标签:标签 处理 官网 文件 image 一个 style compact 持久
名称:爬取虾米音乐排行
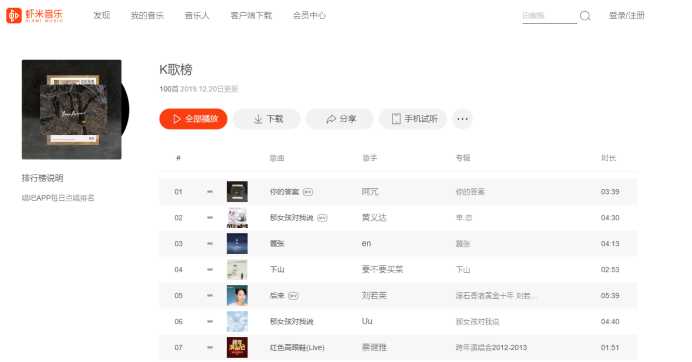
2.主题式网络爬虫爬取的内容与数据特征分析本次爬虫主要爬取虾米音乐排行榜和评论数
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)本次设计方案主要使用request库和beautifulSoup库对网站访问,records数据持久化。
技术难点主要包括对虾米音乐网站页面的结构分析。




#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import records
def getHtml(url):
‘‘‘
获取目标网页数据
‘‘‘
try:
# 伪装UA
ua = {‘user-agent‘: ‘Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36‘}
# 读取网页
r = requests.get(url, headers=ua)
# 获取状态
r.raise_for_status()
# 打印数据 print(r.text)
# 返回数据
return r.text
except:
return "Fail"
def parseHtml(html):
# 数据数组
datas = []
# 结构解析
soup = BeautifulSoup(html, "html.parser")
# 获取排名
ids = soup.select(‘.em.index‘)
# 组号
i = 0
# 循环排名号
for id in ids:
# 字典
data = {}
# 获取编号
idd = id.get_text()
# 打印数据
print(idd)
# 获取歌曲名
titles = soup.select(‘.song-name.em‘)[i].get_text()
# 打印数据
print(titles)
# 获取歌手
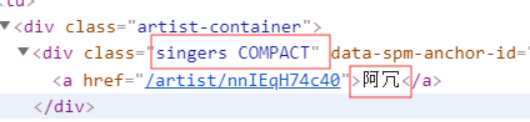
songer = soup.select(‘.singers.COMPACT‘)[i].get_text()
# 打印数据
print(songer)
# 获取专辑
album = soup.select(‘.album‘)[i].get_text()
# 打印数据
print(album)
# 获取时长
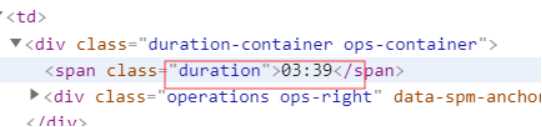
duration = soup.select(‘.duration‘)[i].get_text()
# 打印数据
print(duration)
# 数组
i = i + 1
# 加入字典
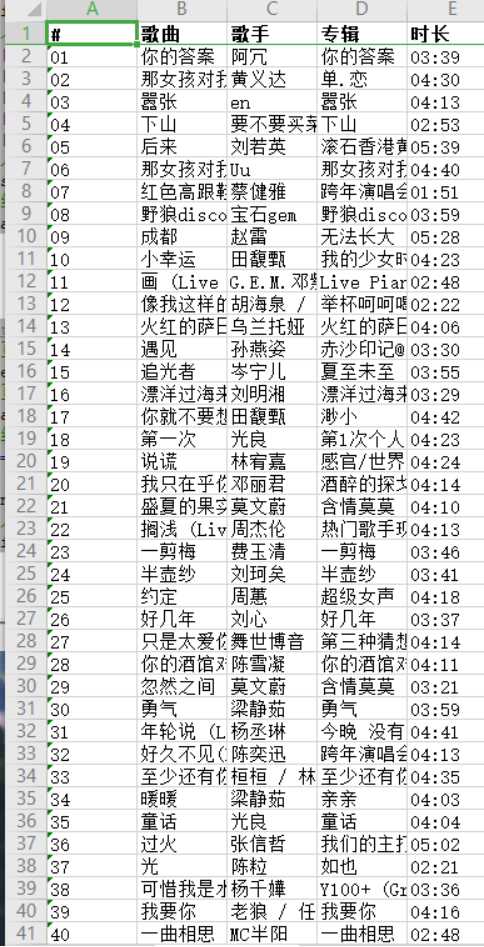
data[‘#‘] = idd
data[‘歌曲‘] = titles
data[‘歌手‘] = songer
data[‘专辑‘] = album
data[‘时长‘] = duration
# 加入数组
datas.append(data)
# 返回数组
return datas
def main():
# url
url = "https://www.xiami.com/billboard/306"
# 获取网页数据
html = getHtml(url)
# 解析网页结构
list = parseHtml(html)
# 初始化组件
results = records.RecordCollection(iter(list))
# 文件流
with open(‘list.xlsx‘, ‘wb‘) as f:
# 写入
f.write(results.export(‘xlsx‘))
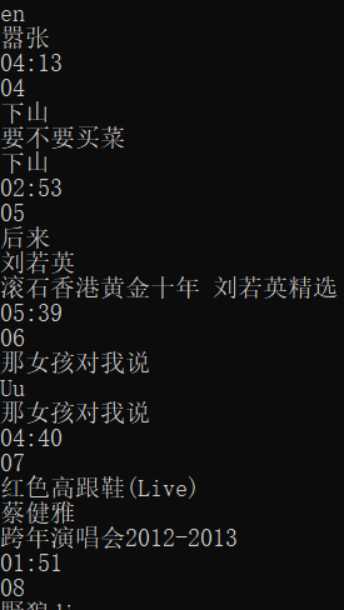
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import records def getHtml(url): ‘‘‘ 获取目标网页数据 ‘‘‘ try: # 伪装UA ua = {‘user-agent‘: ‘Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36‘} # 读取网页 r = requests.get(url, headers=ua) # 获取状态 r.raise_for_status() # 打印数据 print(r.text) # 返回数据 return r.text except: return "Fail" def parseHtml(html): # 数据数组 datas = [] # 结构解析 soup = BeautifulSoup(html, "html.parser") # 获取排名 ids = soup.select(‘.em.index‘) # 组号 i = 0 # 循环排名号 for id in ids: # 字典 data = {} # 获取编号 idd = id.get_text() # 打印数据 print(idd) # 获取歌曲名 titles = soup.select(‘.song-name.em‘)[i].get_text() # 打印数据 print(titles) # 获取歌手 songer = soup.select(‘.singers.COMPACT‘)[i].get_text() # 打印数据 print(songer) # 获取专辑 album = soup.select(‘.album‘)[i].get_text() # 打印数据 print(album) # 获取时长 duration = soup.select(‘.duration‘)[i].get_text() # 打印数据 print(duration) # 数组 i = i + 1 # 加入字典 data[‘#‘] = idd data[‘歌曲‘] = titles data[‘歌手‘] = songer data[‘专辑‘] = album data[‘时长‘] = duration # 加入数组 datas.append(data) # 返回数组 return datas def main(): # url url = "https://www.xiami.com/billboard/306" # 获取网页数据 html = getHtml(url) # 解析网页结构 list = parseHtml(html) # 初始化组件 results = records.RecordCollection(iter(list)) # 文件流 with open(‘list.xlsx‘, ‘wb‘) as f: # 写入 f.write(results.export(‘xlsx‘))
标签:标签 处理 官网 文件 image 一个 style compact 持久
原文地址:https://www.cnblogs.com/dengyingsi/p/12078410.html