标签:str 网页 标题 bar requests int 出图 mil 列表
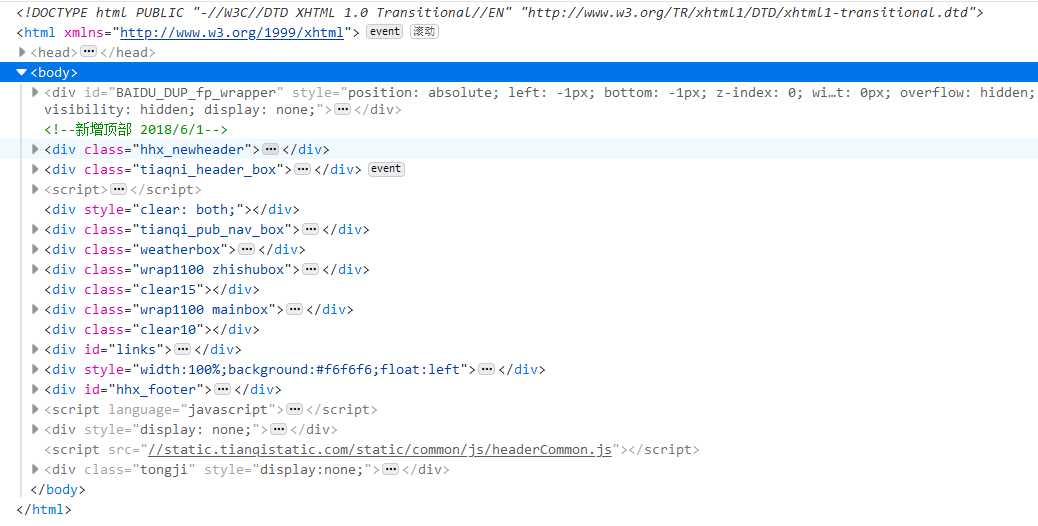
2.Htmls页面解析
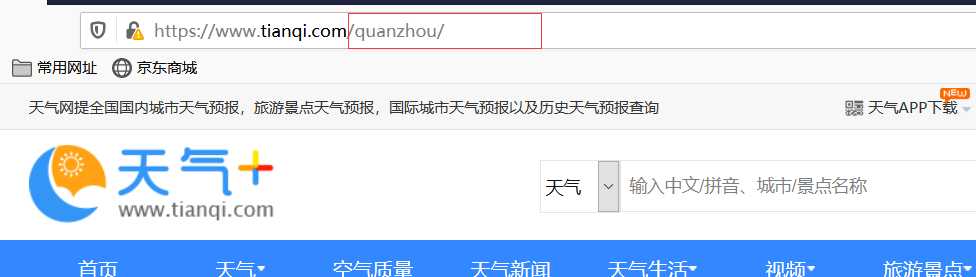
从这个链接中我们可以得到所有城市的信息http://www.tianqi.com/chinacity.html
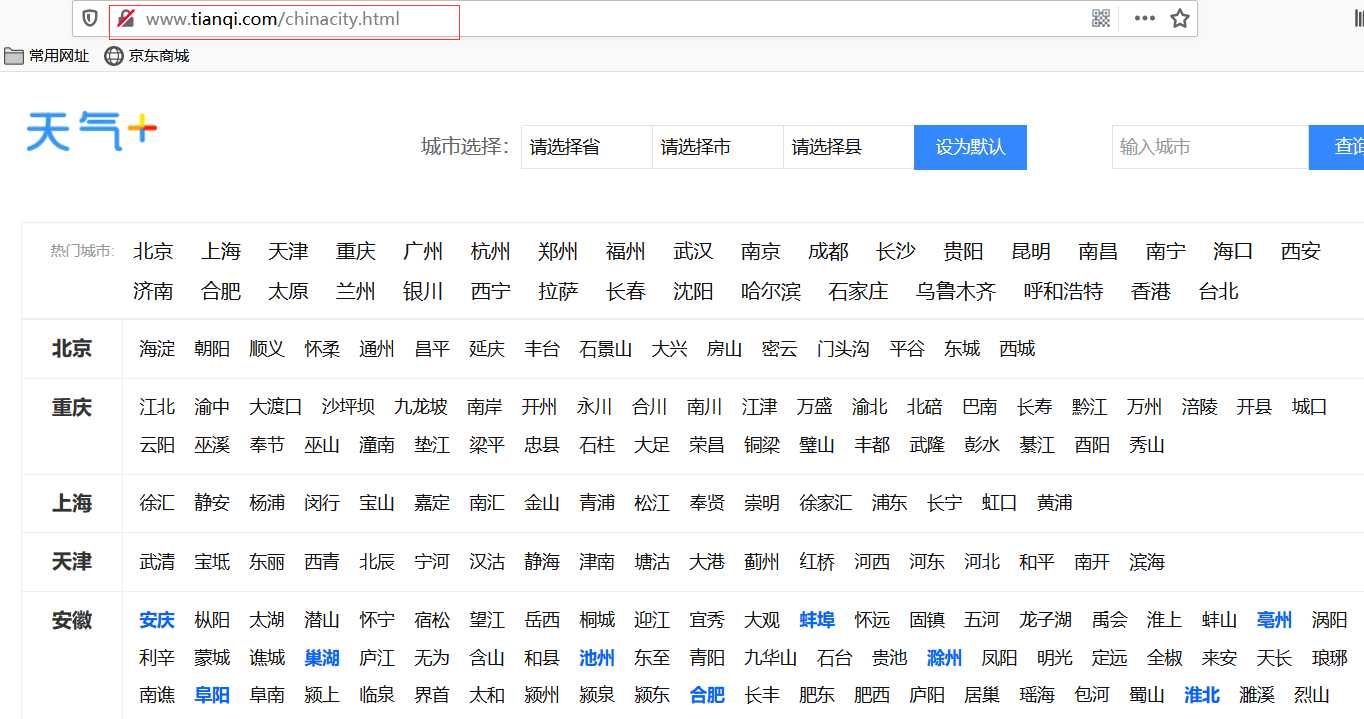
从这我们可以看出所有的省份都是存在这里的我们只需要定位到<div class="citybox">标签 然后拿到所有的<h2>标签即可
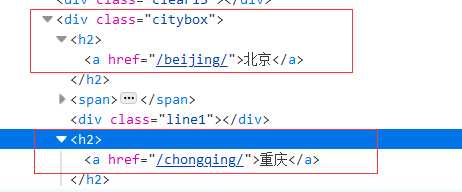
我们可以看出所有的城市都是在<div class="citybox"> --> <span> --><a>;按照这个标签顺序我们就可以获取到所有的城市,接下来我们只要把各个省市绑定在字典上即可
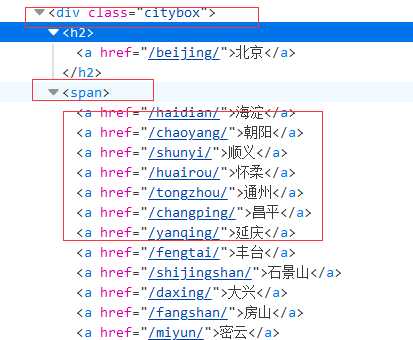
主页面的解析
从这里我们可以明确的看到各个天气信息所属的标签,很容易就可以遍历得出
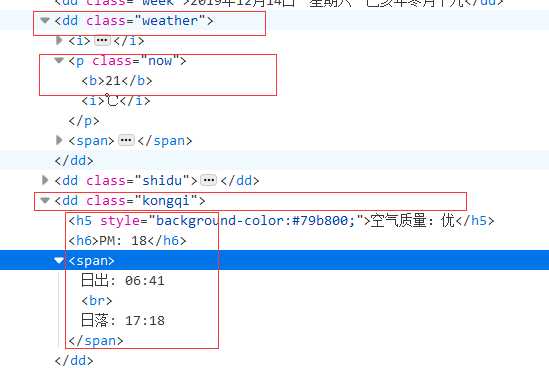
import requests import time import os import re import pandas as pd from bs4 import BeautifulSoup as BS import matplotlib.pyplot as plt def getHtml(url): try: kv = {‘user-agent‘: ‘Mozilla/5.0‘} #伪装下访问的标识不然会被拦截 r = requests.get(url,headers=kv) r.raise_for_status() #抛出访问失败的异常 r.encoding = r.apparent_encoding #设置编码格式防止乱码 return r.text #返回爬取到网页的全部代码 except: print("爬取失败")
#获取温度 def getTemperature(html): soup = BS(html, "html.parser") a = soup.find("p",attrs="now") return a.text
#获取天气信息 def getWeather(html): soup = BS(html, "html.parser") b = soup.find("dd",attrs="kongqi") return b.text
#获取pm2.5 def getPm(html): soup = BS(html, "html.parser") b = soup.find("dd",attrs="kongqi") aa = b.h6.text pm = re.findall("\d+", aa) return int(pm[0]) #数据存储 def dataSave(): try: #创建文件夹 os.mkdir("C:\天气") except: #如果文件夹存在则什么也不做 "" #获取各个县市信息英文 def getCityHref(html): #创建2个空表用来存放城市的信息 oldList = [] cityHrefList = [] #把获取到的内容包装成BS对象 soup = BS(html, "html.parser") #提取包含城市的标签 tab = soup.find("div",attrs="citybox") #获取到所有城市的标签 a = tab.find_all("span") #遍历得到各个省市 for d in range(len(a)): for x in a[d].find_all("a"): if x is not None: oldList.append(x.get("href")) #把得到得省包装在一个列表上,各个省之间分开 cityHrefList.append(oldList) #清除列表 oldList = [] #返回一个包含所有省市得列表 return cityHrefList #获取各个省份信息中文 def getCityName(html): #创建2个空表用来存放省市的信息 oldList = [] cityNameList = [] soup = BS(html, "html.parser") #提取包含省市的标签 b = soup.find("div",attrs="citybox") #获取到所有省市的标签 a = b.find_all("span") #遍历得到各个省市 for d in range(len(a)): for x in a[d].find_all("a"): if x is not None: oldList.append(x.text) #print(list) #把得到得省包装在一个列表上,各个省之间分开 cityNameList.append(oldList) #清除列表 oldList = [] #返回一个包含所有省市得列表 return cityNameList #获取各个省份信息 def getProvince(html): ProvinceList = [] soup = BS(html, "html.parser") b = soup.find("div", attrs="citybox") for x in b.find_all("h2"): ProvinceList.append(x.text) return ProvinceList #获取所有地方的天气 def getCityWeather(dic,dic2): nowTime = time.strftime("%Y-%m-%d %H:%M", time.localtime()) for into in cityProvinceList: # 数据保存 dataSave() try: # 创建文件用于存储爬取到的数据 with open("C:\\天气\\各地天气信息.txt", "a") as f: f.write("当前时间为{}以下为{}省的天气\n".format(nowTime,into)) except: "存储失败" print("正在存储{}省的天气".format(into)) for x in dic.get(into): url = "https://www.tianqi.com/" + x html = getHtml(url) try: # 创建文件用于存储爬取到的数据 with open("C:\\天气\\各地天气信息.txt", "a") as f: f.write("{}:{},{}\n".format(dic2.get(x),getTemperature(html),getWeather(html))) except: "存储失败" print("存储成功") #获取各省的平均pm2.5 def getCityPM(cityProvinceList,dic): pmList = [] #存放各省的平均pm2.5 pm = 0 #pm2.5累加 num = 0 #计数 start_time1 = time.time() for into in cityProvinceList[0:6]: start_time = time.time() # 记录当前时间 print("以下为" + into + "省pm2.5的平均值") for x in dic.get(into): url = "https://www.tianqi.com/" + x html = getHtml(url) pm = pm + getPm(html) num += 1 avePm = round(pm/num) # pmList.append([into,avePm]) pmList.append(avePm) elapse_time = time.time() - start_time print("计算{}的pm2.5平均值成功,共有{}个城市,平均值为{},耗时{:.2f}s".format(into,num,avePm,elapse_time)) num = 0 #计数归0一下 elapse_time = time.time() - start_time1 print("总耗时{:.2f}分".format(elapse_time/60)) return pmList if __name__ == "__main__": html = getHtml("http://www.tianqi.com/chinacity.html") cityHreflist = getCityHref(html) #获取市链接 cityProvinceList = getProvince(html) #获取省 cityName = getCityName(html) #获取市中文 #把各个省份按照字典得形式绑定起来,省市 dic = {} #市英语转汉字 dic2 = {} for d in range(len(cityHreflist)): dic.update({cityProvinceList[d]:cityHreflist[d]}) for aa in range(len(cityName)): for xx in range(len(cityHreflist[aa])): dic2.update({cityHreflist[aa][xx]:cityName[aa][xx]}) #获取各地的信息 #getCityWeather(dic,dic2) #获取各省pm2.5的平均值返回列表 pmList = getCityPM(cityProvinceList, dic) plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签 plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号 s = pd.Series(pmList,cityProvinceList[0:6]) # 设置图表标题 s.plot(kind=‘bar‘, title=‘6个省份pm2.5平均值对比‘) # 输出图片 plt.show() # into = input("请输入你要查询得省份") # for x in dic.get(into): # url = "https://www.tianqi.com/" + x # html = getHtml(url) # print(dic2.get(x) + ":" + getTemperature(html), end="") # print(getWeather(html)) # print("--------------")
def getCityWeather(dic,dic2): nowTime = time.strftime("%Y-%m-%d %H:%M", time.localtime()) for into in cityProvinceList: print("当前时间为{}以下为{}省的天气".format(nowTime,into)) for x in dic.get(into): url = "https://www.tianqi.com/" + x html = getHtml(url) print(dic2.get(x) + ":" + getTemperature(html), end="") print(getWeather(html)) print("--------------")
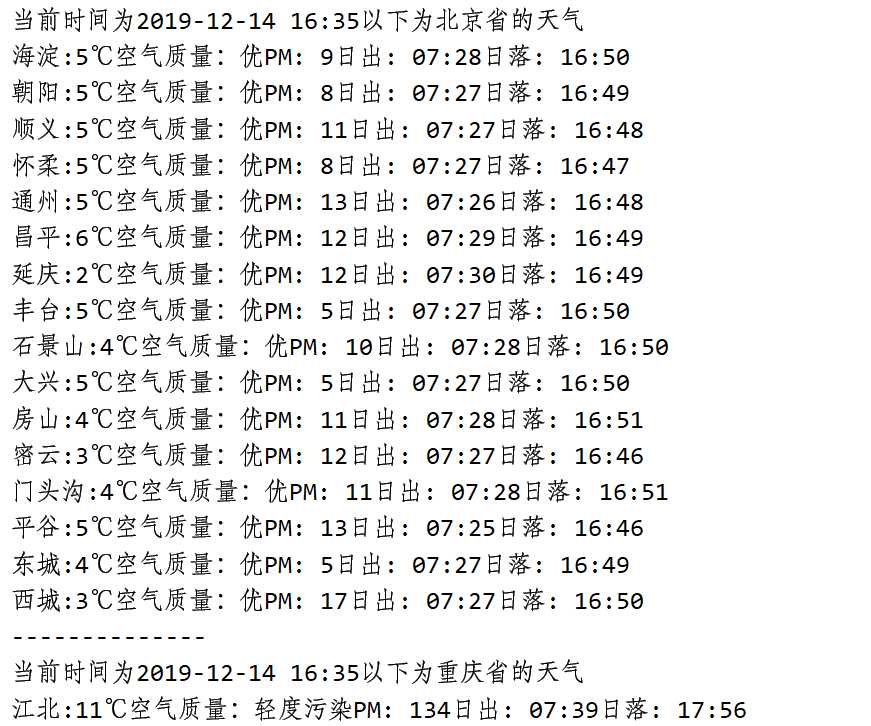
def getCityPM(cityProvinceList,dic): pmList = [] #存放各省的平均pm2.5 pm = 0 #pm2.5累加 num = 0 #计数 for into in cityProvinceList: print("以下为" + into + "省pm2.5的平均值") for x in dic.get(into): start_time = time.time() #记录当前时间 url = "https://www.tianqi.com/" + x html = getHtml(url) pm = pm + getPm(html) num += 1 avePm = round(pm/num) pmList.append([into,avePm]) elapse_time = time.time() - start_time print("计算{}的pm2.5平均值成功,共有{}个城市,平均值为{},耗时{}".format(into,num,avePm,elapse_time)) num = 0 #计数归0一下 return pmList

#获取各省的平均pm2.5 def getCityPM(cityProvinceList,dic): pmList = [] #存放各省的平均pm2.5 pm = 0 #pm2.5累加 num = 0 #计数 start_time1 = time.time() for into in cityProvinceList[0:6]: start_time = time.time() # 记录当前时间 print("以下为" + into + "省pm2.5的平均值") for x in dic.get(into): url = "https://www.tianqi.com/" + x html = getHtml(url) pm = pm + getPm(html) num += 1 avePm = round(pm/num) # pmList.append([into,avePm]) pmList.append(avePm) elapse_time = time.time() - start_time print("计算{}的pm2.5平均值成功,共有{}个城市,平均值为{},耗时{:.2f}s".format(into,num,avePm,elapse_time)) num = 0 #计数归0一下 elapse_time = time.time() - start_time1 print("总耗时{:.2f}分".format(elapse_time/60)) return pmList if __name__ == "__main__": html = getHtml("http://www.tianqi.com/chinacity.html") cityHreflist = getCityHref(html) #获取市链接 cityProvinceList = getProvince(html) #获取省 cityName = getCityName(html) #获取市中文 #把各个省份按照字典得形式绑定起来,省市 dic = {} #市英语转汉字 dic2 = {} for d in range(len(cityHreflist)): dic.update({cityProvinceList[d]:cityHreflist[d]}) for aa in range(len(cityName)): for xx in range(len(cityHreflist[aa])): dic2.update({cityHreflist[aa][xx]:cityName[aa][xx]}) #获取各地的信息 #getCityWeather(dic,dic2) #获取各省pm2.5的平均值返回列表 pmList = getCityPM(cityProvinceList, dic) plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签 plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号 s = pd.Series(pmList,cityProvinceList[0:6]) # 设置图表标题 s.plot(kind=‘bar‘, title=‘6个省份pm2.5平均值对比‘) # 输出图片 plt.show()
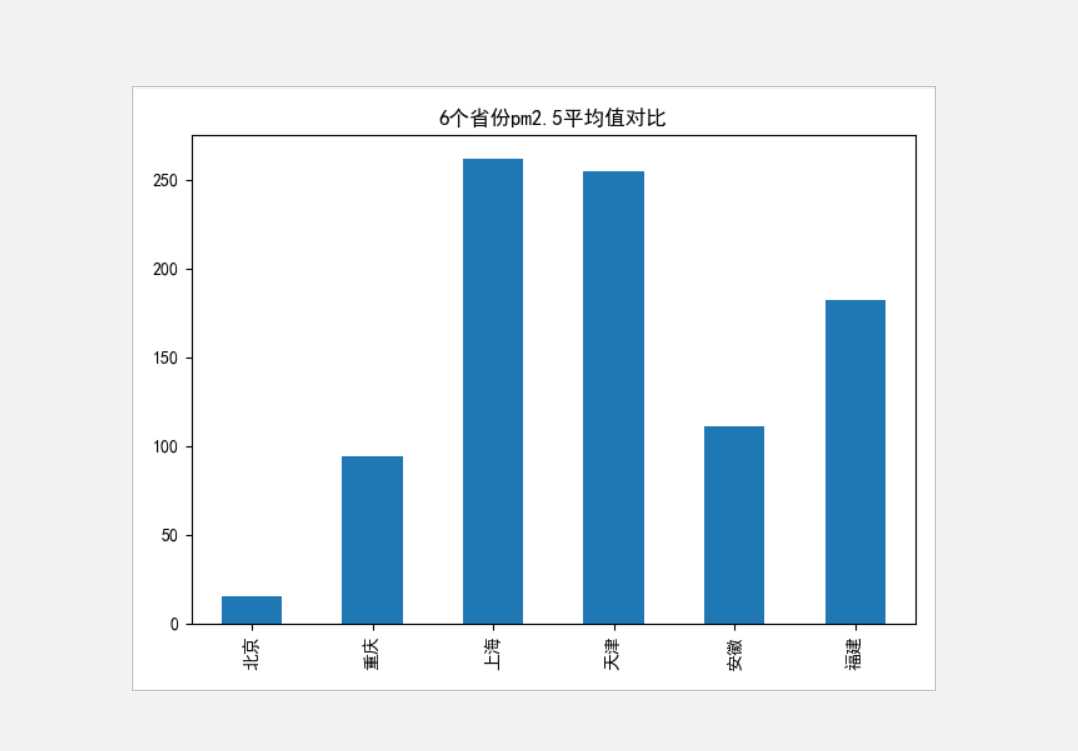
#获取所有地方的天气 def getCityWeather(dic,dic2): nowTime = time.strftime("%Y-%m-%d %H:%M", time.localtime()) for into in cityProvinceList: # 数据保存 dataSave() try: # 创建文件用于存储爬取到的数据 with open("C:\\天气\\各地天气信息.txt", "a") as f: f.write("当前时间为{}以下为{}省的天气\n".format(nowTime,into)) except: "存储失败" print("正在存储{}省的天气".format(into)) for x in dic.get(into): url = "https://www.tianqi.com/" + x html = getHtml(url) try: # 创建文件用于存储爬取到的数据 with open("C:\\天气\\各地天气信息.txt", "a") as f: f.write("{}:{},{}\n".format(dic2.get(x),getTemperature(html),getWeather(html))) except: "存储失败" print("存储成功")

标签:str 网页 标题 bar requests int 出图 mil 列表
原文地址:https://www.cnblogs.com/kunqi/p/12040608.html