标签:xhtml ret 处理 程序设计 类型 创建文件 访问 encoding format

页码在page=后面。
2.Htmls页面解析

我们想要的信息在script中,使用BeautifulSoup库只能爬取到script标签,难以对数据进行精确提取,所以我直接使用正则表达式进行爬取。
3.节点(标签)查找方法与遍历方法1 import requests 2 import os 3 import re 4 5 6 7 #爬取页面 8 def getHTMLText(url): 9 try: 10 #假装成浏览器访问 11 kv = {‘Cookie‘:‘SINAGLOBAL=4844987765259.994.1544506324942; 12 SUB=_2AkMqmKIaf8NxqwJRmPoVxWnmaIV-ygDEieKcxFPBJRMxHRl-yT9jqmc8tRB6ARiM9rPSLjsy2kCgBq61u7x2M9eTeKTA; 13 SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFYIzVSU-rQ8YIqH5sJ2vs7; 14 login_sid_t=6f2f5ed24c4e1f2de505c160ca489c97; cross_origin_proto=SSL;15 _s_tentry=www.baidu.com; UOR=,,www.baidu.com; Apache=9862472971727.955.1575730782698; 16 ULV=1575730782710:6:1:1:9862472971727.955.1575730782698:1569219490864; 17 YF-Page-G0=b7e3c62ec2c0b957a92ff634c16e7b3f|1575731639|1575731637‘,18 ‘user-agent‘:‘Mozilla/5.0‘,19 ‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3‘} 20 #获取目标页面 21 r = requests.get(url,headers = kv) 22 #判断页面是否链接成功 23 r.raise_for_status() 24 #使用HTML页面内容中分析出的响应内容编码方式 25 #r.encoding = r.apparent_encoding 26 #返回页面内容 27 return r.text 28 except: 29 #如果爬取失败,返回“爬取失败” 30 return "爬取失败" 31 32 #爬取数据 33 def getData(nlist,vlist,html): 34 #爬取新浪热门话题标题 35 flag = re.findall("alt=.{0,3}#.{1,15}#",html) 36 #对标题进行清洗 37 for i in range(len(flag)): 38 nlist.append(flag[i][5:]) 39 #爬取话题浏览量 40 flag = re.findall(‘<span.{0,3}class=.{0,3}number.{0,3}>.{0,8}<.{0,3}span>‘,html) 41 #对浏览量进行清洗 42 for i in range(len(flag)): 43 vlist.append(flag[i][23:-9]) 44 return nlist,vlist 45 46 #打印结果 47 def printList(nlist,vlist,num): 48 for i in range(num): 49 print("````````````````````````````````````````````````````````````````````````````") 50 print("排名:{}".format(i+1)) 51 print("标题:{}".format(nlist[i])) 52 print("阅读量:{}".format(vlist[i])) 53 54 #数据存储 55 def dataSave(nlist,vlist,num): 56 try: 57 #创建文件夹 58 os.mkdir("C:\新浪热门话题") 59 except: 60 #如果文件夹存在则什么也不做 61 "" 62 try: 63 #创建文件用于存储爬取到的数据 64 with open("C:\\新浪热门话题\\新浪热门话题.txt","w") as f: 65 for i in range(num): 66 f.write("````````````````````````````````````````````````````````````````````````````\n") 67 f.write("排名:{}\n".format(i+1)) 68 f.write("标题:{}\n".format(nlist[i])) 69 f.write("阅读量:{}\n".format(vlist[i])) 70 except: 71 "存储失败" 72 73 nlist = [] 74 vlist = [] 75 #新浪热点话题链接 76 url = "https://d.weibo.com/231650?cfs=920&Pl_Discover_Pt6Rank__4_filter=&Pl_Discover_Pt6Rank__4_page=1#Pl_Discover_Pt6Rank__4" 77 #获取HTML页面 78 html = getHTMLText(url) 79 #将数据存在列表中 80 getData(nlist,vlist,html) 81 #打印结果 82 printList(nlist,vlist,15) 83 #存储数据 84 dataSave(nlist,vlist,15)
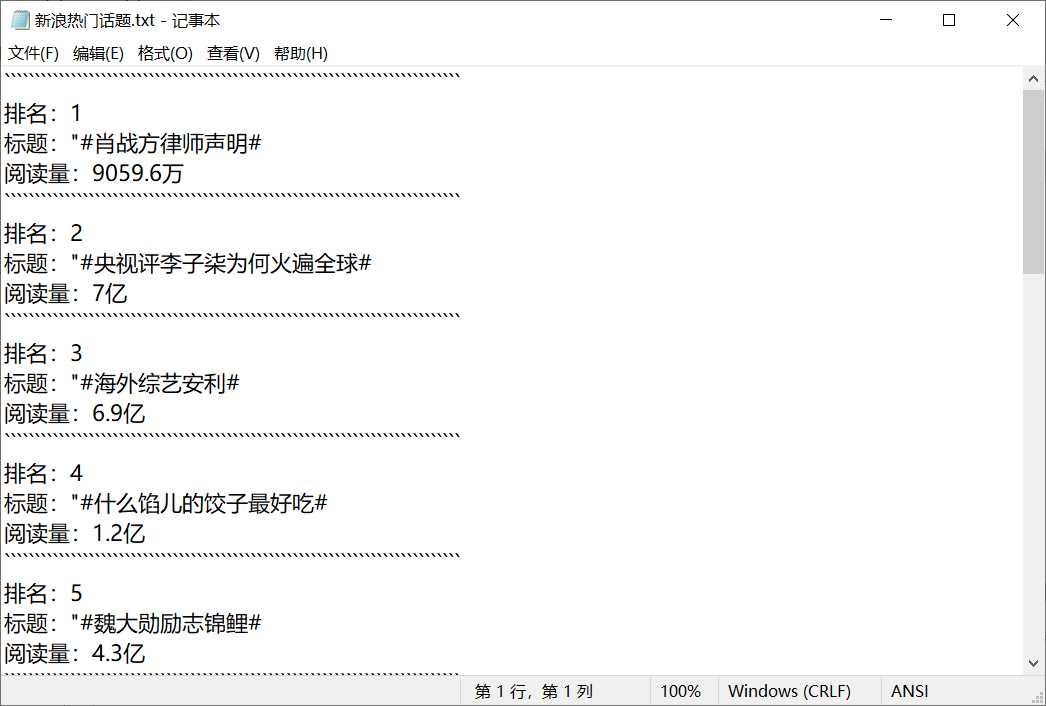
运行结果:


#爬取页面 def getHTMLText(url): try: #假装成浏览器访问 kv = {‘Cookie‘:‘SINAGLOBAL=4844987765259.994.1544506324942; SUB=_2AkMqmKIaf8NxqwJRmPoVxWnmaIV-ygDEieKcxFPBJRMxHRl-yT9jqmc8tRB6ARiM9rPSLjsy2kCgBq61u7x2M9eTeKTA; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFYIzVSU-rQ8YIqH5sJ2vs7; login_sid_t=6f2f5ed24c4e1f2de505c160ca489c97; cross_origin_proto=SSL; _s_tentry=www.baidu.com; UOR=,,www.baidu.com; Apache=9862472971727.955.1575730782698; ULV=1575730782710:6:1:1:9862472971727.955.1575730782698:1569219490864; YF-Page-G0=b7e3c62ec2c0b957a92ff634c16e7b3f|1575731639|1575731637‘, ‘user-agent‘:‘Mozilla/5.0‘, ‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3‘} #获取目标页面 r = requests.get(url,headers = kv) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 #r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败"
#爬取数据 def getData(nlist,vlist,html): #爬取新浪热门话题标题 flag = re.findall("alt=.{0,3}#.{1,15}#",html) #对标题进行清洗 for i in range(len(flag)): nlist.append(flag[i][5:]) #爬取话题浏览量 flag = re.findall(‘<span.{0,3}class=.{0,3}number.{0,3}>.{0,8}<.{0,3}span>‘,html) #对浏览量进行清洗 for i in range(len(flag)): vlist.append(flag[i][23:-9]) return nlist,vlist
#数据存储 def dataSave(nlist,vlist,num): try: #创建文件夹 os.mkdir("C:\新浪热门话题") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\新浪热门话题\\新浪热门话题.txt","w") as f: for i in range(num): f.write("````````````````````````````````````````````````````````````````````````````\n") f.write("排名:{}\n".format(i+1)) f.write("标题:{}\n".format(nlist[i])) f.write("阅读量:{}\n".format(vlist[i])) except: "存储失败"
标签:xhtml ret 处理 程序设计 类型 创建文件 访问 encoding format
原文地址:https://www.cnblogs.com/tyr-1215/p/12019473.html