标签:layer 不可用 call() sig 请求 要求 tween %s was
任何编程语言都不是完美的,Go 语言也是如此。Go 语言的某些特性在使用时如果不注意,也会造成一些错误,我们习惯上将这些造成错误的设计称为“坑”。
Go 语言的一些设计也具有与其他编程语言不一样的特性,能优雅、简单、高效地解决一些其他语言难以解决的问题。
本章将会对 Go 语言设计上可能发生错误的地方及 Go 语言本身的使用技巧进行总结和归纳。
Go语言原生支持并发是被众人津津乐道的特性。goroutine 早期是 Inferno 操作系统的一个试验性特性,而现在这个特性与操作系统一起,将开发变得越来越简单。
很多刚开始使用 Go语言开发的人都很喜欢使用并发特性,而没有考虑并发是否真正能解决他们的问题。
了解 goroutine 的生命期时再创建 goroutine
在 Go语言中,开发者习惯将并发内容与 goroutine 一一对应地创建 goroutine。开发者很少会考虑 goroutine 在什么时候能退出和控制 goroutine 生命期,这就会造成 goroutine 失控的情况。下面来看一段代码。
失控的 goroutine:
package main
import (
"fmt"
"runtime"
)
// 一段耗时的计算函数
func consumer(ch chan int) {
// 无限获取数据的循环
for {
// 从通道获取数据
data := <-ch
// 打印数据
fmt.Println(data)
}
}
func main() {
// 创建一个传递数据用的通道
ch := make(chan int)
for {
// 空变量, 什么也不做
var dummy string
// 获取输入, 模拟进程持续运行
fmt.Scan(&dummy)
// 启动并发执行consumer()函数
go consumer(ch)
// 输出现在的goroutine数量
fmt.Println("goroutines:", runtime.NumGoroutine())
}
}代码说明如下:
第 9 行,consumer() 函数模拟平时业务中放到 goroutine 中执行的耗时操作。该函数从其他 goroutine 中获取和接收数据或者指令,处理后返回结果。
第 12 行,需要通过无限循环不停地获取数据。
第 15 行,每次从通道中获取数据。
第 18 行,模拟处理完数据后的返回数据。
第 26 行,创建一个整型通道。
第 34 行,使用 fmt.Scan() 函数接收数据时,需要提供变量地址。如果输入匹配的变量类型,将会成功赋值给变量。
第 37 行,启动并发执行 consumer() 函数,并传入 ch 通道。
第 40 行,每启动一个 goroutine,使用 runtime.NumGoroutine 检查进程创建的 goroutine 数量总数。
运行程序,每输入一个字符串+回车,将会创建一个 goroutine,结果如下:
a
goroutines: 2
b
goroutines: 3
c
goroutines: 4注意,结果中 a、b、c 为通过键盘输入的字符,其他为打印字符。
这个程序实际在模拟一个进程根据需要创建 goroutine 的情况。运行后,问题已经被暴露出来:随着输入的字符串越来越多,goroutine 将会无限制地被创建,但并不会结束。这种情况如果发生在生产环境中,将会造成内存大量分配,最终使进程崩溃。现实的情况也许比这段代码更加隐蔽:也许你设置了一个退出的条件,但是条件永远不会被满足或者触发。
为了避免这种情况,在这个例子中,需要为 consumer() 函数添加合理的退出条件,修改代码后如下:
package main
import (
"fmt"
"runtime"
)
// 一段耗时的计算函数
func consumer(ch chan int) {
// 无限获取数据的循环
for {
// 从通道获取数据
data := <-ch
if data == 0 {
break
}
// 打印数据
fmt.Println(data)
}
fmt.Println("goroutine exit")
}
func main() {
// 传递数据用的通道
ch := make(chan int)
for {
// 空变量, 什么也不做
var dummy string
// 获取输入, 模拟进程持续运行
fmt.Scan(&dummy)
if dummy == "quit" {
for i := 0; i < runtime.NumGoroutine()-1; i++ {
ch <- 0
}
continue
}
// 启动并发执行consumer()函数
go consumer(ch)
// 输出现在的goroutine数量
fmt.Println("goroutines:", runtime.NumGoroutine())
}
}代码中加粗部分是新添加的代码,具体说明如下:
第 17 行,为无限循环设置退出条件,这里设置 0 为退出。
第 41 行,当命令行输入 quit 时,进入退出处理的流程。
第 43 行,runtime.NumGoroutine 返回一个进程的所有 goroutine 数,main() 的 goroutine 也被算在里面。因此需要扣除 main() 的 goroutine 数。剩下的 goroutine 为实际创建的 goroutine 数,对这些 goroutine 进行遍历。
第 44 行,并发开启的 goroutine 都在竞争获取通道中的数据,因此只要知道有多少个 goroutine 需要退出,就给通道里发多少个 0。
修改程序并运行,结果如下:
a
goroutines: 2
b
goroutines: 3
quit
goroutine exit
goroutine exit
c
goroutines: 2避免在不必要的地方使用通道
通道(channel)和 map、切片一样,也是由 Go 源码编写而成。为了保证两个 goroutine 并发访问的安全性,通道也需要做一些锁操作,因此通道其实并不比锁高效。
下面的例子展示套接字的接收和并发管理。对于 TCP 来说,一般是接收过程创建 goroutine 并发处理。当套接字结束时,就要正常退出这些 goroutine。
本例完整代码请参考./src/chapter12/exitnotify/exitnotify.go。
本套教程所有源码下载地址:https://pan.baidu.com/s/1ORFVTOLEYYqDhRzeq0zIiQ 提取密码:hfyf
下面是对各个部分的详细分析。
1) 套接字接收部分
套接字在连接后,就需要不停地接收数据,代码如下:
// 套接字接收过程
func socketRecv(conn net.Conn, exitChan chan string) {
// 创建一个接收的缓冲
buff := make([]byte, 1024)
// 不停地接收数据
for {
// 从套接字中读取数据
_, err := conn.Read(buff)
// 需要结束接收, 退出循环
if err != nil {
break
}
}
// 函数已经结束, 发送通知
exitChan <- "recv exit"
}代码说明如下:
第 2 行传入的 net.Conn 是套接字的接口,exitChan 为退出发送同步通道。
第 5 行为套接字的接收数据创建一个缓冲。
第 8 行构建一个接收的循环,不停地接收数据。
第 11 行,从套接字中取出数据。这个例子中,不关注具体接收到的数据,只是关注错误,这里将接收到的字节数做匿名处理。
第 14 行,当套接字调用了 Close 方法时,会触发错误,这时需要结束接收循环。
第 21 行,结束函数时,与函数绑定的 goroutine 会同时结束,此时需要通知 main() 的 goroutine。
2) 连接、关闭、同步 goroutine 主流程部分
下面代码中尝试使用套接字的 TCP 协议连接一个网址,连接上后,进行数据接收,等待一段时间后主动关闭套接字,等待套接字所在的 goroutine 自然结束,代码如下:
func main() {
// 连接一个地址
conn, err := net.Dial("tcp", "www.163.com:80")
// 发生错误时打印错误退出
if err != nil {
fmt.Println(err)
return
}
// 创建退出通道
exit := make(chan string)
// 并发执行套接字接收
go socketRecv(conn, exit)
// 在接收时, 等待1秒
time.Sleep(time.Second)
// 主动关闭套接字
conn.Close()
// 等待goroutine退出完毕
fmt.Println(<-exit)
}代码说明如下:
第 4 行,使用 net.Dial 发起 TCP 协议的连接,调用函数就会发送阻塞直到连接超时或者连接完成。
第 7 行,如果连接发生错误,将会打印错误并退出。
第 13 行,创建一个通道用于退出信号同步,这个通道会在接收用的 goroutine 中使用。
第 16 行,并发执行接收函数,传入套接字和用于退出通知的通道。
第 19 行,接收需要一个过程,使用 time.Sleep() 等待一段时间。
第 22 行,主动关闭套接字,此时会触发套接字接收错误。
第 25 行,从 exit 通道接收退出数据,也就是等待接收 goroutine 结束。
在这个例子中,goroutine 退出使用通道来通知,这种做法可以解决问题,但是实际上通道中的数据并没有完全使用。
3) 优化:使用等待组替代通道简化同步
通道的内部实现代码在 Go语言开发包的 src/runtime/chan.go 中,经过分析后大概了解到通道也是用常见的互斥量等进行同步。因此通道虽然是一个语言级特性,但也不是被神化的特性,通道的运行和使用都要比传统互斥量、等待组(sync.WaitGroup)有一定的消耗。
所以在这个例子中,更建议使用等待组来实现同步,调整后的代码如下:
package main
import (
"fmt"
"net"
"sync"
"time"
)
// 套接字接收过程
func socketRecv(conn net.Conn, wg *sync.WaitGroup) {
// 创建一个接收的缓冲
buff := make([]byte, 1024)
// 不停地接收数据
for {
// 从套接字中读取数据
_, err := conn.Read(buff)
// 需要结束接收, 退出循环
if err != nil {
break
}
}
// 函数已经结束, 发送通知
wg.Done()
}
func main() {
// 连接一个地址
conn, err := net.Dial("tcp", "www.163.com:80")
// 发生错误时打印错误退出
if err != nil {
fmt.Println(err)
return
}
// 退出通道
var wg sync.WaitGroup
// 添加一个任务
wg.Add(1)
// 并发执行接收套接字
go socketRecv(conn, &wg)
// 在接收时, 等待1秒
time.Sleep(time.Second)
// 主动关闭套接字
conn.Close()
// 等待goroutine退出完毕
wg.Wait()
fmt.Println("recv done")
}调整后的代码说明如下:
第 45 行,声明退出同步用的等待组。
第 48 行,为等待组的计数器加 1,表示需要完成一个任务。
第 51 行,将等待组的指针传入接收函数。
第 60 行,等待等待组的完成,完成后打印提示。
第 30 行,接收完成后,使用 wg.Done() 方法将等待组计数器减一。
现在的一些流行设计思想需要建立在反射基础上,如控制反转(Inversion Of Control,IOC)和依赖注入(Dependency Injection,DI)。Go语言中非常有名的 Web 框架 martini(https://github.com/go-martini/martini)就是通过依赖注入技术进行中间件的实现,例如使用 martini 框架搭建的 http 的服务器如下:
package main
import "github.com/go-martini/martini"
func main() {
m := martini.Classic()
m.Get("/", func() string {
return "Hello world!"
})
m.Run()
}第 7 行,响应路径/的代码使用一个闭包实现。如果希望获得 Go语言中提供的请求和响应接口,可以直接修改为:
m.Get("/", func(res http.ResponseWriter, req *http.Request) string {
// 响应处理代码……
})martini 的底层会自动通过识别 Get 获得的闭包参数情况,通过动态反射调用这个函数并传入需要的参数。martini 的设计广受好评,但同时也有人指出,其运行效率较低。其中最主要的因素是大量使用了反射。
虽然一般情况下,I/O 的延迟远远大于反射代码所造成的延迟。但是,更低的响应速度和更低的 CPU 占用依然是 Web 服务器追求的目标。因此,反射在带来灵活性的同时,也带上了性能低下的桎梏。
要用好反射这把双刃剑,就需要详细了解反射的性能。下面的一些基准测试从多方面对比了原生调用和反射调用的区别。
1) 结构体成员赋值对比
反射经常被使用在结构体上,因此结构体的成员访问性能就成为了关注的重点。下面例子中使用一个被实例化的结构体,访问它的成员,然后使用 Go语言的基准化测试可以迅速测试出结果。
反射性能测试的完整代码位于./src/chapter12/reflecttest/reflect_test.go,下面是对各个部分的详细说明。
本套教程所有源码下载地址:https://pan.baidu.com/s/1ORFVTOLEYYqDhRzeq0zIiQ 提取密码:hfyf
原生结构体的赋值过程:
// 声明一个结构体, 拥有一个字段
type data struct {
Hp int
}
func BenchmarkNativeAssign(b *testing.B) {
// 实例化结构体
v := data{Hp: 2}
// 停止基准测试的计时器
b.StopTimer()
// 重置基准测试计时器数据
b.ResetTimer()
// 重新启动基准测试计时器
b.StartTimer()
// 根据基准测试数据进行循环测试
for i := 0; i < b.N; i++ {
// 结构体成员赋值测试
v.Hp = 3
}
}代码说明如下:
第 2 行,声明一个普通结构体,拥有一个成员变量。
第 6 行,使用基准化测试的入口。
第 9 行,实例化 data 结构体,并给 Hp 成员赋值。
第 12~17 行,由于测试的重点必须放在赋值上,因此需要极大程度地降低其他代码的干扰,于是在赋值完成后,将基准测试的计时器复位并重新开始。
第 20 行,将基准测试提供的测试数量用于循环中。
第 23 行,测试的核心代码:结构体赋值。
接下来的代码分析使用反射访问结构体成员并赋值的过程。
func BenchmarkReflectAssign(b *testing.B) {
v := data{Hp: 2}
// 取出结构体指针的反射值对象并取其元素
vv := reflect.ValueOf(&v).Elem()
// 根据名字取结构体成员
f := vv.FieldByName("Hp")
b.StopTimer()
b.ResetTimer()
b.StartTimer()
for i := 0; i < b.N; i++ {
// 反射测试设置成员值性能
f.SetInt(3)
}
}代码说明如下:
第 6 行,取v的地址并转为反射值对象。此时值对象里的类型为 *data,使用值的 Elem() 方法取元素,获得 data 的反射值对象。
第 9 行,使用 FieldByName() 根据名字取出成员的反射值对象。
第 11~13 行,重置基准测试计时器。
第 18 行,使用反射值对象的 SetInt() 方法,给 data 结构的Hp字段设置数值 3。
这段代码中使用了反射值对象的 SetInt() 方法,这个方法的源码如下:
func (v Value) SetInt(x int64) {
v.mustBeAssignable()
switch k := v.kind(); k {
default:
panic(&ValueError{"reflect.Value.SetInt", v.kind()})
case Int:
*(*int)(v.ptr) = int(x)
case Int8:
*(*int8)(v.ptr) = int8(x)
case Int16:
*(*int16)(v.ptr) = int16(x)
case Int32:
*(*int32)(v.ptr) = int32(x)
case Int64:
*(*int64)(v.ptr) = x
}
}可以发现,整个设置过程都是指针转换及赋值,没有遍历及内存操作等相对耗时的算法。
2) 结构体成员搜索并赋值对比
func BenchmarkReflectFindFieldAndAssign(b *testing.B) {
v := data{Hp: 2}
vv := reflect.ValueOf(&v).Elem()
b.StopTimer()
b.ResetTimer()
b.StartTimer()
for i := 0; i < b.N; i++ {
// 测试结构体成员的查找和设置成员的性能
vv.FieldByName("Hp").SetInt(3)
}
}这段代码将反射值对象的 FieldByName() 方法与 SetInt() 方法放在循环里进行检测,主要对比测试 FieldByName() 方法对性能的影响。FieldByName() 方法源码如下:
func (v Value) FieldByName(name string) Value {
v.mustBe(Struct)
if f, ok := v.typ.FieldByName(name); ok {
return v.FieldByIndex(f.Index)
}
return Value{}
}底层代码说明如下:
第 3 行,通过名字查询类型对象,这里有一次遍历过程。
第 4 行,找到类型对象后,使用 FieldByIndex() 继续在值中查找,这里又是一次遍历。
经过底层代码分析得出,随着结构体字段数量和相对位置的变化,FieldByName() 方法比较严重的低效率问题。
3) 调用函数对比
反射的函数调用,也是使用反射中容易忽视的性能点,下面展示对普通函数的调用过程。
// 一个普通函数
func foo(v int) {
}
func BenchmarkNativeCall(b *testing.B) {
for i := 0; i < b.N; i++ {
// 原生函数调用
foo(0)
}
}
func BenchmarkReflectCall(b *testing.B) {
// 取函数的反射值对象
v := reflect.ValueOf(foo)
b.StopTimer()
b.ResetTimer()
b.StartTimer()
for i := 0; i < b.N; i++ {
// 反射调用函数
v.Call([]reflect.Value{reflect.ValueOf(2)})
}
}代码说明如下:
第 2 行,一个普通的只有一个参数的函数。
第 10 行,对原生函数调用的性能测试。
第 17 行,根据函数名取出反射值对象。
第 25 行,使用 reflect.ValueOf(2) 将 2 构造为反射值对象,因为反射函数调用的参数必须全是反射值对象,再使用 []reflect.Value 构造多个参数列表传给反射值对象的 Call() 方法进行调用。
反射函数调用的参数构造过程非常复杂,构建很多对象会造成很大的内存回收负担。Call() 方法内部就更为复杂,需要将参数列表的每个值从 reflect.Value 类型转换为内存。调用完毕后,还要将函数返回值重新转换为 reflect.Value 类型返回。因此,反射调用函数的性能堪忧。
4) 基准测试结果对比
测试结果如下:
$ go test -v -bench=.
goos: linux
goarch: amd64
BenchmarkNativeAssign-4 2000000000 0.32 ns/op
BenchmarkReflectAssign-4 300000000 4.42 ns/op
BenchmarkReflectFindFieldAndAssign-4 20000000 91.6 ns/op
BenchmarkNativeCall-4 2000000000 0.33 ns/op
BenchmarkReflectCall-4 10000000 163 ns/op
PASS结果分析如下:
第 4 行,原生的结构体成员赋值,每一步操作耗时 0.32 纳秒,这是参考基准。
第 5 行,使用反射的结构体成员赋值,操作耗时 4.42 纳秒,比原生赋值多消耗 13 倍的性能。
第 6 行,反射查找结构体成员且反射赋值,操作耗时 91.6 纳秒,扣除反射结构体成员赋值的 4.42 纳秒还富余,性能大概是原生的 272 倍。这个测试结果与代码分析结果很接近。SetInt 的性能可以接受,但 FieldByName() 的性能就非常低。
第 7 行,原生函数调用,性能与原生访问结构体成员接近。
第 8 行,反射函数调用,性能差到“爆棚”,花费了 163 纳秒,操作耗时比原生多消耗 494 倍。
经过基准测试结果的数值分析及对比,最终得出以下结论:
nil 在 Go语言中只能被赋值给指针和接口。接口在底层的实现有两个部分:type 和 data。在源码中,显式地将 nil 赋值给接口时,接口的 type 和 data 都将为 nil。此时,接口与 nil 值判断是相等的。但如果将一个带有类型的 nil 赋值给接口时,只有 data 为 nil,而 type 为 nil,此时,接口与 nil 判断将不相等。
接口与 nil 不相等
下面代码使用 MyImplement() 实现 fmt 包中的 Stringer 接口,这个接口的定义如下:
type Stringer interface {
String() string
}在 GetStringer() 函数中将返回这个接口。通过 *MyImplement 指针变量置为 nil 提供 GetStringer 的返回值。在 main() 中,判断 GetStringer 与 nil 是否相等,代码如下:
package main
import "fmt"
// 定义一个结构体
type MyImplement struct{}
// 实现fmt.Stringer的String方法
func (m *MyImplement) String() string {
return "hi"
}
// 在函数中返回fmt.Stringer接口
func GetStringer() fmt.Stringer {
// 赋nil
var s *MyImplement = nil
// 返回变量
return s
}
func main() {
// 判断返回值是否为nil
if GetStringer() == nil {
fmt.Println("GetStringer() == nil")
} else {
fmt.Println("GetStringer() != nil")
}
}代码说明如下:
第 9 行,实现 fmt.Stringer 的 String() 方法。
第 21 行,s 变量此时被 fmt.Stringer 接口包装后,实际类型为 MyImplement,值为 nil 的接口。
第 27 行,使用 GetStringer() 的返回值与 nil 判断时,虽然接口里的 value 为 nil,但 type 带有 MyImplement 信息,使用 == 判断相等时,依然不为 nil。
发现 nil 类型值返回时直接返回 nil
为了避免这类误判的问题,可以在函数返回时,发现带有 nil 的指针时直接返回 nil,代码如下:
func GetStringer() fmt.Stringer {
var s *MyImplement = nil
if s == nil {
return nil
}
return s
}在大多数的编程语言中,映射容器的键必须以单一值存在。这种映射方法经常被用在诸如信息检索上,如根据通讯簿的名字进行检索。但随着查询条件越来越复杂,检索也会变得越发困难。下面例子中涉及通讯簿的结构,结构如下:
// 人员档案
type Profile struct {
Name string // 名字
Age int // 年龄
Married bool // 已婚
}并且准备好了一堆原始数据,需要算法实现构建索引和查询的过程,代码如下:
func main() {
list := []*Profile{
{Name: "张三", Age: 30, Married: true},
{Name: "李四", Age: 21},
{Name: "王麻子", Age: 21},
}
buildIndex(list)
queryData("张三", 30)
}需要用算法实现 buildIndex() 构建索引函数及 queryData() 查询数据函数,查询到结果后将数据打印出来。
下面,分别基于传统的基于哈希值的多键索引和利用 map 特性的多键索引进行查询。
基于哈希值的多键索引及查询
传统的数据索引过程是将输入的数据做特征值。这种特征值有几种常见做法:
数据都基于特征值构建好索引后,就可以进行查询。查询时,重复这个过程,将查询条件转为特征值,使用特征值进行查询得到结果。
基于哈希的传统多键索引和查询的完整代码位于./src/chapter12/classic/classic.go,下面是对各个部分的分析。
本套教程所有源码下载地址:https://pan.baidu.com/s/1ORFVTOLEYYqDhRzeq0zIiQ 提取密码:hfyf
1) 字符串转哈希值
本例中,查询键(classicQueryKey)的特征值需要将查询键中每一个字段转换为整型,字符串也需要转换为整型值,这里使用一种简单算法将字符串转换为需要的哈希值,代码如下:
func simpleHash(str string) (ret int) {
// 遍历字符串中的每一个ASCII字符
for i := 0; i < len(str); i++ {
// 取出字符
c := str[i]
// 将字符的ASCII码相加
ret += int(c)
}
return
}代码说明如下:
第 1 行传入需要计算哈希值的字符串。
第 4 行,根据字符串的长度,遍历这个字符串的每一个字符,以 ASCII 码为单位。
第 9 行,c 变量的类型为 uint8,将其转为 int 类型并累加。
哈希算法有很多,这里只是选用一种大家便于理解的算法。哈希算法的选用的标准是尽量减少重复键的发生,俗称“哈希冲撞”,即同样两个字符串的哈希值重复率降到最低。
2) 查询键
有了哈希算法函数后,将哈希函数用在查询键结构中。查询键结构如下:
// 查询键
type classicQueryKey struct {
Name string // 要查询的名字
Age int // 要查询的年龄
}
// 计算查询键的哈希值
func (c *classicQueryKey) hash() int {
// 将名字的Hash和年龄哈希合并
return simpleHash(c.Name) + c.Age*1000000
}代码说明如下:
第 2 行,声明查询键的结构,查询键包含需要索引和查询的字段。
第 8 行,查询键的成员方法哈希,通过调用这个方法获得整个查询键的哈希值。
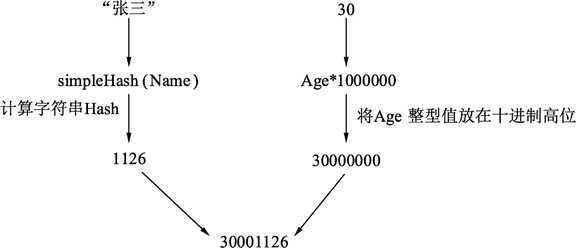
第 10 行,查询键哈希的计算方法:使用 simpleHash() 函数根据给定的名字字符串获得其哈希值。同时将年龄乘以 1000000 与名字哈希值相加。
哈希值构建过程如下图所示
3) 构建索引
本例需要快速查询,因此需要提前对已有的数据构建索引。前面已经准备好了数据查询键,使用查询键获得哈希即可对数据进行快速索引,参考下面的代码:
// 创建哈希值到数据的索引关系
var mapper = make(map[int][]*Profile)
// 构建数据索引
func buildIndex(list []*Profile) {
// 遍历所有的数据
for _, profile := range list {
// 构建数据的查询索引
key := classicQueryKey{profile.Name, profile.Age}
// 计算数据的哈希值, 取出已经存在的记录
existValue := mapper[key.hash()]
// 将当前数据添加到已经存在的记录切片中
existValue = append(existValue, profile)
// 将切片重新设置到映射中
mapper[key.hash()] = existValue
}
}代码说明如下:
第 2 行,实例化一个 map,键类型为整型,保存哈希值;值类型为 *Profile,为通讯簿的数据格式。
第 5 行,构建索引函数入口,传入数据切片。
第 8 行,遍历数据切片的所有数据元素。
第 11 行,使用查询键(classicQueryKey)来辅助计算哈希值,查询键需要填充两个字段,将数据中的名字和年龄赋值到查询键中进行保存。
第 14 行,使用查询键的哈希方法计算查询键的哈希值。通过这个值在 mapper 索引中查找相同哈希值的数据切片集合。因为哈希函数不能保证不同数据的哈希值一定完全不同,因此要考虑在发生哈希值重复时的处理办法。
第 17 行,将当前数据添加到可能存在的切片中。
第 20 行,将新添加好的数据切片重新赋值到相同哈希的 mapper 中。
具体哈希结构如下图所示。

图:哈希结构
这种多键的算法就是哈希算法。map 的多个元素对应哈希的“桶”。哈希函数的选择决定桶的映射好坏,如果哈希冲撞很厉害,那么就需要将发生冲撞的相同哈希值的元素使用切片保存起来。
4) 查询逻辑
从已经构建好索引的数据中查询需要的数据流程如下:
func queryData(name string, age int) {
// 根据给定查询条件构建查询键
keyToQuery := classicQueryKey{name, age}
// 计算查询键的哈希值并查询, 获得相同哈希值的所有结果集合
resultList := mapper[keyToQuery.hash()]
// 遍历结果集合
for _, result := range resultList {
// 与查询结果比对, 确认找到打印结果
if result.Name == name && result.Age == age {
fmt.Println(result)
return
}
}
// 没有查询到时, 打印结果
fmt.Println("no found")
}代码说明如下:
第 1 行,查询条件(名字、年龄)。
第 4 行,根据查询条件构建查询键。
第 7 行,使用查询键计算哈希值,使用哈希值查询相同哈希值的所有数据集合。
第 10 行,遍历所有相同哈希值的数据集合。
第 13 行,将每个数据与查询条件进行比对,如果一致,表示已经找到结果,打印并返回。
第 20 行,没有找到记录时,打印 no found。
利用 map 特性的多键索引及查询
使用结构体进行多键索引和查询比传统的写法更为简单,最主要的区别是无须准备哈希函数及相应的字段无须做哈希合并。看下面的实现流程。
利用map特性的多键索引和查询的代码位于./src/chapter12/multikey/multikey.go,下面是对各个部分的分析。
本套教程所有源码下载地址:https://pan.baidu.com/s/1ORFVTOLEYYqDhRzeq0zIiQ 提取密码:hfyf
1) 构建索引
代码如下:
// 查询键
type queryKey struct {
Name string
Age int
}
// 创建查询键到数据的映射
var mapper = make(map[queryKey]*Profile)
// 构建查询索引
func buildIndex(list []*Profile) {
// 遍历所有数据
for _, profile := range list {
// 构建查询键
key := queryKey{
Name: profile.Name,
Age: profile.Age,
}
// 保存查询键
mapper[key] = profile
}
}代码说明如下:
第 2 行,与基于哈希值的查询键的结构相同。
第 8 行,在 map 的键类型上,直接使用了查询键结构体。注意,这里不使用查询键的指针。同时,结果只有 Profile 类型,而不是 Profile 切片,表示查到的结果唯一。
第 17 行,类似的,使用遍历到的数据的名字和年龄构建查询键。
第 23 行,更简单的,直接将查询键保存对应的数据。
2) 查询逻辑
// 根据条件查询数据
func queryData(name string, age int) {
// 根据查询条件构建查询键
key := queryKey{name, age}
// 根据键值查询数据
result, ok := mapper[key]
// 找到数据打印出来
if ok {
fmt.Println(result)
} else {
fmt.Println("no found")
}
}代码说明如下:
第 5 行,根据查询条件(名字、年龄)构建查询键。
第 8 行,直接使用查询键在 map 中查询结果。
第 12 行,找到结果直接打印。
第 14 行,没有找到结果打印 no found。
总结
基于哈希值的多键索引查询和利用 map 特性的多键索引查询的代码复杂程度显而易见。聪明的程序员都会利用 Go语言的特性进行快速的多键索引查询。
其实,利用 map 特性的例子中的 map 类型即便修改为下面的格式,也一样可以获得同样的结果:
var mapper = make(map[interface{}]*Profile)代码量大大减少的关键是:Go语言的底层会为 map 的键自动构建哈希值。能够构建哈希值的类型必须是非动态类型、非指针、函数、闭包。
本节将分别为大家讲解 Go语言是如何与 C/C++ 进行交互的。
与 C语言进行交互
工具 cgo 提供了对 FFI(外部函数接口)的支持,能够使用 Go语言代码安全地调用 C语言库,可以访问 cgo 文档主页:https://golang.google.cn/cmd/cgo/。cgo 会替代 Go 编译器来产生可以组合在同一个包中的 Go 和 C 代码。
在实际开发中一般使用 cgo 创建单独的 C 代码包。如果想要在 Go 程序中使用 cgo,则必须在单独的一行使用 import "C" 来导入,一般来说你可能还需要 import "unsafe" 。
然后,可以在 import "C" 之前使用注释(单行或多行注释均可)的形式导入 C语言库(甚至有效的 C语言代码),它们之间没有空行,例如:
// #include <stdio.h>
// #include <stdlib.h>
import "C"名称 "C" 并不属于标准库的一部分,这只是 cgo 集成的一个特殊名称用于引用 C 的命名空间。在这个命名空间里所包含的 C 类型都可以被使用,例如 C.uint 、C.long 等等,还有 libc 中的函数 C.random() 等也可以被调用。
当想要使用某个类型作为 C 中函数的参数时,必须将其转换为 C 中的类型,反之亦然,例如:
var i int
C.uint(i) // 从 Go 中的 int 转换为 C 中的无符号 int
int(C.random()) // 从 C 中 random() 函数返回的 long 转换为 Go 中的 int【示例 1】下面的 2 个 Go 函数 Random() 和 Seed() 分别调用了 C 中的 C.random() 和 C.srandom()。
package rand
// #include <stdlib.h>
import "C"
func Random() int {
return int(C.random())
}
func Seed(i int) {
C.srandom(C.uint(i))
}C语言当中并没有明确的字符串类型,如果你想要将一个 string 类型的变量从 Go 转换到 C 时,可以使用 C.CString(s);同样,可以使用 C.GoString(cs) 从 C 转换到 Go 中的 string 类型。
Go 的内存管理机制无法管理通过 C 代码分配的内存。开发人员需要通过手动调用 C.free 来释放变量的内存:
defer C.free(unsafe.Pointer(Cvariable))这一行最好紧跟在使用 C 代码创建某个变量之后,这样就不会忘记释放内存了。
【示例 2】下面的代码展示了如何使用 cgo 创建变量、使用并释放其内存:
package print
// #include <stdio.h>
// #include <stdlib.h>
import "C"
import "unsafe"
func Print(s string) {
cs := C.CString(s)
defer C.free(unsafe.Pointer(cs))
C.fputs(cs, (*C.FILE)(C.stdout))
}构建 cgo 包
除了使用变量 GOFILES 之外,还需要使用变量 CGOFILES 来列出需要使用 cgo 编译的文件列表。例如,可以使用包含以下内容的 Makefile 文件来编译,可以使用 gomake 或 make:
include $(GOROOT)/src/Make.inc
TARG=rand
CGOFILES=c1.goinclude $(GOROOT)/src/Make.pkg与 C++ 进行交互
SWIG(简化封装器和接口生成器)支持在 Linux 系统下使用 Go语言代码调用 C 或者 C++ 代码。这里有一些使用 SWIG 的注意事项:
这类接口支持方法重载、多重继承以及使用 Go 代码实现 C++ 的抽象类。
目前使用 SWIG 存在的一个问题是它无法支持所有的 C++ 库,比如说它就无法解析 TObject.h。
本节将通过示例来为大家介绍 Go语言中文件读写的相关操作。
读文件
在 Go语言中,文件使用指向 os.File 类型的指针来表示的,也叫做文件句柄。在前面章节使用到过标准输入 os.Stdin 和标准输出 os.Stdout ,他们的类型都是 *os.File 。让我们来看看下面这个程序:
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
inputFile, inputError := os.Open("input.dat")
if inputError != nil {
fmt.Printf("An error occurred on opening the inputfile\n" +
"Does the file exist?\n" +
"Have you got acces to it?\n")
return // exit the function on error
}
defer inputFile.Close()
inputReader := bufio.NewReader(inputFile)
for {
inputString, readerError := inputReader.ReadString('\n')
if readerError == io.EOF {
return
}
fmt.Printf("The input was: %s", inputString)
}
}变量 inputFile 是 *os.File 类型的。该类型是一个结构,表示一个打开文件的描述符(文件句柄)。然后,使用 os 包里的 Open 函数来打开一个文件。该函数的参数是文件名,类型为 string。在上面的程序中,我们以只读模式打开 input.dat 文件。
如果文件不存在或者程序没有足够的权限打开这个文件,Open 函数会返回一个错误:
inputFile, inputError = os.Open("input.dat")如果文件打开正常,我们就使用 defer.Close() 语句确保在程序退出前关闭该文件。然后,我们使用 bufio.NewReader 来获得一个读取器变量。
通过使用 bufio 包提供的读取器(写入器也类似),如上面程序所示,我们可以很方便的操作相对高层的 string 对象,而避免了去操作比较底层的字节。
接着,我们在一个无限循环中使用 ReadString(‘\n‘) 或 ReadBytes(‘\n‘) 将文件的内容逐行(行结束符 ‘\n‘)读取出来。
注意:在之前的例子中,我们看到,Unix 和 Linux 的行结束符是 \n,而 Windows 的行结束符是 \r\n。在使用 ReadString 和 ReadBytes 方法的时候,我们不需要关心操作系统的类型,直接使用 \n 就可以了。另外,我们也可以使用 ReadLine() 方法来实现相同的功能。
一旦读取到文件末尾,变量 readerError 的值将变成非空(事实上,常亮 io.EOF 的值是 true),我们就会执行 return 语句从而退出循环。
其他类似函数:
1) 将整个文件的内容读到一个字符串里
如果想将整个文件的内容读到一个字符串里,可以使用 io/ioutil 包里的 ioutil.ReadFile() 方法,该方法第一个返回值的类型是 []byte ,里面存放读取到的内容,第二个返回值是错误,如果没有错误发生,第二个返回值为 nil。
【示例 1】使用函数 WriteFile() 将 []byte 的值写入文件。
package main
import (
"fmt"
"io/ioutil"
"os"
)
func main() {
inputFile := "products.txt"
outputFile := "products_copy.txt"
buf, err := ioutil.ReadFile(inputFile)
if err != nil {
fmt.Fprintf(os.Stderr, "File Error: %s\n", err)
// panic(err.Error())
}
fmt.Printf("%s\n", string(buf))
err = ioutil.WriteFile(outputFile, buf, 0x644)
if err != nil {
panic(err. Error())
}
}2) 带缓冲的读取
在很多情况下,文件的内容是不按行划分的,或者干脆就是一个二进制文件。在这种情况下,ReadString() 就无法使用了,我们可以使用 bufio.Reader 的 Read() ,它只接收一个参数:
buf := make([]byte, 1024)
...
n, err := inputReader.Read(buf)
if (n == 0) { break}变量 n 的值表示读取到的字节数.
3) 按列读取文件中的数据
如果数据是按列排列并用空格分隔的,你可以使用 fmt 包提供的以 FScan 开头的一系列函数来读取他们。
【示例 2】将 3 列的数据分别读入变量 v1、v2 和 v3 内,然后分别把他们添加到切片的尾部。
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("products2.txt")
if err != nil {
panic(err)
}
defer file.Close()
var col1, col2, col3 []string
for {
var v1, v2, v3 string
_, err := fmt.Fscanln(file, &v1, &v2, &v3)
// scans until newline
if err != nil {
break
}
col1 = append(col1, v1)
col2 = append(col2, v2)
col3 = append(col3, v3)
}
fmt.Println(col1)
fmt.Println(col2)
fmt.Println(col3)
}输出结果:
[ABC FUNC GO]
[40 56 45]
[150 280 356]注意:path 包里包含一个子包叫 filepath ,这个子包提供了跨平台的函数,用于处理文件名和路径。例如 Base() 函数用于获得路径中的最后一个元素(不包含后面的分隔符):
import "path/filepath"
filename := filepath.Base(path)compress 包:读取压缩文件
compress 包提供了读取压缩文件的功能,支持的压缩文件格式为:bzip2、flate、gzip、lzw 和 zlib。
【示例 3】使用 Go语言读取一个 gzip 文件。
package main
import (
"fmt"
"bufio"
"os"
"compress/gzip"
)
func main() {
fName := "MyFile.gz"
var r *bufio.Reader
fi, err := os.Open(fName)
if err != nil {
fmt.Fprintf(os.Stderr, "%v, Can't open %s: error: %s\n", os.Args[0], fName,
err)
os.Exit(1)
}
fz, err := gzip.NewReader(fi)
if err != nil {
r = bufio.NewReader(fi)
} else {
r = bufio.NewReader(fz)
}
for {
line, err := r.ReadString('\n')
if err != nil {
fmt.Println("Done reading file")
os.Exit(0)
}
fmt.Println(line)
}
}写文件
请看以下程序:
package main
import (
"os"
"bufio"
"fmt"
)
func main () {
// var outputWriter *bufio.Writer
// var outputFile *os.File
// var outputError os.Error
// var outputString string
outputFile, outputError := os.OpenFile("output.dat", os.O_WRONLY|os.O_CREATE, 0666)
if outputError != nil {
fmt.Printf("An error occurred with file opening or creation\n")
return
}
defer outputFile.Close()
outputWriter := bufio.NewWriter(outputFile)
outputString := "hello world!\n"
for i:=0; i<10; i++ {
outputWriter.WriteString(outputString)
}
outputWriter.Flush()
}除了文件句柄,我们还需要 bufio 的写入器。我们以只读模式打开文件 output.dat ,如果文件不存在则自动创建:
outputFile, outputError := os.OpenFile(“output.dat”, os.O_WRONLY|os.O_ CREATE, 0666)可以看到,OpenFile 函数有三个参数:文件名、一个或多个标志(使用逻辑运算符“|”连接),使用的文件权限。
我们通常会用到以下标志:
在读文件的时候,文件的权限是被忽略的,所以在使用 OpenFile 时传入的第三个参数可以用 0。而在写文件时,不管是 Unix 还是 Windows,都需要使用 0666。
然后,我们创建一个写入器(缓冲区)对象:
outputWriter := bufio.NewWriter(outputFile)接着,使用一个 for 循环,将字符串写入缓冲区,写 10 次:
outputWriter.WriteString(outputString)缓冲区的内容紧接着被完全写入文件:outputWriter.Flush()
如果写入的东西很简单,我们可以使用fmt.Fprintf(outputFile, “Some test data.\n”)直接将内容写入文件。fmt 包里的 F 开头的 Print 函数可以直接写入任何 io.Writer,包括文件。
【示例 4】不使用 fmt.FPrintf 函数,使用其他函数如何写文件:
package main
import "os"
func main() {
os.Stdout.WriteString("hello, world\n")
f, _ := os.OpenFile("test", os.O_CREATE|os.O_WRONLY, 0)
defer f.Close()
f.WriteString("hello, world in a file\n")
}使用os.Stdout.WriteString("hello, world\n"),我们可以输出到屏幕。以只写模式创建或打开文件“test”,并且忽略了可能发生的错误:
f, _ := os.OpenFile(“test”, os.O_CREATE|os.O_WRONLY, 0)不使用缓冲区,直接将内容写入文件:f.WriteString()
数据结构要在网络中传输或保存到文件,就必须对其编码和解码;目前存在很多编码格式:JSON,XML,gob,Google 缓冲协议等等。Go语言支持所有这些编码格式。
结构可能包含二进制数据,如果将其作为文本打印,那么可读性是很差的。另外结构内部可能包含匿名字段,而不清楚数据的用意。
通过把数据转换成纯文本,使用命名的字段来标注,让其具有可读性。这样的数据格式可以通过网络传输,而且是与平台无关的,任何类型的应用都能够读取和输出,不与操作系统和编程语言的类型相关。
下面是一些术语说明:
数据结构 --> 指定格式 = 序列化 或 编码(传输之前)
指定格式 --> 数据格式 = 反序列化 或 解码(传输之后)
序列化是在内存中把数据转换成指定格式(data -> string),反之亦然(string -> data structure)编码也是一样的,只是输出一个数据流(实现了 io.Writer 口);解码是从一个数据流(实现了
io.Reader)输出到一个数据结构。
也许大家比较熟悉 XML 格式,但有些时候 JSON 格式被作为首选,主要是由于其格式上非常简洁。通常 JSON 被用于 web 后端和浏览器之间的通讯,但是在其它场景也同样的有用。
这是一个简短的 JSON 片段:
{
"Person": {
"FirstName": "Laura",
"LastName": "Lynn"
}
}尽管 XML 被广泛的应用,但是 JSON 更加简洁、轻量(占用更少的内存、磁盘及网络带宽)和更好的可读性,这也说明它越来越受欢迎。
Go语言的 json 包可以让你在程序中方便的读取和写入 JSON 数据。代码如下所示:
// json.go.go
package main
import (
"encoding/json"
"fmt"
"log"
"os"
)
type Address struct {
Type string
City string
Country string
}
type VCard struct {
FirstName string
LastName string
Addresses []*Address
Remark string
}
func main() {
pa := &Address{"private", "Aartselaar", "Belgium"}
wa := &Address{"work", "Boom", "Belgium"}
vc := VCard{"Jan", "Kersschot", []*Address{pa, wa}, "none"}
// fmt.Printf("%v: \n", vc) // {Jan Kersschot [0x126d2b80 0x126d2be0] none}:
// JSON format:
js, _ := json.Marshal(vc)
fmt.Printf("JSON format: %s", js)
// using an encoder:
file, _ := os.OpenFile("vcard.json", os.O_CREATE|os.O_WRONLY, 0)
defer file.Close()
enc := json.NewEncoder(file)
err := enc.Encode(vc)
if err != nil {
log.Println("Error in encoding json")
}
}json.Marshal() 的函数签名是func Marshal(v interface{}) ([]byte, error),下面是数据编码后的 JSON 文本(实际上是一个 []bytes):
{
"FirstName": "Jan",
"LastName": "Kersschot",
"Addresses": [{
"Type": "private",
"City": "Aartselaar",
"Country": "Belgium"
}, {
"Type": "work",
"City": "Boom",
"Country": "Belgium"
}],
"Remark": "none"
}出于安全考虑,在 web 应用中最好使用json.MarshalforHTML() 函数,其对数据执行 HTML 转码,所以文本可以被安全地嵌在 HTML <script> 标签中。
JSON 与 Go 类型对应如下:
不是所有的数据都可以编码为 JSON 类型:只有验证通过的数据结构才能被编码:
反序列化:
UnMarshal() 的函数签名是func Unmarshal(data []byte, v interface{}) error把 JSON 解码为数据结构。
我们首先创建一个结构 Message 用来保存解码的数据:var m Message 并调用 Unmarshal(),解析 []byte 中的 JSON 数据并将结果存入指针 m 指向的值。
虽然反射能够让 JSON 字段去尝试匹配目标结构字段;但是只有真正匹配上的字段才会填充数据。字段没有匹配不会报错,而是直接忽略掉。
解码任意的数据:
json 包使用 map[string]interface{} 和 []interface{} 储存任意的 JSON 对象和数组;其可以被反序列化为任何的 JSON blob 存储到接口值中。
来看这个 JSON 数据,被存储在变量 b 中:
b == []byte({"Name": "Wednesday", "Age": 6, "Parents": ["Gomez", "Morticia"]})不用理解这个数据的结构,我们可以直接使用 Unmarshal 把这个数据编码并保存在接口值中:
var f interface{}
err := json.Unmarshal(b, &f)f 指向的值是一个 map,key 是一个字符串,value 是自身存储作为空接口类型的值:
map[string]interface{} {
"Name": "Wednesday",
"Age": 6,
"Parents": []interface{} {
"Gomez",
"Morticia",
},
}要访问这个数据,我们可以使用类型断言。
m := f.(map[string]interface{})我们可以通过 for range 语法和 type switch 来访问其实际类型:
for k, v := range m {
switch vv := v.(type) {
case string:
fmt.Println(k, "is string", vv)
case int:
fmt.Println(k, "is int", vv)
case []interface{}:
fmt.Println(k, "is an array:")
for i, u := range vv {
fmt.Println(i, u)
}
default:
fmt.Println(k, "is of a type I don’t know how to handle")
}
}通过这种方式,可以处理未知的 JSON 数据,同时可以确保类型安全。
解码数据到结构:
如果我们事先知道 JSON 数据,可以定义一个适当的结构并对 JSON 数据反序列化。下面的例子中,我们将定义:
type FamilyMember struct {
Name string
Age int
Parents []string
}并对其反序列化:
var m FamilyMember
err := json.Unmarshal(b, &m)程序实际上是分配了一个新的切片。这是一个典型的反序列化引用类型(指针、切片和 map)的例子。
编码和解码流
json 包提供 Decoder 和 Encoder 类型来支持常用 JSON 数据流读写。NewDecoder 和 NewEncoder 函数分别封装了 io.Reader 和 io.Writer 接口。
func NewDecoder(r io.Reader) *Decoder
func NewEncoder(w io.Writer) *Encoder要想把 JSON 直接写入文件,可以使用 json.NewEncoder 初始化文件(或者任何实现 io.Writer 的类型),并调用 Encode();反过来与其对应的是使用 json.Decoder 和 Decode() 函数:
func NewDecoder(r io.Reader) *Decoder
func (dec *Decoder) Decode(v interface{}) error来看下接口是如何对实现进行抽象的:数据结构可以是任何类型,只要其实现了某种接口,目标或源数据要能够被编码就必须实现 io.Writer 或 io.Reader 接口。由于 Go语言中到处都实现了 Reader 和 Writer,因此 Encoder 和 Decoder 可被应用的场景非常广泛,例如读取或写入 HTTP 连接、websockets 或文件。
从不同的并发执行的协程中获取值可以通过关键字 select 来完成,它和 switch 控制语句非常相似也被称作通信开关;它的行为像是“你准备好了吗”的轮询机制;select 监听进入通道的数据,也可以是用通道发送值的时候。
select {
case u:= <- ch1:
...
case v:= <- ch2:
...
...
default: // no value ready to be received
...
}default 语句是可选的;fallthrough 行为,和普通的 switch 相似,是不允许的。在任何一个 case 中执行 break 或者 return,select 就结束了。
select 做的就是:选择处理列出的多个通信情况中的一个。
在 select 中使用发送操作并且有 default 可以确保发送不被阻塞!如果没有 case,select 就会一直阻塞。
select 语句实现了一种监听模式,通常用在(无限)循环中;在某种情况下,通过 break 语句使循环退出。
在下面的示例程序中有 2 个通道 ch1 和 ch2 ,三个协程 pump1() 、pump2() 和 suck() 。这是一个典型的生产者消费者模式。在无限循环中,ch1 和 ch2 通过 pump1() 和 pump2() 填充整数;suck() 也是在无限循环中轮询输入的,通过 select 语句获取 ch1 和 ch2 的整数并输出。选择哪一个 case 取决于哪一个通道收到了信息。程序在 main 执行 1 秒后结束。
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go pump1(ch1)
go pump2(ch2)
go suck(ch1, ch2)
time.Sleep(1e9)
}
func pump1(ch chan int) {
for i := 0; ; i++ {
ch <- i * 2
}
}
func pump2(ch chan int) {
for i := 0; ; i++ {
ch <- i + 5
}
}
func suck(ch1, ch2 chan int) {
for {
select {
case v := <-ch1:
fmt.Printf("Received on channel 1: %d\n", v)
case v := <-ch2:
fmt.Printf("Received on channel 2: %d\n", v)
}
}
}输出:
Received on channel 2: 5
Received on channel 2: 6
Received on channel 1: 0
Received on channel 2: 7
Received on channel 2: 8
Received on channel 2: 9
Received on channel 2: 10
Received on channel 1: 2
Received on channel 2: 11
...
Received on channel 2: 47404
Received on channel 1: 94346
Received on channel 1: 94348一秒内的输出非常惊人,如果我们给它计数,得到了 90000 个左右的数字。
一般的 HTTPS 是基于 SSL(Secure Sockets Layer)协议。SSL 是网景公司开发的位于 TCP 与 HTTP 之间的透明安全协议,通过 SSL,可以把 HTTP 包数据以非对称加密的形式往返于浏览器和站点之间,从而避免被第三方非法获取。
目前,伴随着电子商务的兴起,HTTPS 获得了广泛的应用。由 IETF(Internet Engineering Task Force)实现的 TLS(Transport Layer Security)是建立于 SSL v3.0 之上的兼容协议,它们主要的区别在于所支持的加密算法。
加密通信流程
当用户在浏览器中输入一个以 https 开头的网址时,便开启了浏览器与被访问站点之间的加密通信。下面我们以一个用户访问 https://qbox.me 为例,为大家展现一下 SSL/TLS 的工作方式。
1) 在浏览器中输入 HTTPS 协议的网址,如下图所示。
2) 服务器向浏览器返回证书,浏览器检查该证书的合法性,如下图所示。
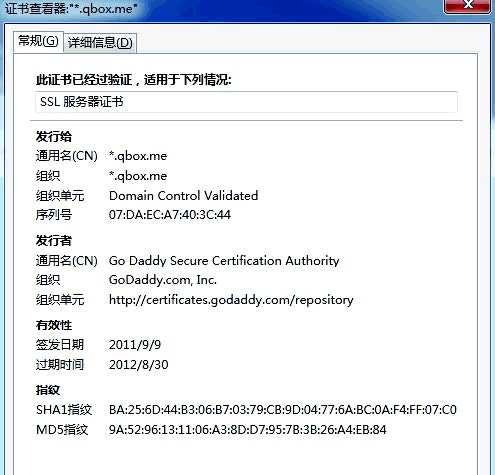
3) 验证合法性,如下图所示。
4) 浏览器使用证书中的公钥加密一个随机对称密钥,并将加密后的密钥和使用密钥加密后的请求 URL 一起发送到服务器。
5) 服务器用私钥解密随机对称密钥,并用获取的密钥解密加密的请求 URL。
6) 服务器把用户请求的网页用密钥加密,并返回给用户。
7) 用户浏览器用密钥解密服务器发来的网页数据,并将其显示出来。
上述过程都是依赖于 SSL/TLS 层实现的。在实际开发中,SSL/TLS 的实现和工作原理比较复杂,但基本流程与上面的过程一致。
SSL 协议由两层组成,上层协议包括 SSL 握手协议、更改密码规格协议、警报协议,下层协议包括 SSL 记录协议。
SSL 握手协议建立在 SSL 记录协议之上,在实际的数据传输开始前,用于在客户与服务器之间进行“握手”。“握手”是一个协商过程。这个协议使得客户和服务器能够互相鉴别身份,协商加密算法。在任何数据传输之前,必须先进行“握手”。
在“握手”完成之后,才能进行 SSL 记录协议,它的主要功能是为高层协议提供数据封装、压缩、添加MAC、加密等支持。
支持 HTTPS 的 Web 服务器
Go语言目前实现了 TLS 协议的部分功能,已经可以提供最基础的安全层服务。下面我们来看一下如何实现支持 TLS 的 Web 服务器。下面的代码示范了如何使用 http.ListenAndServerTLS 实现一个支持 HTTPS 的 Web 服务器。
package main
import (
"fmt"
"net/http"
)
const SERVER_PORT = 8080
const SERVER_DOMAIN = "localhost"
const RESPONSE_TEMPLATE = "hello"
func rootHandler(w http.ResponseWriter, req *http.Request) {
w.Header().Set("Content-Type", "text/html")
w.Header().Set("Content-Length", fmt.Sprint(len(RESPONSE_TEMPLATE)))
w.Write([]byte(RESPONSE_TEMPLATE))
}
func main() {
http.HandleFunc(fmt.Sprintf("%s:%d/", SERVER_DOMAIN, SERVER_PORT), rootHandler)
http.ListenAndServeTLS(fmt.Sprintf(":%d", SERVER_PORT), "rui.crt", "rui.key", nil)
}运行该服务器后,我们可以在浏览器中访问 localhost:8080 并查看访问效果,如下图所示。
可以看到,我们使用了 http.ListenAndServerTLS() 这个方法,这表明它是执行在 TLS 层上的 HTTP 协议。如果我们并不需要支持 HTTPS,只需要把该方法替换为 http.ListenAndServeTLS(fmt.Sprintf(":%d", SERVER_PORT), nil)即可。
下面的代码示范了如何实现基于 TCP 和 TLS 的 Web 服务器。这个程序的执行效果与上一个例子相同。可以认为它是一种更深入的原理性说明,揭示了基于 TLS 的 HTTPS 的实现细节。
package main
import (
"net"
"net/http"
"time"
"fmt"
"crypto/x509"
"crypto/rand"
"crypto/rsa"
"crypto/tls"
"encoding/pem"
"errors"
"io/ioutil"
)
const SERVER_PORT = 8080
const SERVER_DOMAIN = "localhost"
const RESPONSE_TEMPLATE = "hello"
func rootHandler(w http.ResponseWriter, req *http.Request){
w.Header().Set("Content-Type", "text/html")
w.Header().Set("Content-Length", fmt.Sprint(len(RESPONSE_TEMPLATE)))
w.Write([]byte(RESPONSE_TEMPLATE))
}
func YourListenAndServeTLS(addr string, certFile string, keyFile string, handler
http.Handler) error {
config := &tls.Config{
Rand: rand.Reader,
Time: time.Now,
NextProtos: []string{"http/1.1"},
}
var err error
config.Certificates = make([]tls.Certificate, 1)
config.Certificates[0], err = YourLoadX509KeyPair(certFile, keyFile)
if err != nil {
return err
}
conn, err := net.Listen("tcp", addr)
if err != nil {
return errs
}
tlsListener := tls.NewListener(conn, config)
return http.Serve(tlsListener, handler)
}
func YourLoadX509KeyPair(certFile string, keyFile string) (cert tls.Certificate, err
error) {
certPEMBlock, err := ioutil.ReadFile(certFile)
if err != nil {
return
}
certDERBlock, restPEMBlock := pem.Decode(certPEMBlock)
if certDERBlock == nil {
err = errors.New("crypto/tls: failed to parse certificate PEM data")
return
}
certDERBlockChain, _ := pem.Decode(restPEMBlock)
if certDERBlockChain == nil {
cert.Certificate = [][]byte{certDERBlock.Bytes}
} else {
cert.Certificate = [][]byte{certDERBlock.Bytes,
certDERBlockChain.Bytes}
}
keyPEMBlock, err := ioutil.ReadFile(keyFile)
if err != nil {
return
}
keyDERBlock, _ := pem.Decode(keyPEMBlock)
if keyDERBlock == nil {
err = errors.New("crypto/tls: failed to parse key PEM data")
return
}
key, err := x509.ParsePKCS1PrivateKey(keyDERBlock.Bytes)
if err != nil {
err = errors.New("crypto/tls: failed to parse key")
return
}
cert.PrivateKey = key
x509Cert, err := x509.ParseCertificate(certDERBlock.Bytes)
if err != nil {
return
}
if x509Cert.PublicKeyAlgorithm != x509.RSA ||
x509Cert.PublicKey.(*rsa.PublicKey).N.Cmp(key.PublicKey.N) != 0 {
err = errors.New("crypto/tls: private key does not match public key")
return
}
return
}
func main() {
http.HandleFunc(fmt.Sprintf("%s:%d/", SERVER_DOMAIN, SERVER_PORT), rootHandler);
YourListenAndServeTLS(fmt.Sprintf(":%d", SERVER_PORT), "rui.crt", "rui.key", nil)
}本例中用到了 crypto 中的一些包,下面对此做一些解释:
rand,伪随机函数发生器,用于产生基于时间和 CPU 时钟的伪随机数;
rsa,非对称加密算法,rsa 是三个发明者名字的首字母拼接而成;
tls,我们在上面已介绍过,它是传输层安全协议;
x509,一种常用的数字证书格式;
pem,在非对称加密体系下,一般用于存放公钥和私钥的文件。
支持 HTTPS 的文件服务器
利用 Go语言标准库中提供的完备封装,我们也可以很容易实现一个支持 HTTPS 的文件服务器,代码如下所示。
package main
import (
"net/http"
)
func main(){
h := http.FileServer(http.Dir("."))
http.ListenAndServeTLS(":8001", "rui.crt", "rui.key", h)
}运行效果如下图所示。
基于 SSL/TLS 的 ECHO 程序
在本章最后,我们用一个完整的安全版 ECHO 程序来演示如何让 Socket 通信也支持 HTTPS。当然,ECHO 程序支持 HTTPS 似乎没有什么必要,但这个程序可以比较容易地改造成有实际价值的程序,比如安全的聊天工具等。
下面我们首先实现这个超级 ECHO 程序的服务器端,代码如下所示。
package main
import (
"crypto/rand"
"crypto/tls"
"io"
"log"
"net"
"time"
)
func main() {
cert, err := tls.LoadX509KeyPair("rui.crt", "rui.key")
if err != nil {
log.Fatalf("server: loadkeys: %s", err)
}
config := tls.Config{Certificates:[]tls.Certificate{cert}}
config.Time = time.Now
config.Rand = rand.Reader
service := "127.0.0.1:8000"
listener, err := tls.Listen("tcp", service, &config)
if err != nil {
log.Fatalf("server: listen: %s", err)
}
log.Print("server: listening")
for {
conn, err := listener.Accept()
if err != nil {
log.Printf("server: accept: %s", err)
break
}
log.Printf("server: accepted from %s", conn.RemoteAddr())
go handleClient(conn)
}
}
func handleClient(conn net.Conn) {
defer conn.Close()
buf := make([]byte, 512)
for {
log.Print("server: conn: waiting")
n, err := conn.Read(buf)
if err != nil {
if err != io.EOF {
log.Printf("server: conn: read: %s", err)
}
break
}
log.Printf("server: conn: echo %q\n", string(buf[:n]))
n, err = conn.Write(buf[:n])
log.Printf("server: conn: wrote %d bytes", n)
if err != nil {
log.Printf("server: write: %s", err)
break
}
}
log.Println("server: conn: closed")
}现在服务器端已经实现了。我们再实现超级 ECHO 的客户端,代码如下所示。
package main
import (
"crypto/tls"
"io"
"log"
)
func main() {
conn, err := tls.Dial("tcp", "127.0.0.1:8000", nil)
if err != nil {
log.Fatalf("client: dial: %s", err)
}
defer conn.Close()
log.Println("client: connected to: ", conn.RemoteAddr())
state := conn.ConnectionState()
log.Println("client: handshake: ", state.HandshakeComplete)
log.Println("client: mutual: ", state.NegotiatedProtocolIsMutual)
message := "Hello\n"
n, err := io.WriteString(conn, message)
if err != nil {
log.Fatalf("client: write: %s", err)
}
log.Printf("client: wrote %q (%d bytes)", message, n)
reply := make([]byte, 256)
n, err = conn.Read(reply)
log.Printf("client: read %q (%d bytes)", string(reply[:n]), n)
log.Print("client: exiting")
}接下来我们分别编译和运行服务器端和客户端程序,可以看到类似以下的运行效果。
服务器端的输出结果为:
$ 6.out.exe
2012/04/06 13:48:24 server: listening
2012/04/06 13:50:41 server: accepted from 127.0.0.1:15056
2012/04/06 13:50:41 server: conn: waiting
2012/04/06 13:50:41 server: conn: echo "Hello\n"
2012/04/06 13:50:41 server: conn: wrote 6 bytes
2012/04/06 13:50:41 server: conn: waiting
2012/04/06 13:50:41 server: conn: closed客户端的输出结果为:
$ 8.exe
2012/04/06 13:50:41 client: connected to: 127.0.0.1:8000
2012/04/06 13:50:41 client: handshake: true
2012/04/06 13:50:41 client: mutual: true
2012/04/06 13:50:41 client: wrote "Hello\n" (6 bytes)
2012/04/06 13:50:41 client: read "Hello\n" (6 bytes)
2012/04/06 13:50:41 client: exiting需要注意的是,SSL/TLS 协议只能运行于 TCP 之上,不能在 UDP 上工作,且 SSL/TLS 位于 TCP 与应用层协议之间,因此所有基于 TCP 的应用层协议都可以透明地使用 SSL/TLS 为自己提供安全保障。所谓透明地使用是指既不需要了解细节,也不需要专门处理该层的包,比如封装、解封等。
内存管理是非常重要的一个话题。关于编程语言是否应该支持垃圾回收就有个搞笑的争论,一派人认为,内存管理太重要了,而手动管理麻烦且容易出错,所以我们应该交给机器去管理。另一派人则认为,内存管理太重要了!所以如果交给机器管理我不能放心。争论归争论,但不管哪一派,大家对内存管理重要性的认同都是勿庸质疑的。
Go语言是一门带垃圾回收的语言,Go语言中有指针,却没有 C 中那么灵活的指针操作。大多数情况下是不需要用户自己去管理内存的,但是理解 Go语言是如何做内存管理对于写出优秀的程序是大有帮助的。
内存池概述
Go语言的内存分配器采用了跟 tcmalloc 库相同的实现,是一个带内存池的分配器,底层直接调用操作系统的 mmap 等函数。
作为一个内存池,回忆一下跟它相关的基本部分。首先,它会向操作系统申请大块内存,自己管理这部分内存。然后,它是一个池子,当上层释放内存时它不实际归还给操作系统,而是放回池子重复利用。
接着,内存管理中必然会考虑的就是内存碎片问题,如果尽量避免内存碎片,提高内存利用率,像操作系统中的首次适应,最佳适应,最差适应,伙伴算法都是一些相关的背景知识。
另外,Go语言是一个支持 goroutine 这种多线程的语言,所以它的内存管理系统必须也要考虑在多线程下的稳定性和效率问题。
在多线程方面,很自然的做法就是每条线程都有自己的本地的内存,然后有一个全局的分配链,当某个线程中内存不足后就向全局分配链中申请内存。这样就避免了多线程同时访问共享变量时的加锁。
在避免内存碎片方面,大块内存直接按页为单位分配,小块内存会切成各种不同的固定大小的块,申请做任意字节内存时会向上取整到最接近的块,将整块分配给申请者以避免随意切割。
Go中为每个系统线程分配一个本地的 MCache(前面介绍的结构体 M 中的 MCache 域),少量的地址分配就直接从 MCache 中分配,并且定期做垃圾回收,将线程的 MCache 中的空闲内存返回给全局控制堆。
小于 32K 为小对象,大对象直接从全局控制堆上以页(4k)为单位进行分配,也就是说大对象总是以页对齐的。一个页可以存入一些相同大小的小对象,小对象从本地内存链表中分配,大对象从中心内存堆中分配。
大约有 100 种内存块类别,每一类别都有自己对象的空闲链表。小于 32kB 的内存分配被向上取整到对应的尺寸类别,从相应的空闲链表中分配。一页内存只可以被分裂成同一种尺寸类别的对象,然后由空闲链表分配器管理。
分配器的数据结构包括:
我们可以将 Go语言的内存管理看成一个两级的内存管理结构,MHeap 和 MCache。上面一级管理的基本单位是页,用于分配大对象,每次分配都是若干连续的页,也就是若干个 4KB 的大小。
使用的数据结构是 MHeap 和 MSpan,用 BestFit 算法做分配,用位示图做回收。下面一级管理的基本单位是不同类型的固定大小的对象,更像一个对象池而不是内存池,用引用计数做回收。下面这一级使用的数据结构是 MCache。
MHeap
MHeap 层次用于直接分配较大 (>32kB) 的内存空间,以及给 MCentral 和 MCache 等下层提供空间。它管理的基本单位是 MSpan。MSpan 是一个表示若干连续内存页的数据结构,简化后如下:
struct MSpan
{
PageID start; // starting page number
uintptr npages; // number of pages in span
};通过一个基地址 +(页号*页大小),就可以定位到这个 MSpan 的实际的地址空间了,基地址是在 MHeap 中存储了的。
MHeap 负责将 MSpan 组织和管理起来,MHeap 数据结构中的重要部分如图所示。
free 是一个分配池,从 free[i]出去的 MSpan 每个大小都 i 页的,总共 256 个槽位。再大了之后,大小就不固定了,由 large 链起来。
分配过程:如果能从 free[] 的分配池中分配,则从其中分配。如果发生切割则将剩余部分放回 free[] 中。比如要分配 2 页大小的空间,从图上 2 号槽位开始寻找,直到 4 号槽位有可用的 MSpan,则拿一个出来,切出两页,剩余的部分再放回 2 号槽位中。否则从 large 链表中去分配,按 BestFit 算法去找一块可用空间。
化整为零简单,化零为整麻烦。回收的时候如果相邻的块是未使用的,要进行合并,否则一直划分下去就会产生很多碎片,找不到一个足够大小的连续空间。因为涉及到合并,回收会比分配复杂一些,所有就有什么伙伴算法,边界标识算法,位示图之类的。
Go 在这里使用的类似于位示图。可以看到 MHeap 中有一个
MSpan *map[1<<MHeapMap_Bits];这个数组是一个用于将内存地址映射成 MSpan 结构体的表,每个内存页都会对应到 map 中的一个 MSpan 指针,通过 map 就能够将地址映射到相应的 MSpan。
具体做法,给定一个地址,可以通过(地址-基地址)/ 页大小得到页号,再通过 map[页号] 就得到了相应的 MSpan 结构体。
前面说过,MSpan 就是若干连续的页。那么,一个多页的 MSpan 会占用 map 数组中的多项,有多少页就会占用多少项。比如,可能 map[502] 到 map[505] 都指向同一个 MSpan,这个 MSpan 的 PageId 为 502,npages 为 4。
回收过程:回收一个 MSpan 时,首先会查找它相邻的页的址址,再通过 map 映射得到该页对应的 MSpan,如果 MSpan 的 state 是未使用,则可以将两者进行合并。最后会将这页或者合并后的页归还到 free[] 分配池或者是 large 中。
MCache
MCache 层次跟 MHeap 层次非常像,也是一个分配池,对每个尺寸的类别都有一个空闲对象的单链表。Go 的内存管理可以看成一个两级的层次,上面一级是 MHeap 层次,而 MCache 则是下面一级。
每个 M 都有一个自己的局部内存缓存 MCache,这样分配小对象的时候直接从 MCache 中分配,就不用加锁了,这是 Go 能够在多线程环境中高效地进行内存分配的重要原因。MCache 是用于小对象的分配。
分配一个小对象 (<32kB) 的过程:
注意上面表述中的用词“一些”。从 MCentral 中拿“一些“自由链对象补充 MCache 分摊了访问 MCentral 加锁的开销。从 MHeap 中分配“一些“的页补充 MCentral 分摊了对 MHeap 加锁的开销。
释放一个小对象也是类似的过程:
归还到 MHeap 就结束了,目前还是没有归还到操作系统。
MCache 层次仅用于分配小对象,分配和释放大的对象则是直接使用 MHeap 的,跳过 MCache 和 MCentral 自由链。MCache 和 MCentral 中自由链的小对象可能是也可能不是清 0 了的。对象的第 2 个字节作为标记,当它是 0 时,此对象是清 0 了的。页堆中的总是清零的,当一定范围的对象归还到页堆时,需要先清零。这样才符合 Go语言规范:分配一个对象不进行初始化,它的默认值是该类型的零值。
MCentral
MCentral 层次是作为 MCache 和 MHeap 的连接。对上,它从 MHeap 中申请 MSpan; 对下,它将 MSpan 划分成各种小尺寸对象,提供给 MCache 使用。
struct MCentral
{
Lock;
int32 sizeclass;
MSpan nonempty;
MSpan empty;
int32 nfree;
};注意,每个 MSpan 只会分割成同种大小的对象。每个 MCentral 也是只含同种大小的对象。MCentral 结构中,有一个 nonempty 的 MSpan 链和一个 empty 的 MSpan 链,分别表示还有空间的 MSpan 和装满了对象的 MSpan。
分配还是很简单,直接从 MCentral->nonempty->freelist 分配。如果发现 freelist 空了,则说明这一块 MSpan 满了,将它移到 MCentral->empty。
前面说过,回收比分配复杂,因为涉及到合并。这里的合并是通过引用计数实现的。从 MSpan 中每划出一个对象,则引用计数加一,每回收一个对象,则引用计数减一。如果减完之后引用计数为零了,则说明这整块的 MSpan 已经没被使用了,可以将它归还给 MHeap。
Go语言中使用的垃圾回收使用的是标记清扫算法。进行垃圾回收时会 stoptheworld。不过,在当前 1.3 版本中,实现了精确的垃圾回收和并行的垃圾回收,大大地提高了垃圾回收的速度,进行垃圾回收时系统并不会长时间卡住。
标记清扫算法
标记清扫算法是一个很基础的垃圾回收算法,该算法中有一个标记初始的 root 区域,以及一个受控堆区。root 区域主要是程序运行到当前时刻的栈和全局数据区域。在受控堆区中,很多数据是程序以后不需要用到的,这类数据就可以被当作垃圾回收了。
判断一个对象是否为垃圾,就是看从 root 区域的对象是否有直接或间接的引用到这个对象。如果没有任何对象引用到它,则说明它没有被使用,因此可以安全地当作垃圾回收掉。
标记清扫算法分为两阶段:标记阶段和清扫阶段。标记阶段,从 root 区域出发,扫描所有 root 区域的对象直接或间接引用到的对象,将这些对上全部加上标记。在回收阶段,扫描整个堆区,对所有无标记的对象进行回收。
位图标记和内存布局
既然垃圾回收算法要求给对象加上垃圾回收的标记,显然是需要有标记位的。一般的做法会将对象结构体中加上一个标记域,一些优化的做法会利用对象指针的低位进行标记,这都只是些奇技淫巧罢了。Go 没有这么做,它的对象和 C 的结构体对象完全一致,使用的是非侵入式的标记位,我们看看它是怎么实现的。
堆区域对应了一个标记位图区域,堆中每个字 (不是 byte,而是 word) 都会在标记位区域中有对应的标记位。每个机器字 (32 位或 64 位)会对应4位的标记位。因此,64 位系统中相当于每个标记位图的字节对应 16 个堆中的字节。
虽然是一个堆字节对应 4 位标记位,但标记位图区域的内存布局并不是按 4 位一组,而是 16 个堆字节为一组,将它们的标记位信息打包存储的。每组 64 位的标记位图从上到下依次包括:
这样设计使得对一个类型的相应的位进行遍历很容易。
前面提到堆区域和堆地址的标记位图区域是分开存储的,其实它们是以 mheap.arena_start 地址为边界,向上是实际使用的堆地址空间,向下则是标记位图区域。以 64 位系统为例,计算堆中某个地址的标记位的公式如下:
偏移 = 地址 - mheap.arena_start
标记位地址 = mheap.arena_start - 偏移/16 - 1
移位 = 偏移 % 16
标记位 = *标记位地址 >> 移位然后就可以通过 (标记位 & 垃圾回收标记位),(标记位 & 分配位),等来测试相应的位。其中已分配的标记为 1<<0,无指针/块边界是 1<<16,垃圾回收的标记位为 1<<32,特殊位 1<<48。
精确的垃圾回收
像 C 这种不支持垃圾回收的语言,其实还是有些垃圾回收的库可以使用的。这类库一般也是用的标记清扫算法实现的,但是它们都是保守的垃圾回收。为什么叫“保守”的垃圾回收呢?之所以叫“保守”是因为它们没办法获取对象类型信息,因此只能保守地假设地址区间中每个字都是指针。
无法获取对象的类型信息会造成什么问题呢?这里举两个例子来说明。先看第一个例子,假设某个结构体中是不包含指针成员的,那么对该结构体成员进行垃圾回收时,其实是不必要递归地标记结构体的成员的。
但是由于没有类型信息,我们并不知道这个结构体成员不包含指针,因此我们只能对结构体的每个字节递归地标记下去,这显然会浪费很多时间。这个例子说明精确的垃圾回收可以减少不必要的扫描,提高标记过程的速度。
再看另一个例子,假设堆中有一个 long 的变量,它的值是 8860225560。但是我们不知道它的类型是 long,所以在进行垃圾回收时会把个当作指针处理,这个指针引用到了 0x2101c5018 位置。
假设 0x2101c5018 碰巧有某个对象,那么这个对象就无法被释放了,即使实际上已经没任何地方使用它。这个例子说明,保守的垃圾回收某些情况下会出现垃圾无法被回收。虽然不会造成大的问题,但总是让人很不爽,都是没有类型信息惹的祸。
现在好了,Go 在 1.1 版本中开始支持精确的垃圾回收。精确的垃圾回收首先需要的就是类型信息,上一节中讲过 MSpan 结构体,类型信息是存储在 MSpan 中的。从一个地址计算它所属的 MSpan,公式如下:
页号 = (地址 - mheap.arena_start) >> 页大小
MSpan = mheap->map[页号]接下来通过 MSpan->type 可以得到分配块的类型。这是一个 MType 的结构体:
struct MTypes
{
byte compression; // one of MTypes_*
bool sysalloc; // whether (void*)data is from runtime·SysAlloc uintptr data;
};MTypes 描述 MSpan 里分配的块的类型,其中 compression 域描述数据的布局。它的取值为 MTypes_Empty,MTypes_Single,MTypes_Words,MTypes_Bytes 四个中的一种。
MTypes_Empty:
所有的块都是 free 的,或者这个分配块的类型信息不可用。这种情况下 data 域是无意义的。
MTypes_Single:
这个 MSpan 只包含一个块,data 域存放类型信息,sysalloc 域无意义
MTypes_Words:
这个 MSpan 包含多个块(块的种类多于 7)。这时 data 指向一个数组[NumBlocks]uintptr,,数组里每个元索存放相应块的类型信息
MTypes_Bytes:
这个MSpan中包含最多7种不同类型的块。这时data域指下面这个结构体
struct {
type [8]uintptr // type[0] is always 0
index [NumBlocks]byte
}第 i 个块的类型是 data.type[data.index[i]]
表面上看 MTypes_Bytes 好像最复杂,其实这里的复杂程度是 MTypes_Empty 小于 MTypes_Single 小于 MTypes_Bytes 小于 MTypes_Words 的。MTypes_Bytes 只不过为了做优化而显得很复杂。
上一节中说过,每一块 MSpan 中存放的块的大小都是一样的,不过它们的类型不一定相同。如果没有使用,那么这个 MSpan 的类型就是 MTypes_Empty。如果存一个很大块,大于这个 MSpan 大小的一半,因此存不了其它东西了,那么这个 MSpan的类型是 MTypes_Single。
假设存了多种块,每一块用一个指针,本来可以直接用 MTypes_Words 存的。但是当类型不多时,可以把这些类型的指针集中起来放在数组中,然后存储数组索引。这是一个小的优化,可以节省内存空间。
得到的类型信息最终是什么样子的呢?其实是一个这样的结构体:
struct Type
{
uintptr size;
uint32 hash;
uint8 _unused;
uint8 align;
uint8 fieldAlign;
uint8 kind;
Alg *alg;
void *gc;
String *string;
UncommonType *x;
Type *ptrto;
};不同类型的类型信息结构体略有不同,这个是通用的部分。可以看到这个结构体中有一个 gc 域,精确的垃圾回收就是利用类型信息中这个 gc 域实现的。
从 gc 出去其实是一段指令码,是对这种类型的数据进行垃圾回收的指令,Go 中用一个状态机来执行垃圾回收指令码。大致的框架是类似下面这样子:
for(;;) {
switch(pc[0]) {
case GC_PTR:
break;
case GC_SLICE:
break;
case GC_APTR:
break;
case GC_STRING:
continue;
case GC_EFACE:
if(eface->type == nil)
continue;
break;
case GC_IFACE:
break;
case GC_DEFAULT_PTR:
while(stack_top.b <= end_b){
obj = *(byte**)stack_top.b;
stack_top.b += PtrSize;
if(obj >= arena_start && obj < arena_used) {
*ptrbufpos++ = (PtrTarget){obj, 0};
if(ptrbufpos == ptrbuf_end)
flushptrbuf(ptrbuf, &ptrbufpos, &wp, &wbuf, &nobj);
}
}
case GC_ARRAY_START:
continue;
case GC_ARRAY_NEXT:
continue;
case GC_CALL:
continue;
case GC_MAP_PTR:
continue;
case GC_MAP_NEXT:
continue;
case GC_REGION:
continue;
case GC_CHAN_PTR:
continue;
case GC_CHAN:
continue;
default:
runtime·throw("scanblock: invalid GC instruction");
return;
}
}Go语言使用标记清扫的垃圾回收算法,标记位图是非侵入式的,内存布局设计得比较巧妙。并且当前版本的 Go实现了精确的垃圾回收。在精确的垃圾回收中,通过定位对象的类型信息,得到该类型中的垃圾回收的指令码,通过一个状态机解释这段指令码来执行特定类型的垃圾回收工作。
对于堆中任意地址的对象,找到它的类型信息过程为,先通过它在的内存页找到它所属的 MSpan,然后通过 MSpan 中的类型信息找到它的类型信息。
目前 Go 中垃圾回收的核心函数是 scanblock,源代码在文件 runtime/mgc0.c 中。这个函数非常难读,单个函数写了足足 500 多行。
上面有两个大的循环,外层循环作用是扫描整个内存块区域,将类型信息提取出来,得到其中的 gc 域。内层的大循环是实现一个状态机,解析执行类型信息中 gc 域的指令码。
先说说上一节留的疑问吧。MType 中的数据其实是类型信息,但它是用 uintptr 表示,而不是 Type 结构体的指针,这是一个优化的小技巧。由于内存分配是机器字节对齐的,所以地址就只用到了高位,低位是用不到的。
于是低位可以利用起来存储一些额外的信息。这里的 uintptr 中高位存放的是 Type 结构体的指针,低位用来存放类型。通过
t = (Type*)(type & ~(uintptr)(PtrSize-1));就可以从 uintptr 得到 Type 结构体指针,而通过
type & (PtrSize-1)就可以得到类型。这里的类型有 TypeInfo_SingleObject,TypeInfo_Array,TypeInfo_Map,TypeInfo_Chan 几种。
基本的标记过程
从最简单的开始看,基本的标记过程,有一个不带任何优化的标记的实现,对应于函数 debug_scanblock。
debug_scanblock 函数是递归实现的,单线程的,更简单更慢的 scanblock 版本。该函数接收的参数分别是一个指针表示要扫描的地址,以及字节数。
首先要将传入的地址,按机器字节大小对齐。然后对待扫描区域的每个地址:
这个递归版本的标记算法还是很容易理解的。其中涉及的细节在上节中已经说过了,比如任意给定一个地址,找到它的标记位信息。很明显这里仅仅使用了一个无指针位,并没有精确的垃圾回收。
并行的垃圾回收
Go 在这个版本中不仅实现了精确的垃圾回收,而且实现了并行的垃圾回收。标记算法本质上就是一个树的遍历过程,上面实现的是一个递归版本。
并行的垃圾回收需要做的第一步,就是先将算法做成非递归的。非递归版本的树的遍历需要用到一个队列。树的非递归遍历的伪代码大致是:
根结点进队
while(队列不空){
出队
访问
将子结点进队
}第二步是使上面的代码能够并行地工作,显然这时是需要一个线程安全的队列的。假设有这样一个队列,那么上面代码就能够工作了。但是,如果不加任何优化,这里的队列的并行访问非常地频繁,对这个队列加锁代价会非常高,即使是使用 CAS 操作也会大大降低效率。
所以,第三步要做的就是优化上面队列的数据结构。事实上,Go 中并没有使用这样一个队列,为了优化,它通过三个数据结构共同来完成这个队列的功能,这三个数据结构分别是 PtrTarget 数组,Workbuf,lfstack。
先说 Workbuf 吧。听名字就知道,这个结构体的意思是工作缓冲区,里面存放的是一个数组,数组中的每个元素都是一个待处理的结点,也就是一个 Obj 指针。这个对象本身是已经标记了的,这个对象直接或间接引用到的对象,都是应该被标记的,它们不会被当作垃圾回收掉。Workbuf 是比较大的,一般是 N 个内存页的大小(目前是 2 页,也就是 8K)。
PtrTarget 数组也是一个缓冲区,相当于一个 intermediate buffer,跟 Workbuf 有一点点的区别。
垃圾回收过程中,会有一个从 PtrTarget 数组冲刷到 Workbuf 缓冲区的过程。对应于源代码中的 flushptrbuf 函数,这个函数作用就是对 PtrTaget 数组中的所有元素,如果该地址是 mark 了的,则将它移到 Workbuf 中。
标记过程形成了一个环,在环的一边,对 Workbuf 中的对象,会将它们可能引用的区域全部放到 PtrTarget 中记录下来。在环的另一边,又会将 PtrTarget 中确定需要标记的地址刷到 Workbuf 中。这个过程一轮一轮地进行,推动非递归版本的树的遍历过程,也就是前面伪代码中的出队,访问,子结点进队的过程。
另一个数据结构是 lfstack,这个名字的意思是 lock free 栈。其实它是被用作了一个无锁的链表,链表结点是以 Workbuf 为单位的。并行垃圾回收中,多条线程会从这个链表中取数据,每次以一个 Workbuf 为工作单位。
同时,标记的过程中也会产生 Workbuf 结点放到链中。lfstack 保证了对这个链的并发访问的安全性。由于现在链表结点是以 Workbuf 为单位的,所以保证整体的性能,lfstack 的底层代码是用 CAS 操作实现的。
经过第三步中数据结构上的拆解,整个并行垃圾回收的架构已经呼之欲出了,这就是标记扫描的核心函数 scanblock。这个函数是在多线程下并行安全的。
那么,最后一步,多线程并行。整个的 gc 是以 runtime.gc 函数为入口的,它实际调用的是 gc。进入 gc 函数后会先 stoptheworld,接着添加标记的 root 区域。然后会设置 markroot 和 sweepspan 的并行任务。运行 mark 的任务,扫描块,运行 sweep 的任务,最后 starttheworld 并切换出去。
有一个 ParFor 的数据结构。在 gc 函数中调用了
runtime·parforsetup(work.markfor, work.nproc, work.nroot, nil, false, markroot);
runtime·parforsetup(work.sweepfor, work.nproc, runtime·mheap->nspan, nil, true, sweepspan);是设置好回调函数让线程去执行 markroot 和 sweepspan 函数。垃圾回收时会 stoptheworld,其它 goroutine 会对发起 stoptheworld 做出响应,调用 runtime.gchelper,这个函数会调用 scanblock 帮助标记过程。也会并行地做 markroot 和 sweepspan 的过程。
void
runtime·gchelper(void)
{
gchelperstart();
// parallel mark for over gc roots runtime·parfordo(work.markfor);
// help other threads scan secondary blocks scanblock(nil, nil, 0, true);
if(DebugMark) {
// wait while the main thread executes mark(debug_scanblock)
while(runtime·atomicload(&work.debugmarkdone) == 0)
runtime·usleep(10);
}
runtime·parfordo(work.sweepfor);
bufferList[m->helpgc].busy = 0;
if(runtime·xadd(&work.ndone, +1) == work.nproc-1)
runtime·notewakeup(&work.alldone);
}其中并行时也有实现工作流窃取的概念,多个 worker 同时去工作缓存中取数据出来处理,如果自己的任务做完了,就会从其它的任务中“偷”一些过来执行。
垃圾回收的时机
垃圾回收的触发是由一个 gcpercent 的变量控制的,当新分配的内存占已在使用中的内存的比例超过 gcprecent 时就会触发。
比如,gcpercent=100,当前使用了 4M 的内存,那么当内存分配到达 8M 时就会再次 gc。如果回收完毕后,内存的使用量为 5M,那么下次回收的时机则是内存分配达到 10M 的时候。也就是说,并不是内存分配越多,垃圾回收频率越高,这个算法使得垃圾回收的频率比较稳定,适合应用的场景。
gcpercent 的值是通过环境变量 GOGC 获取的,如果不设置这个环境变量,默认值是 100。如果将它设置成 off,则是关闭垃圾回收。
Go语言中提供了 MD5、SHA-1 等几种哈希函数,下面我们用例子做一个介绍,代码如下所示。
package main
import(
"fmt"
"crypto/sha1"
"crypto/md5"
)
func main(){
TestString:="Hi,pandaman!"
Md5Inst:=md5.New()
Md5Inst.Write([]byte(TestString))
Result:=Md5Inst.Sum([]byte(""))
fmt.Printf("%x\n\n",Result)
Sha1Inst:=sha1.New()
Sha1Inst.Write([]byte(TestString))
Result=Sha1Inst.Sum([]byte(""))
fmt.Printf("%x\n\n",Result)
}这个程序的执行结果为:
$ go run hash1.go
b08dad36bde5f406bdcfb32bfcadbb6b
00aa75c24404f4c81583b99b50534879adc3985d再举一个例子,对文件内容计算 SHA1,具体代码如下所示。
package main
import (
"io"
"fmt"
"os"
"crypto/md5"
"crypto/sha1"
)
func main() {
TestFile := "123.txt"
infile, inerr := os.Open(TestFile)
if inerr == nil {
md5h := md5.New()
io.Copy(md5h, infile)
fmt.Printf("%x %s\n",md5h.Sum([]byte("")), TestFile)
sha1h := sha1.New()
io.Copy(sha1h, infile)
fmt.Printf("%x %s\n",sha1h.Sum([]byte("")), TestFile)
} else {
fmt.Println(inerr)
os.Exit(1)
}
}有时我们需要能够?成类似 MySQL 自增 ID 这样不断增大,同时又不会重复的 id。以支持业务中的?并发场景。比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒 10w+。明星出轨时,会有大量热情的粉丝发微博以表心意,同样会在短时间内产生大量的消息。
在插入数据库之前,我们需要给这些消息、订单先打上一个 ID,然后再插?到我们的数据库。对这个 id 的要求是希望其中能带有一些时间信息,这样即使我们后端的系统对消息进行了分库分表,也能够以时间顺序对这些消息进?排序。
Twitter 的 snowflake 算法是这种场景下的一个典型解法。先来看看 snowflake 是怎么回事,如下图所示:
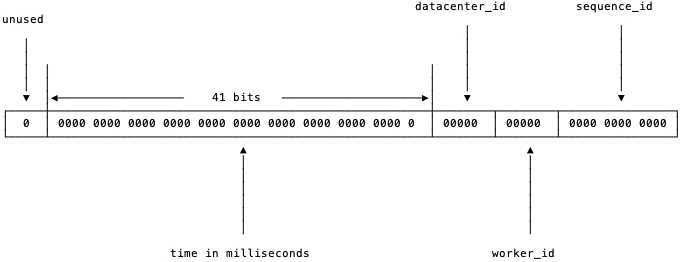
图:snowflake 中的比特位分布
?先确定我们的数值是 64 位,int64 类型,被划分为四部分,不含开头的第一个 bit,因为这个 bit 是符号位。用 41 位来表示收到请求时的时间戳,单位为毫秒,然后五位来表示数据中心的 id,然后再五位来表示机器的实例 id,最后是 12 位的循环自增 id(到达 1111,1111,1111 后会归 0)。
这样的机制可以?持我们在同一台机器上,同一毫秒内产? 2 ^ 12 = 4096 条消息。一秒共 409.6 万条消息。从值域上来讲完全够?了。
数据中心加上实例 id 共有 10 位,可以?持我们每数据中心部署 32 台机器,所有数据中心共 1024 台实例。
表示 timestamp 的 41 位,可以?持我们使用 69 年。当然,我们的时间毫秒计数不会真的从 1970 年开始记,那样我们的系统跑到 2039/9/7 23:47:35 就不能用了,所以这里的 timestamp 实际上只是相对于某个时间的增量,比如我们的系统上线是 2018-08-01,那么我们可以把这个 timestamp 当作是从 2018-08-01 00:00:00.000 的偏移量。
worker_id 分配
timestamp,datacenter_id,worker_id 和 sequence_id 这四个字段中,timestamp 和 sequence_id 是由程序在运?期?成的。但 datacenter_id 和 worker_id 需要我们在部署阶段就能够获取得到,并且一旦程序启动之后,就是不可更改的了(想想,如果可以随意更改,可能被不慎修改,造成最终生成的 id 有冲突)。
一般不同数据中?的机器,会提供对应的获取数据中心 id 的 API,所以 datacenter_id 我们可以在部署阶段轻松地获取到。而 worker_id 是我们逻辑上给机器分配的一个 id,这个要怎么办呢?比较简单的想法是由能够提供这种自增 id 功能的工具来支持,比如 MySQL:
mysql> insert into a (ip) values("10.1.2.101");
Query OK, 1 row affected (0.00 sec)
mysql> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 2 |
+------------------+
1 row in set (0.00 sec)从 MySQL 中获取到 worker_id 之后,就把这个 worker_id 直接持久化到本地,以避免每次上线时都需要获取新的 worker_id。让单实例的 worker_id 可以始终保持不变。
当然,使用 MySQL 相当于给我们简单的 id 生成服务增加了一个外部依赖。依赖越多,我们的服务的可运维性就越差。
考虑到集群中即使有单个 id 生成服务的实例挂了,也就是损失一段时间的一部分 id,所以我们也可以更简单暴力一些,把 worker_id 直接写在 worker 的配置中,上线时,由部署脚本完成 worker_id 字段替换。
标准 snowflake 实现
github.com/bwmarrin/snowflake 是一个相当轻量化的 snowflake 的 Go 实现。其文档对各位使用的定义如下图所示。

图:snowflake库
和标准的 snowflake 完全一致。使用上比较简单:
package main
import (
"fmt"
"os"
"github.com/bwmarrin/snowflake"
)
func main() {
n, err := snowflake.NewNode(1)
if err != nil {
println(err)
os.Exit(1)
}
for i := 0; i < 3; i++ {
id := n.Generate()
fmt.Println("id", id)
fmt.Println(
"node: ", id.Node(),
"step: ", id.Step(),
"time: ", id.Time(),
"\n",
)
}
}当然,这个库也给我们留好了定制的后路,其中预留了一些可定制字段:
// Epoch is set to the twitter snowflake epoch of Nov 04 2010 01:42:54 UTC
// You may customize this to set a different epoch for your application.
Epoch int64 = 1288834974657
// Number of bits to use for Node
// Remember, you have a total 22 bits to share between Node/Step
NodeBits uint8 = 10
// Number of bits to use for Step
// Remember, you have a total 22 bits to share between Node/Step
StepBits uint8 = 12Epoch 就是本节开头讲的起始时间,NodeBits 指的是机器编号的位?,StepBits 指的是自增序列的位?。
sonyflake
sonyflake 是 Sony 公司的一个开源项目,基本思路和 snowflake 差不多,不过位分配上稍有不同,如下图所示:

图:sonyflake
这?的时间只用了 39 个 bit,但时间的单位变成了 10ms,所以理论上比 41 位表示的时间还要久(174 年)。
Sequence ID 和之前的定义一致,Machine ID 其实就是节点 id。sonyflake 与众不同的地方在于其在启动阶段的配置参数:
func NewSonyflake(st Settings) *SonyflakeSettings 数据结构如下:
type Settings struct {
StartTime time.Time
MachineID func() (uint16, error)
CheckMachineID func(uint16) bool
}StartTime 选项和我们之前的 Epoch 差不多,如果不设置的话,默认是从 2014-09-01 00:00:00 +0000 UTC 开始。
MachineID 可以由用户自定义的函数,如果用户不定义的话,会默认将本机 IP 的低 16 位作为 machineid。
CheckMachineID 是由用户提供的检查 MachineID 是否冲突的函数。这里的设计还是比较巧秒的,如果有另外的中心化存储并支持检查重复的存储,那我们就可以按照自己的想法随意定制这个检查 MachineID 是否冲突的逻辑。如果公司有现成的 Redis 集群,那么我们可以很轻松地用 Redis 的集合类型来检查冲突。
redis 127.0.0.1:6379> SADD base64_encoding_of_last16bits MzI0Mgo=
(integer) 1
redis 127.0.0.1:6379> SADD base64_encoding_of_last16bits MzI0Mgo=
(integer) 0使用起来也比较简单,有一些逻辑简单的函数就略去实现了:
package main
import (
"fmt"
"os"
"time"
"github.com/sony/sonyflake"
)
func getMachineID() (uint16, error) {
var machineID uint16
var err error
machineID = readMachineIDFromLocalFile()
if machineID == 0 {
machineID, err = generateMachineID()
if err != nil {
return 0, err
}
}
return machineID, nil
}
func checkMachineID(machineID uint16) bool {
saddResult, err := saddMachineIDToRedisSet()
if err != nil || saddResult == 0 {
return true
}
err := saveMachineIDToLocalFile(machineID)
if err != nil {
return true
}
return false
}
func main() {
t, _ := time.Parse("2006-01-02", "2018-01-01")
settings := sonyflake.Settings{
StartTime: t,
MachineID: getMachineID,
CheckMachineID: checkMachineID,
}
sf := sonyflake.NewSonyflake(settings)
id, err := sf.NextID()
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(id)
}通过前面的学习相信大家对Go语言已经有了一定的了解,平时我们都是在本地进行开发调试访问的。那要怎么打包到服务器上呢?下面通过一个简单的实例来给大家介绍一下如何把我们写好的GO语言程序发布到服务 Linux 服务器上。
下面所示的是我们在Window下开发的代码:
package main
import (
"fmt"
"log"
"net/http"
)
func sayHello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w,"您看到我了")
}
func main() {
http.HandleFunc("/",sayHello)
log.Println("启动了")
err := http.ListenAndServe(":9000",nil)
if err != nil{
log.Fatal("List 9000")
}
}代码已经写好了,现在需要编译了,由于是 window 环境编译到 linux 下运行,所有涉及到跨平台编译。
编译代码命令如下所示:
set GOARCH=amd64 //设置目标可执行程序操作系统构架,包括 386,amd64,arm
set GOOS=linux //设置可执行程序运行操作系统,支持 darwin,freebsd,linux,windows
go build ./main.go //打包注意:使用 Window 10 系统的小伙伴必须用 cmd 工具执行上述命令,不能使用 powershell。
OK,编译完成后会生成一个 main 可执行文件,没有后缀,这时只需要把这个文件上传到你的虚拟机,直接运行就好了。

运行后如果出现上图的效果,就说明已经运行起来了。这时打开你的浏览器访问服务器的 IP:9000 就能看到如下图的内容了
好啦!就这么简单,不需要任何语言环境,像 java 程序需要在服务器安装 java,php 需要安装 Apache,PHP 等运行环境,go 统统不需要,只需要一个 linux 系统就好,扔上去就可以了。
密码学里目前有两大经典算法,一个是对称加解密,其代表是 AES 加解密;另一个是非对加解密,其代表是 RSA 加解密。这里就以这两个经典算法为例,简单列下其在Go语言里实现的代码。
AES 加解密
AES 加密又分为 ECB、CBC、CFB、OFB 等几种,这里只列两种吧。
1) CBC 加解密
package main
import(
"bytes"
"crypto/aes"
"fmt"
"crypto/cipher"
"encoding/base64"
)
func main() {
orig := "hello world"
//key := "123456781234567812345678"
key := "9871267812345mn812345xyz"
fmt.Println("原文:", orig)
encryptCode := AesEncrypt(orig, key)
fmt.Println("密文:" , encryptCode)
decryptCode := AesDecrypt(encryptCode, key)
fmt.Println("解密结果:", decryptCode)
}
func AesEncrypt(orig string, key string) string {
// 转成字节数组
origData := []byte(orig)
k := []byte(key)
// 分组秘钥
block, _ := aes.NewCipher(k)
// 获取秘钥块的长度
blockSize := block.BlockSize()
// 补全码
origData = PKCS7Padding(origData, blockSize)
// 加密模式
blockMode := cipher.NewCBCEncrypter(block, k[:blockSize])
// 创建数组
cryted := make([]byte, len(origData))
// 加密
blockMode.CryptBlocks(cryted, origData)
return base64.StdEncoding.EncodeToString(cryted)
}
func AesDecrypt(cryted string, key string) string {
// 转成字节数组
crytedByte, _ := base64.StdEncoding.DecodeString(cryted)
k := []byte(key)
// 分组秘钥
block, _ := aes.NewCipher(k)
// 获取秘钥块的长度
blockSize := block.BlockSize()
// 加密模式
blockMode := cipher.NewCBCDecrypter(block, k[:blockSize])
// 创建数组
orig := make([]byte, len(crytedByte))
// 解密
blockMode.CryptBlocks(orig, crytedByte)
// 去补全码
orig = PKCS7UnPadding(orig)
return string(orig)
}
//补码
func PKCS7Padding(ciphertext []byte, blocksize int) []byte {
padding := blocksize - len(ciphertext)%blocksize
padtext := bytes.Repeat([]byte{byte(padding)}, padding)
return append(ciphertext, padtext...)
}
//去码
func PKCS7UnPadding(origData []byte) []byte {
length := len(origData)
unpadding := int(origData[length-1])
return origData[:(length - unpadding)]
}其运行结果如下:
D:\code>go run main.go
原文: hello world
密文: v3/NfSN7XwqXu2gC08+3QA==
解密结果: hello world2) CFB 加解密
代码如下:
package main
import (
"crypto/aes"
"crypto/cipher"
"fmt"
"os"
)
var commonIV = []byte{0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f}
func main() {
//需要去加密的字符串
plaintext := []byte("My name is Astaxie")
//如果传入加密串的话,plaint就是传入的字符串
if len(os.Args) > 1 {
plaintext = []byte(os.Args[1])
}
//aes的加密字符串
key_text := "astaxie12798akljzmknm.ahkjkljl;k"
if len(os.Args) > 2 {
key_text = os.Args[2]
}
fmt.Println(len(key_text))
// 创建加密算法aes
c, err := aes.NewCipher([]byte(key_text))
if err != nil {
fmt.Printf("Error: NewCipher(%d bytes) = %s", len(key_text), err)
os.Exit(-1)
}
//加密字符串
cfb := cipher.NewCFBEncrypter(c, commonIV)
ciphertext := make([]byte, len(plaintext))
cfb.XORKeyStream(ciphertext, plaintext)
fmt.Printf("%s=>%x\n", plaintext, ciphertext)
// 解密字符串
cfbdec := cipher.NewCFBDecrypter(c, commonIV)
plaintextCopy := make([]byte, len(plaintext))
cfbdec.XORKeyStream(plaintextCopy, ciphertext)
fmt.Printf("%x=>%s\n", ciphertext, plaintextCopy)
}其运行结果如下:
D:\code>go run main.go
32
My name is Astaxie=>5072eadc20720cdb321b7c62947982d8227d
5072eadc20720cdb321b7c62947982d8227d=>My name is Astaxie上面的代码如果细看和分解成加解密函数,发现是有问题的,这里再列个官方的示例:
package main
import (
"crypto/aes"
"crypto/cipher"
"crypto/rand"
"encoding/hex"
"fmt"
"io"
)
func ExampleNewCFBDecrypter() {
key, _ := hex.DecodeString("6368616e676520746869732070617373")
ciphertext, _ := hex.DecodeString("52869b03d72f01f4eccad3b3712e03f95caa4095d4269775a3cd6d9d52638b")
block, err := aes.NewCipher(key)
if err != nil {
panic(err)
}
if len(ciphertext) < aes.BlockSize {
panic("ciphertext too short")
}
iv := ciphertext[:aes.BlockSize]
ciphertext = ciphertext[aes.BlockSize:]
stream := cipher.NewCFBDecrypter(block, iv)
stream.XORKeyStream(ciphertext, ciphertext)
fmt.Printf("%s\n", ciphertext)
}
func ExampleNewCFBEncrypter() {
key, _ := hex.DecodeString("6368616e676520746869732070617373")
plaintext := []byte("c.biancheng.net")
block, err := aes.NewCipher(key)
if err != nil {
panic(err)
}
ciphertext := make([]byte, aes.BlockSize+len(plaintext))
iv := ciphertext[:aes.BlockSize]
if _, err := io.ReadFull(rand.Reader, iv); err != nil {
panic(err)
}
stream := cipher.NewCFBEncrypter(block, iv)
stream.XORKeyStream(ciphertext[aes.BlockSize:], plaintext)
fmt.Printf("%x\n", ciphertext)
}
func main() {
ExampleNewCFBDecrypter()
ExampleNewCFBEncrypter()
}RSA 加解密
AES 一般用于加解密文,而 RSA 算法一算用来加解密密码。这里列举一个代码示例,如下:
package main
import (
"crypto/rand"
"crypto/rsa"
"crypto/x509"
"encoding/base64"
"encoding/pem"
"errors"
"fmt"
)
// 可通过openssl产生
//openssl genrsa -out rsa_private_key.pem 1024
var privateKey = []byte(`
-----BEGIN RSA PRIVATE KEY-----
MIICXQIBAAKBgQDfw1/P15GQzGGYvNwVmXIGGxea8Pb2wJcF7ZW7tmFdLSjOItn9
kvUsbQgS5yxx+f2sAv1ocxbPTsFdRc6yUTJdeQolDOkEzNP0B8XKm+Lxy4giwwR5
LJQTANkqe4w/d9u129bRhTu/SUzSUIr65zZ/s6TUGQD6QzKY1Y8xS+FoQQIDAQAB
AoGAbSNg7wHomORm0dWDzvEpwTqjl8nh2tZyksyf1I+PC6BEH8613k04UfPYFUg1
F2rUaOfr7s6q+BwxaqPtz+NPUotMjeVrEmmYM4rrYkrnd0lRiAxmkQUBlLrCBiF
u+bluDkHXF7+TUfJm4AZAvbtR2wO5DUAOZ244FfJueYyZHECQQD+V5/WrgKkBlYy
XhioQBXff7TLCrmMlUziJcQ295kIn8n1GaKzunJkhreoMbiRe0hpIIgPYb9E57tT
/mP/MoYtAkEA4Ti6XiOXgxzV5gcB+fhJyb8PJCVkgP2wg0OQp2DKPp+5xsmRuUXv
oExv92jv6X65x631VGjDmfJNb99wq5QJBAMSHUKrBqqizfMdOjh7z5fLc6wY5
M0a91rqoFAWlLErNrXAGbwIRf3LN5fvA76z6ZelViczY6sKDjOxKFVqL38ECQG0S
pxdOT2M9BM45GJjxyPJ+qBuOTGU391Mq1pRpCKlZe4QtPHioyTGAAMd4Z/FX2MKb
in48c0UX5t3VjPsmY0CQQCc1jmEoB83JmTHYByvDpc8kzsD8+GmiPVrausrjj4p
y2DQpGmUic2zqCxl6qXMpBGtFEhrUbKhOiVOJbRNGvWW
-----END RSA PRIVATE KEY-----
`)
//openssl
//openssl rsa -in rsa_private_key.pem -pubout -out rsa_public_key.pem
var publicKey = []byte(`
-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDfw1/P15GQzGGYvNwVmXIGGxea
Pb2wJcF7ZW7tmFdLSjOItn9kvUsbQgS5yxx+f2sAv1ocxbPTsFdRc6yUTJdeQol
DOkEzNP0B8XKm+Lxy4giwwR5LJQTANkqe4w/d9u129bRhTu/SUzSUIr65zZ/s6TU
GQD6QzKY1Y8xS+FoQQIDAQAB
-----END PUBLIC KEY-----
`)
// 加密
func RsaEncrypt(origData []byte) ([]byte, error) {
//解密pem格式的公钥
block, _ := pem.Decode(publicKey)
if block == nil {
return nil, errors.New("public key error")
}
// 解析公钥
pubInterface, err := x509.ParsePKIXPublicKey(block.Bytes)
if err != nil {
return nil, err
}
// 类型断言
pub := pubInterface.(*rsa.PublicKey)
//加密
return rsa.EncryptPKCS1v15(rand.Reader, pub, origData)
}
// 解密
func RsaDecrypt(ciphertext []byte) ([]byte, error) {
//解密
block, _ := pem.Decode(privateKey)
if block == nil {
return nil, errors.New("private key error!")
}
//解析PKCS1格式的私钥
priv, err := x509.ParsePKCS1PrivateKey(block.Bytes)
if err != nil {
return nil, err
}
// 解密
return rsa.DecryptPKCS1v15(rand.Reader, priv, ciphertext)
}
func main() {
data, _ := RsaEncrypt([]byte("hello world"))
fmt.Println(base64.StdEncoding.EncodeToString(data))
origData, _ := RsaDecrypt(data)
fmt.Println(string(origData))
}运行结果如下:
D:\code>go run main.go
ocYqyhRtngT/G9TteTHxAmg9E3KNuw0zskKXcQbxeWEwFoHzGGIrfkDokq+SMvYeQjVCWTADBL3zzlelBBaZIVaJ11PndffC+
2AlDVhLrvRqy5MeEYFafH40ZH1qUptt/UiY4imgaQc1dhcQol0+4dTfGmgN8CMAi3od7AU+/RM=
hello world标签:layer 不可用 call() sig 请求 要求 tween %s was
原文地址:https://www.cnblogs.com/kershaw/p/12077199.html