|
Read from both copies
|
Read from primary copy only
| ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
|
如果我们允许从主副本和次副本读取,那么每个节点都必须缓存A和b的内容。假设每个节点有32GB的缓存,那么系统的总有效缓存为32GB。 |
通过将读取限制为主副本,我们使节点1只负责A,节点2只负责B。假设每个节点有32GB的缓存,那么总的有效缓存占用空间将是64GB,或者是相反模型的两倍。 |
标签:没有 顺序检索 请求 难题 evel 位置 ocs sha 索引
分布式数据库系统可分为两大类数据存储架构:(1)共享磁盘和(2)无共享。
|
Shared Disk Architecture
|
Shared Nothing Architecture
|
|---|---|
 |
 |
共享磁盘方法在协调对单个中心资源的访问时受到几个固有的体系结构限制。在这样的系统中,随着集群中节点数量的增加,协调开销也随之增加。虽然一些工作负载可以通过共享磁盘很好地扩展(例如,由大量读操作控制的小型工作集),但是大多数工作负载的扩展能力都很差——尤其是具有大量写负载的工作负载。
ClustrixDB使用无共享的方法,因为它是唯一已知的允许大规模分布式系统的方法。
为了构建一个可伸缩的无共享数据库系统,必须解决两个基本问题:
本文档解释了ClustrixDB如何将数据集分布到大量独立节点上,并提供了一些架构决策背后的推理。
在无共享架构中,大多数数据库可分为以下几类:
ClustrixDB对数据分发有一种细粒度的方法。下表总结了系统使用的基本概念和术语。请注意,与许多其他系统不同,ClustrixDB使用每个索引的分发策略。
分布的概念概述
|
ClustrixDB分布的概念 | |
|---|---|
| Representation |
每个表包含一个或多个索引。在内部,ClustrixDB将这些索引作为表的表示。每个表示都有自己的分布键(也称为分区键或碎片键),这意味着ClustrixDB使用多个独立键来分割一个表中的数据。这与大多数其他分布式数据库系统形成了对比,后者使用单个键来分割一个表中的数据。 每个表必须有一个主键。如果用户没有定义主键,ClustrixDB将自动创建一个隐藏的主键。基本表示包含表中的所有列,按主键排序。非基表示包含表中列的一个子集。 |
| Slice |
ClustrixDB使用一致的散列将每个表示分解为逻辑片的集合。 通过使用一致的哈希,ClustrixDB可以分割单个片,而不必重新哈希整个表示。 |
| Replica |
ClustrixDB为容错和可用性维护多个数据副本。每个逻辑片至少有两个物理副本,存储在不同的节点上。 ClustrixDB支持配置每个表示的副本数量。例如,一个用户可能需要三个副本作为表的基本表示,而只需要两个副本作为表的其他表示。 |
概念的例子:
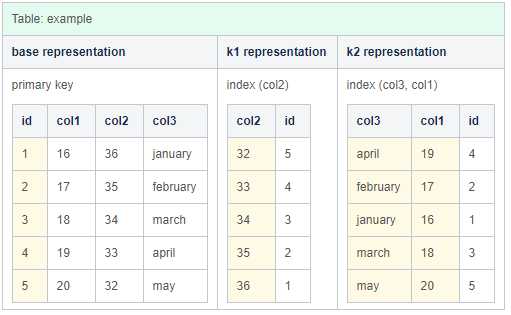
sql> CREATE TABLE example ( id bigint primary key, col1 integer, col2 integer, col3 varchar(64), key k1 (col2), key k2 (col3, col1) );
我们用以下数据填充我们的表:
| Table: example | |||
| id | col1 | col2 | col3 |
|---|---|---|---|
| 1 | 16 | 36 | january |
| 2 | 17 | 35 | february |
| 3 | 18 | 34 | march |
| 4 | 19 | 33 | april |
| 5 | 20 | 32 | may |
Representation
ClustrixDB将上述模式组织成三种表示形式。一个用于主表(由主键组织的基本表示),然后是另外两个表示,每个表示由索引键组织。
下图中的黄色显示了每种表示的排序键。注意,辅助索引的表示包括主键列。
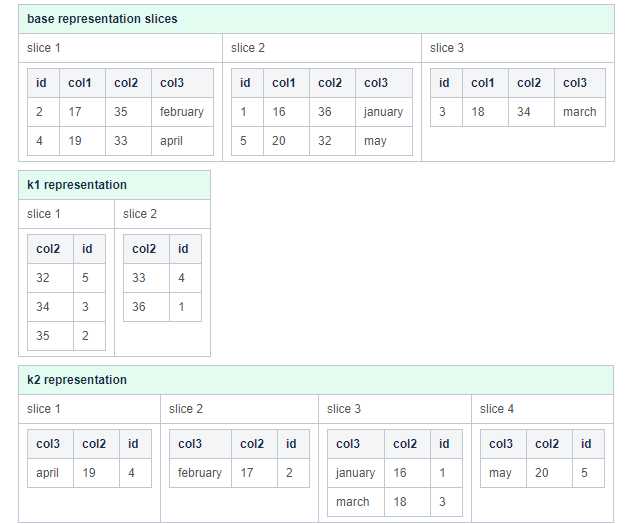
Slice
ClustrixDB将把每个表示分割成一个或多个逻辑片。当对ClustrixDB进行切片时,使用以下规则:
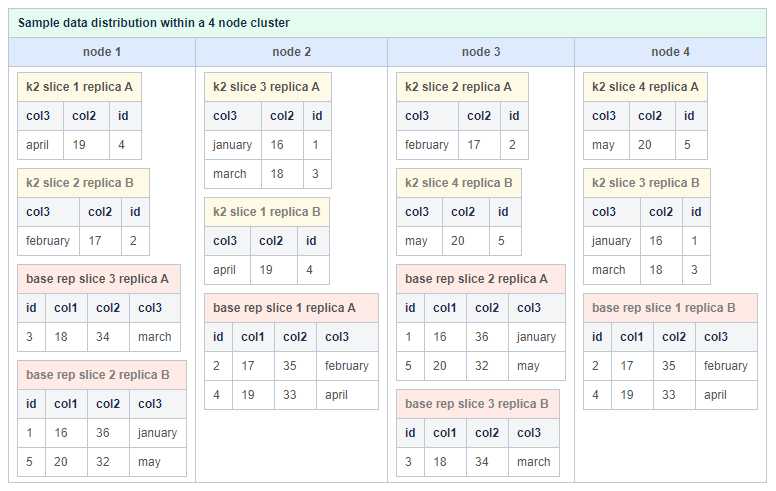
Replica
为了确保容错和可用性,ClustrixDB包含多个数据副本。ClustrixDB使用以下规则在集群中放置副本(片的副本):
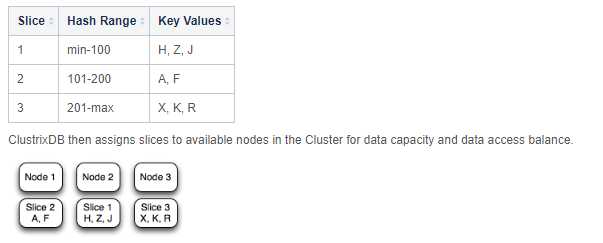
一致性哈希
ClustrixDB对数据分布使用一致的哈希。一致的哈希允许ClustrixDB动态地重新分发数据,而不必重新哈希整个数据集。
切片
ClustrixDB将每个分布键散列到64位数字。然后我们把空间分成范围。然后,每个范围由一个特定的片拥有。下表说明了一致哈希如何将特定键分配给特定的片。
随着数据集的增长,ClustrixDB将自动并递增地重新切片数据集,每次一个或多个切片。目前,我们的重新切片阈值是基于数据集大小的。如果一个片超过了最大大小,系统将自动将其分成两个或更多的小片。
例如,假设我们的一个切片超出了预先设置的阈值:

很容易看出为什么表级分发提供非常有限的可伸缩性。设想一个由一个或两个非常大的表(数十亿行)控制的模式。在这种情况下,向系统添加节点没有帮助,因为单个节点必须能够容纳整个表。
为什么ClustrixDB使用独立的索引分布而不是单一键方法?答案是双重的:
让我们检查一个特定的用例来比较和对比这两种方法。想象一个公告板应用程序,其中不同的主题由线程分组,用户可以将其发布到不同的主题中。我们的公告栏服务已经变得很受欢迎,我们现在有数十亿的帖子,数十万的帖子,数百万的用户。
我们还假设公告栏的主要工作负载由以下两种访问模式组成:
我们可以想象一个包含应用程序中所有post的大表,其简化模式如下:
-- Example schema for the posts table. sql> CREATE TABLE thread_posts ( post_id bigint, thread_id bigint, user_id bigint, posted_on timestamp, contents text, primary key (thread_id, post_id), key (user_id, posted_on) ); -- Use case 1: Retrieve all posts for a particular thread in post id order. -- desired access path: primary key (thread_id, post_id) sql> SELECT * FROM thread_posts WHERE thread_id = 314 ORDER BY post_id; -- Use case 2: For a specific user, retrieve the last 10 posts by that user. -- desired access path: key (user_id, posted_on) sql> SELECT * FROM thread_posts WHERE user_id = 546 ORDER BY posted_on desc LIMIT 10;
单一的关键方法
使用单一键方法时,我们面临着一个难题:我们选择哪个键来分发posts表?从下表可以看出,我们不能选择一个键来实现跨两个用例的良好可伸缩性。
|
Distribution Key
|
Use case 1: posts in a thread
|
Use case 2: top 10 posts by user
|
|---|---|---|
| thread_id | 包含thread_id的查询将执行得很好。对特定线程的请求被路由到集群中的单个节点。当线程和帖子的数量增加时,我们只需向集群添加更多的节点来增加容量。 | .不包含thread_id的查询(比如某个特定用户对最近10篇文章的查询)必须对包含thread_posts表的所有节点求值。换句话说,系统必须广播查询请求,因为相关的post可以驻留在任何节点上 |
| user_id | 在广播中不包含user_id的查询。与thread_id密钥示例(用例2)一样,在必须进行广播时,我们会失去系统的可伸缩性。 | 包含user_id的查询被路由到单个节点。每个节点将包含一个用户的一组有序的帖子。该系统可以通过避免广播来扩展。 |
使用这种系统的一种可能性是维护一个单独的表,其中包括user_id和posted_on列。然后,我们可以让应用程序手动维护这个索引表。
然而,这意味着应用程序现在必须发出多个写操作,并承担两个表之间数据一致性的责任。想象一下,如果我们需要添加更多的索引?这种方法根本无法推广。数据库的优点之一是自动索引管理。
独立索引键方法
ClustrixDB将自动创建满足这两个用例的独立发行版。DBA可以通过thread_id指定分发基本表示(主键),通过user_id指定分发辅助键。系统将自动管理具有完整ACID保证的表和二级索引。
有关更详细的解释,请参阅我们的评估模型部分。
与其他使用主从对进行数据容错的系统不同,ClustrixDB以更细粒度的方式分布数据,如前面几节所述。我们的方法允许ClustrixDB通过不向次副本发送读操作来提高缓存效率。
考虑下面的例子。假设一个由2个节点和2个片a和B组成的集群,其中有二级副本a ‘和B‘。
|
Read from both copies
|
Read from primary copy only
| ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
|
如果我们允许从主副本和次副本读取,那么每个节点都必须缓存A和b的内容。假设每个节点有32GB的缓存,那么系统的总有效缓存为32GB。 |
通过将读取限制为主副本,我们使节点1只负责A,节点2只负责B。假设每个节点有32GB的缓存,那么总的有效缓存占用空间将是64GB,或者是相反模型的两倍。 |
标签:没有 顺序检索 请求 难题 evel 位置 ocs sha 索引
原文地址:https://www.cnblogs.com/yuxiaohao/p/12010049.html