标签:导致 映射 osi 子集合 embedding clust cluster ring 网络
在文本语义相似度等句子对的回归任务上,BERT , RoBERTa 拿到sota。
但是,它要求两个句子都被输入到网络中,从而导致巨大开销:从10000个句子集合中找到最相似的sentence-pair需要进行大约5000万个推理计算(约65小时)。
BERT不适合语义相似度搜索,也不适合非监督任务,比如聚类。
解决聚类和语义搜索的一种常见方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。
于是,也有人尝试向BERT输入单句,得到固定大小的sentene embedding。最常用的方法是,平均BERT输出层或使用第一个token([CLS]的token)的输出。但这却产生了非常不好的sentence embedding,常常还不如averaging GloVe embeddings。
本文提出:Sentence-BERT(SBERT),对预训练的BERT进行修改:使用Siamese和三级(triplet)网络结构来获得语义上有意义的句子embedding->可以生成定长的sentence embedding,使用余弦相似度或Manhatten/Euclidean距离等进行比较找到语义相似的句子。
SBERT保证准确性的同时,可将上述提到的BERT/RoBERTa的65小时减少到5s。(计算余弦相似度大概0.01s)
除了语义相似度搜索,也可用来clustering搜索。
作者在NLI data中fine-tune SBERT,用时不到20分钟。
pooling策略:
MEAN策略:使用CLS-token的输出,对所有输出向量取mean。
MAX策略:使用CLS-token的输出,对所有输出向量计算max-over-time。
目标函数:
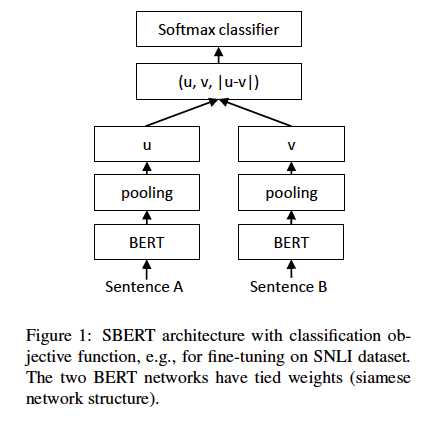
分类:
计算sentence embeedings u 和 v的element-wise差值并乘以权重:
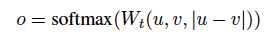
其中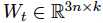 ,n是sentence embedding的纬度,k是label的数量。
,n是sentence embedding的纬度,k是label的数量。
loss:交叉熵
如图1:
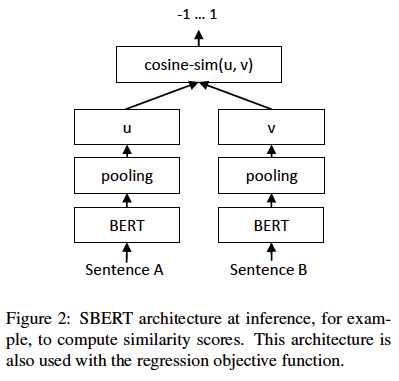
回归:
计算两个sentence embedding(u & v)的余弦相似度。
loss:均方误差
如图2:
Triplet:
输入:anchor sentence a,positive sentence p, negative sentence n
loss的目的是让a和p之间的距离小于a和n之间的距离:
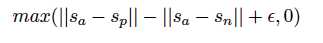
Sa Sp Sn 分别是 a p n 的sentence embedding。|| · || 是距离测度,ε是margin。对于距离测度,可以用Euclidean距离。实验时,作者将ε设置为1。
实验时,作者用3-way softmax分类目标函数fine-tune SBERT了一个epoch。pooling策略为MEAN。
接下来就是一系列的实验结果表格,结论是效果不错。
消融学习:
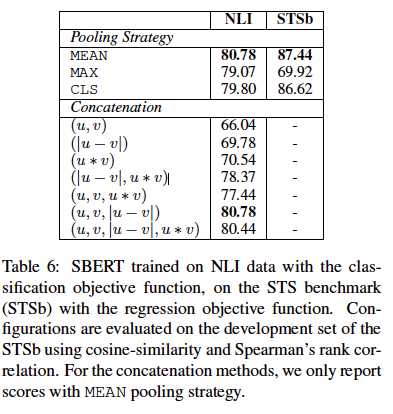
pooling策略影响小,连接方式影响大。
论文阅读 | Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
标签:导致 映射 osi 子集合 embedding clust cluster ring 网络
原文地址:https://www.cnblogs.com/shona/p/12026349.html