标签:存储 item 大量 思想 指定 指标 简单 mamicode 空间
http://kylin.apache.org/docs/index.html
https://www.infoq.cn/article/vOrjsJCgVAVPim5hsj6p
Kylin 的核心思想是预计算,将数据按照指定的维度和指标,预先计算出所有可能的查询结果,利用空间换时间来加速查询模式固定的 OLAP 查询
Kylin 的理论基础是 Cube 理论,每一种维度组合称之为 Cuboid,所有 Cuboid 的集合是 Cube
单维度组成的Cuboid,称为base cuboid,如图中(time,item,location,supplier)
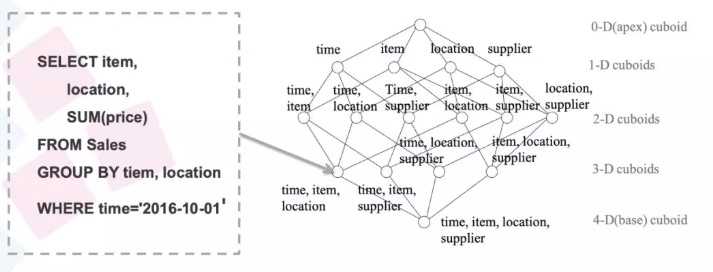
如果预先计算出所有组合的聚合值,那么在查询时候就会很快,但是这个空间膨胀有点吓人
带来的直接效果,在查询时,可以不用做Agg和Join这些耗时的操作

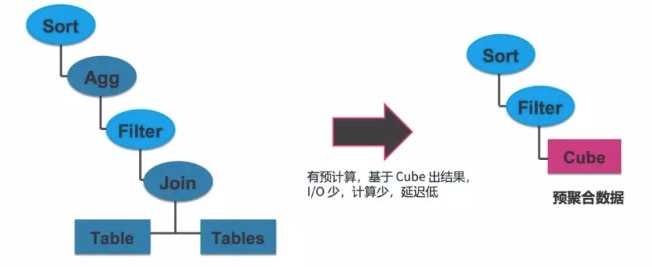
初始的Kylin,Cube数据存储在Hbase里面
查询时,Kylin server从Hbase读到相应的cube数据,简单计算后返回给用户
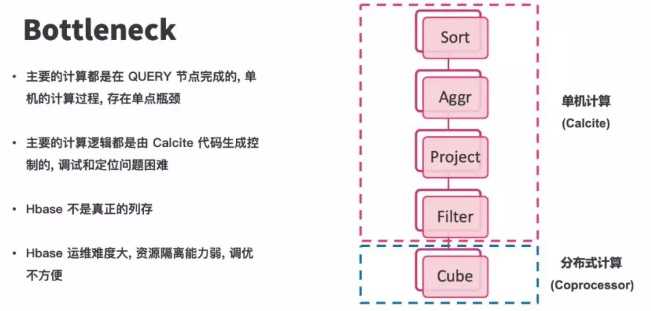
问题就是,Hbase是分布式,但是Query节点是单机的,如果在Query节点需要大量计算,就会有瓶颈,比如多个子查询的合并,聚合,Distinct
所以现在提出的方案,Kylin On Parquet
Kylin的主要创意在预计算,预计算的结果存在HBase,HBase本身是行存,在分析上性能也不会很好,HBase本身就是一个写入优先的存储,而不是查询
查询这块,如果用Spark,加上底层用Parquet存储,会大大提升分析性能
标签:存储 item 大量 思想 指定 指标 简单 mamicode 空间
原文地址:https://www.cnblogs.com/fxjwind/p/12059568.html