标签:str rip 设置 网页 link 字符串匹配算法 计数器 文本 大型
麻雀虽小,五脏俱全,跟大型搜索引擎相比,实现一个小型搜索引擎所用到的理论基础是相通的。
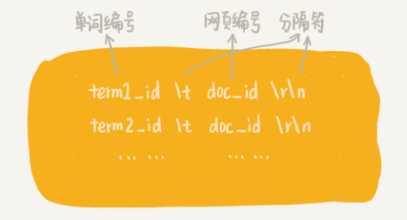
四个部分:搜集、分析、索引、查询
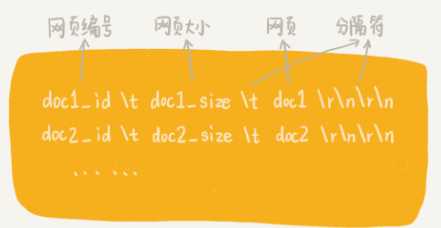
设置每个文件的大小不能超过一定的值(比如 1GB)
数据结构与算法简记--剖析搜索引擎背后的经典数据结构和算法
原文地址:https://www.cnblogs.com/wod-Y/p/12205156.html