标签:查询 xpath 修改 获取 点击 左右 领域 时间 pat
遇到的问题
- 导师给了个科学网的网址让我自己查基金,查完告诉他结果,可是! 在科学网查询的时候,发现只要同一IP短时间内访问 10次 左右,网页就会说你 访问太频繁 了...然后 等个10分钟左右才能重新访问
- 在科学网碰壁后,我先是查了下有没有别的基金查询网站,然后发现在一众网站中,还是科学网的信息更全面一点(nsfc,medsci,letpub等),然后就还是爬虫叭!!!
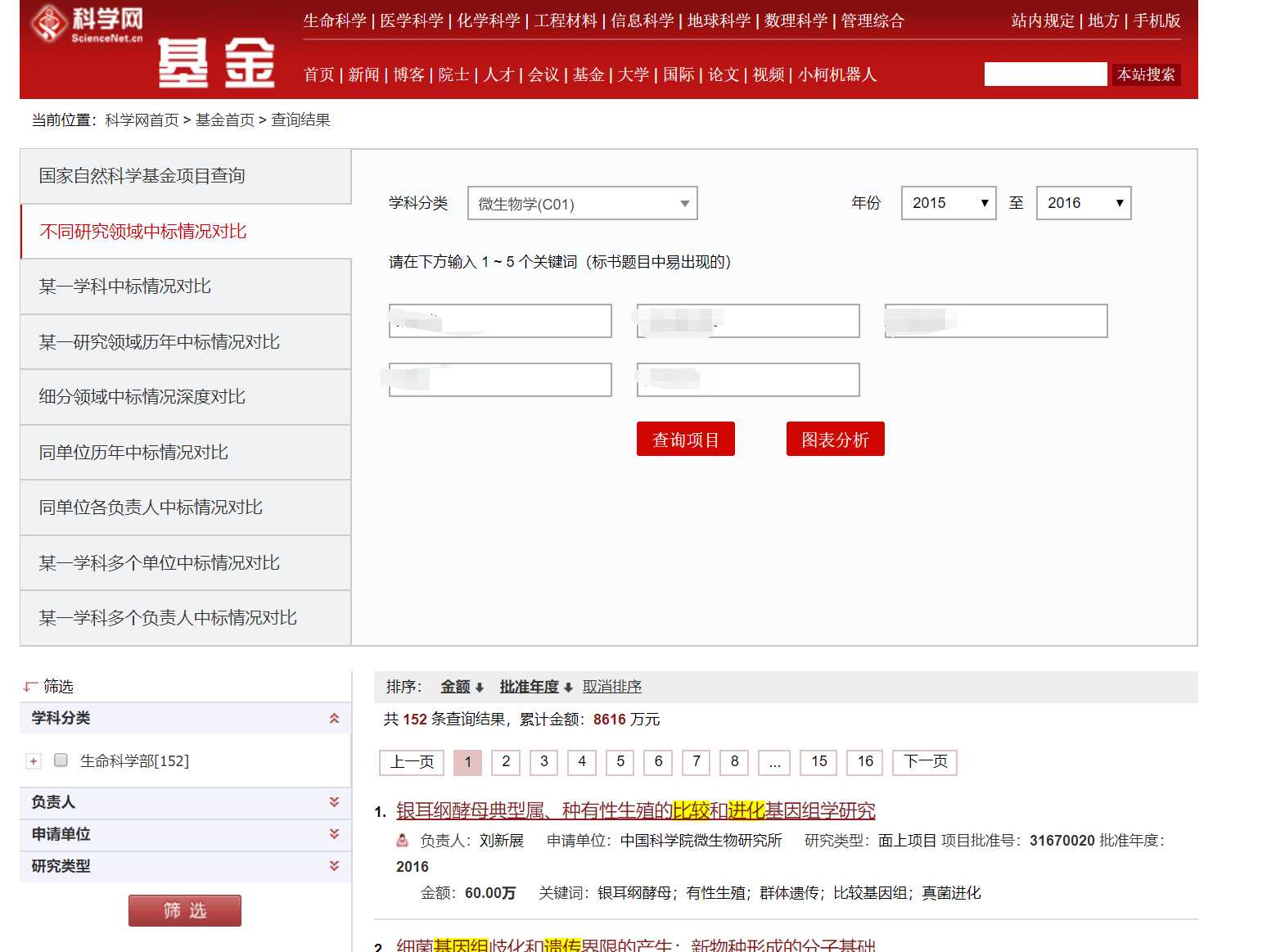
目标
要根据摘要来了解相关信息,那么发现在这个页面上是没有摘要的,只有点入某个标题后才能获取基金的摘要等详细信息
思路
- 网址的设置 (限制学科分类、限制年份、关键字)
- 目标元素的获取
- 循环的编写
先在科学网的基金页面填写好相关关键词,选好学科分类和年份后,点击“查询按钮”
然后将浏览器顶部的网址复制到vs code中,修改网址组成(主要是改年份和页数)
回到浏览器,观察目标元素的位置,xpath定位
再写个嵌套循环
(别忘了需要一定的等待时间)
OKKK!!!
标签:查询 xpath 修改 获取 点击 左右 领域 时间 pat
原文地址:https://www.cnblogs.com/TANGLi83/p/12404241.html