理系统(RDBMS-Relational Database Management System):
2、MySQL数据库数据存放在硬盘当中,每次访问数据库时,都存在I/O操作。如果访问数据库次数频繁,反复连接数据库导致运行效率过慢。
3、MySQL和redis的使用场景:redis、排行榜、计数器、消息队列推送、好友关注、粉丝等访问数据频繁的场景。
预备知识:
1、MySQL有哪些索引方式,这些方法的优缺点及其原因。优化查询需要考虑哪些问题。如何确定索引是否生效。
2、添加数量合适而且有效的索引才能提高程序的性能和数据库的查询效率
3、索引会加快查询效率但是会降低写入的效率
4、复杂度模型(搜索树的平均复杂度是lgN),但是是基于每次相同的操作成本来考虑的,然而MySQL数据库访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景
5、磁盘的读取每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分。
索引提高查询效率的过程:
1、索引,MySQL中的key:primary key、unique key、index key,是一种存储引擎用于快速找到记录的一种数据结构。MySQL主要有两种索引数据结构:Hash索引、B+Tree索引。
2、数据库查询:等值查询、范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)、
3、多列联合索引(最左前缀匹配原则)、聚集索引(主键索引)、非聚集索引(非主键索引)、覆盖索引
4、where条件的字段
5、每个版本的MySQL对查询做了哪些优化,如:索引下推
6、explain查询
7、查询优化器:一条SQL语句的查询,可以有不同的执行方案,至于选择哪种方案,需要通过优化器来选择,选择执行成本最低的方案。查询优化器的优化过程:1、根据索引条件,找出所有可能使用的索引>>2、计算全表扫描的代价>>3、计算不同索引执行方案的代价>>4、对比各种执行方案的代价,找出成本最低的那个方案。
8、b+树索引:一次I/O操作读取的数据是一页;b+树叶子节点表示一个磁盘块也就是一页,存储数据项;b+树非叶子节点只存储指引搜索方向的数据项,不存储真实的数据;b+树的高度h=㏒(m+1)N(m=页面大小/数据项的大小、N为数据表的数据)。
8.1、索引字段要尽量的小:通过上面的分析,我们知道IO次数取决于b+数的高度h或者说层级,这个高度或者层级就是你每次查询数据的IO次数,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
8.2、索引的最左匹配特性:当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
8.3B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index):不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息。
标签:col 事务隔离 排行榜 操作 方法 日期 sql语句 归档 div
原文地址:https://www.cnblogs.com/yinminbo/p/11780651.html