标签:out rust 删除 roo 目录 star gcc-c++ 工作 要求
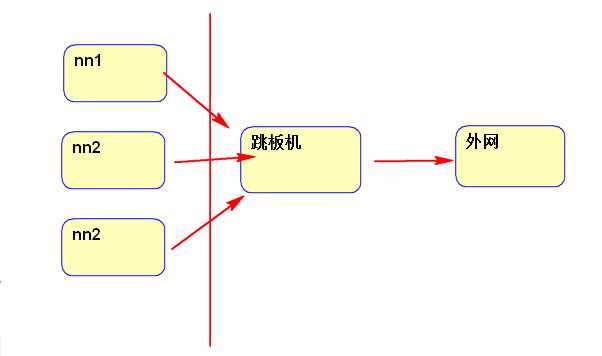
1)安装sz rz工具,用于以后用rz sz上传下载文件
yum install -y lrzsz
cp Centos-7.repo /etc/yum.repos.d/ cd /etc/yum.repos.d/ mv CentOS-Base.repo CentOS-Base.repo.bak mv Centos-7.repo CentOS-Base.repo
5)执行yum源更新命令
yum clean all
#服务器的包信息下载到本地电脑缓存起来
yum makecache
yum update -y
配置完毕。
yum install -y openssh-server vim gcc gcc-c++ glibc-headers bzip2-devel lzo-devel curl wget openssh-clients zlib-devel autoconf automake cmake libtool openssl-devel fuse-devel snappy-devel telnet unzip zip net-tools.x86_64 firewalld systemd ntp

安装软件之前要 重启服务器
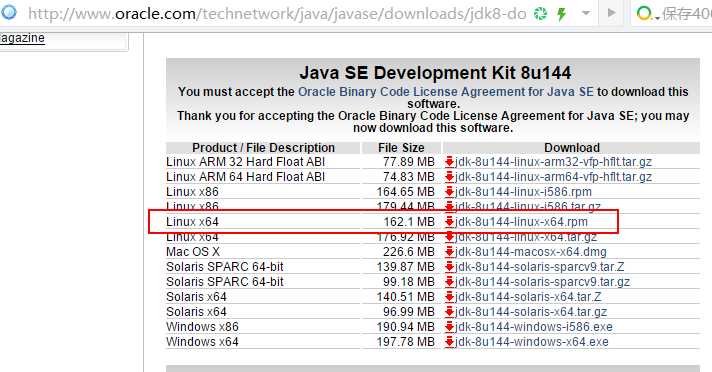
由于是rmp格式文件可以直接安装
rpm -ivh jdk-8u144-linux-x64.rpm
-ivh:安装时显示安装进度
export JAVA_HOME=/usr/java/jdk1.8.0_144 export JRE_HOME=$JAVA_HOME/jre export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#使修改生效 source /etc/profile #查看系统变量值 echo $PATH #检查JDK 配置情况 java -version
#命令: crontab -e 0 * * * * /usr/sbin/ntpdate time1.aliyun.com >> /tmp/autontpdate 2>&1
hostnamectl set-hostname nn1.hadoop #修改完后用hostname可查看当前主机名 // hostname是计算机名 hostname
#创建hadoop用户 useradd hadoop #给hadoop用户设置密码 000000
第一步。# useradd hadoop
#切换到hadoop用户 su – hadoop #创建.ssh目录 mkdir ~/.ssh #生成ssh公私钥 ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ‘‘ #输出公钥文件内容并且重新输入到~/.ssh/authorized_keys文件中 ,必须放置authorized_keys文件中才能被#linux识别,不然被认为是自己的公钥。 cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys #给~/.ssh文件加上700权限 chmod 700 ~/.ssh #给~/.ssh/authorized_keys加上600权限 chmod 600 ~/.ssh/authorized_keys
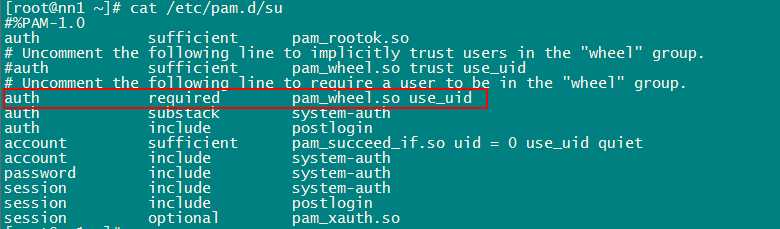
sed -i ‘s/#auth\t\trequired\tpam_wheel.so/auth\t\trequired\tpam_wheel.so/g‘ ‘/etc/pam.d/su‘
sed -i ‘s/要被取代的字串/新的字串/g‘ ‘文件名‘
-i :直接修改读取的文件内容,而不是输出到终端。

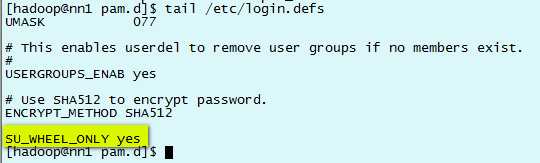
# 把“SU_WHEEL_ONLY yes”字符串追加到/etc/login.defs文件底部 echo "SU_WHEEL_ONLY yes" >> /etc/login.defs
tail /etc/login.defs 从文件底部查看
3) 添加用户到管理员,禁止普通用户su 到 root
#把hadoop用户加到wheel组里 #查看wheel组里是否有hadoop用户


4)用vuser1 用户验证一下,由于vuser1 没有在wheel 组里,所以没有 su - root 权限。

5)修改/etc/pam.d/su文件,将字符串“#auth\t\tsufficient\tpam_wheel.so”替换成“auth\t\tsufficient\tpam_wheel.so”
sed -i ‘s/#auth\t\tsufficient\tpam_wheel.so/auth\t\tsufficient\tpam_wheel.so/g‘ ‘/etc/pam.d/su‘
验证免密码切换到 root 用户

在克隆机器前,配置nn1 机器的 /etc/hosts 文件,文件内需要配置nn1、nn2、s1、s2、s3 所有机器的IP 和 主机名。修改/etc/hosts文件,vim /etc/hosts。追加以下内容,不要把之前的内容删掉。
192.168.142.180 nn1.hadoop 192.168.142.181 nn2.hadoop 192.168.142.182 s1.hadoop 192.168.142.183 s2.hadoop 192.168.142.184 s3.hadoop
执行完上面的命令,一个基础的linux系统就配置好了。然后把这个nn1.hadoop虚拟机导出,再根据这个导出的虚拟机创建4个linux系统。
其中:nn2.hadoop: 从节点
s1.hadoop、s2.hadoop、s3.hadoop:三个工作节点
并用hadoop用户,测试彼此之间是否能进行ssh通信。
右键 nn1 机器→ 管理 → 克隆。
克隆完成后,需要给克隆的虚拟机配置静态IP。
1)查看网卡硬件名称和基本信息
ip add
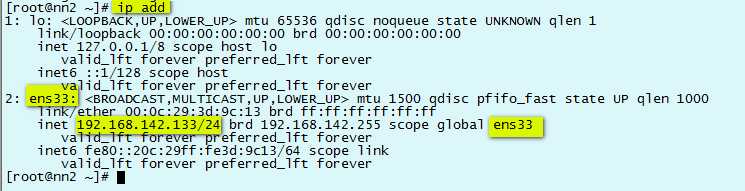
TYPE="Ethernet" BOOTPROTO="static" DEFROUTE="yes" PEERDNS="yes" PEERROUTES="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_PEERDNS="yes" IPV6_PEERROUTES="yes" IPV6_FAILURE_FATAL="no" NAME="ens33" UUID="fbe09adb-60e9-4e66-be20-9104c63a50c2" DEVICE="ens33" ONBOOT="yes" IPADDR=192.168.92.131 PREFIX=24 GATEWAY=192.168.92.2 DNS=192.168.92.2
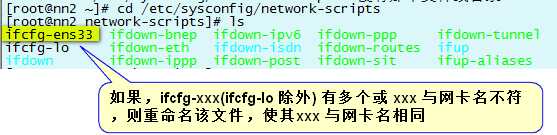
需要修改的内容,配置完的网卡文件

配置完后,用systemctl restart network.service重启网络服务,当前的ssh就连接不上了,是因为网络IP被改变成你自己设置的静态IP。
用 ip add 查看网卡信息
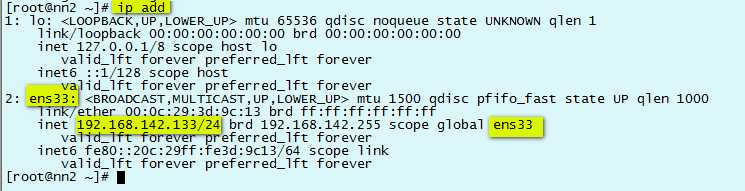

hostnamectl set-hostname nn2.hadoop hostnamectl set-hostname s1.hadoop hostnamectl set-hostname s2.hadoop hostnamectl set-hostname s3.hadoop
标签:out rust 删除 roo 目录 star gcc-c++ 工作 要求
原文地址:https://www.cnblogs.com/yoyowin/p/12008773.html